Threads
Threads can be considered lightweight processes that perform tasks in parallel with other threads. Each thread has its own instruction pointer, registers, and stack which allow for multi-tasking. However unlike processes, threads running inside a process share memory, file descriptors, and other things such as the UID. Because of this lack of isolation, using threads creates a high risk for race conditions. If threads are implemented carefully, they have several advantages over multi-processing: threads are created more quickly than processes because utilize the current process's address space, switching between threads is quicker for similar reasons, and communicating between threads is quick because of their shared memory.
System Calls for Threads
The syntax to create a new thread is:
int pthread_create(pthread_t *threadID, const pthread_attr_t *attr,
void *(*start_routine)(void *), void* arg);
This creates a thread with attributes attr and runs the function start_routine
with arguments arg. Upon completion, pthread_create() stores the thread ID in *thread.
The function pthread_join() is used to prevent race conditions by suspending execution until the thread designated by threadID terminates via pthread_exit().
int pthread_join(pthread_t threadID, void *retVal); void pthread_exit(void *retStatus);
On a sucessful join, the return value retVal is set to the value of retStatus.
Busy Wait vs Yielding
If a thread needs to wait for a device to be ready, a standard way is to insert a while loop that checks the status of the device.
while(device_is_busy) continue;
This example represents busy waiting (polling). The drawback polling is that the waiting thread hogs CPU that could be used for other threads. To fix this issue, threads can call the yield() function instead. This function gives up control CPU and allows another thread with high priority to run.
while(device is busy)
yield();
Cooperative Threading
Cooperative threading is a technique that allows threads to decide when to give up its CPU for other threads. This model can simplify scheduling and reduce the amount of race conditions that occur. To implement proper cooperative threading, threads need to voluntarily give up control of the CPU every once in a while by yielding or blocking. A disadvantage to cooperative threading is that one thread can be uncooperative and keep control of the CPU if it is designed incorrectly.
Preemptive Threading ns or ms?
Preemptive threading uses a timer interrupt at the hardware level and acts like an interrupt instruction. About every 10 ms, the CPU traps and inserts a yield() into the program automatically. The kernel saves and restores contexts, including threads. This approach is much simpler than cooperative but has a more costly overhead. Since the yield() function is now automatically inserted, it can cause unpredictability in the code. Some task that we expect to run next can randomly yield() and run much later, which may result in race conditions.
Notice that cooperative threading is more structured for single-core computers because it is faster and simpler. Preemptive threading is more structured for multi-core processors because of the processor's need for more parallelism and locking.
Scheduling Issues
Threads and processes must deal with scheduling to produce the correct results. Different policies and mechanisms are used by the scheduler to help coordinate the different processes and threads.
Scheduling Policies
Scheduling policies are algorithms that are implemented to coordinate threads or processes to execute tasks correctly and efficiently. The scheduler needs to be quick in order to create the illusion of seamless executions and to maximize the efficiency of the CPU. The scheduler should also limit its use of RAM in order to keep itself invisible to the user. Because the typical user prefers speed over efficiency, the contrainst on RAM usage is larger, which limits the capabilites of the scheduler to more simple algorithms.
Scheduling Metrics
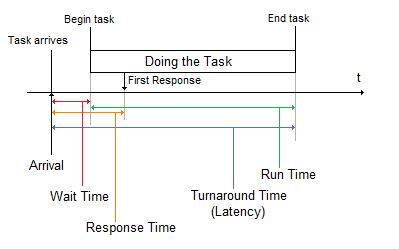
Scheduling metrics can be applied to processes in order to compare the performances of different scheduling policies.
Arrival Time: The time when a task arrives into the system.Wait Time: How long a process needs to wait for it to begin its execution.
Response Time: How long it takes to produce an output after its initial arrival.
Turnaround Time: The total time between its arrival and its completion. This time is also refered to as the latency.
Context-Switching Time: The time it takes to switch from one task to another. Scheduling policies that rotate often, such as Round Robin, will waste lots of time in this category. This switching time applies to switches in threads and in processes.
By averaging these times, we can find the strengths and weaknesses of different scheduling policies. The goal is to find a policy that minimizes the average turnaround time. A low turnaround time represents good throughput, the amount of work a computer can do in a given period of time, and utilization, the ratio of the actual amount of CPU being used over the total CPU that can be used. Average wait time can be used to measure the fairness of the scheduler. A good scheduler will have a low average wait time.
Source: Masaki Moritani (Fall 2010)