Notes of Lecture 3 (Jan 14, 2013) and related reading by Ao Zhang
Table of contents
- Techniques to improve the performance of very secure word counter(VSWC)
- Modularity
- Modularization in action
-
-
In an older computer, CPU SENDs a message through bus to READ a chunk of data from the disk. The disk transmits data through the bus to CPUs, then CPU transmits data to RAM. The following image shows how disk controller responds to the request.
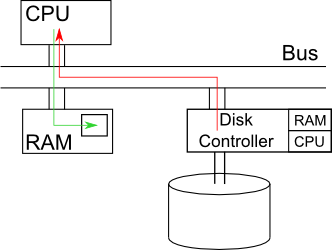
src: http://www.cs.ucla.edu/classes/fall10/cs111/srcibe/3a/
Better performance can be obtained with DMA. When a CPU SENDs a request to READ data, it includes the address of memory as part the request. Another CPU inside the disk controller then recognizes the request, and sends requested data directly to RAM. The process can be illustrated by
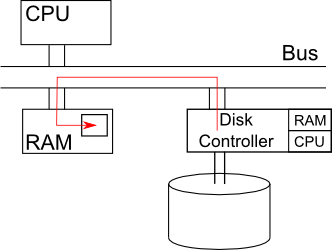
src: http://www.cs.ucla.edu/classes/fall10/cs111/srcibe/3a/
Two obvious benefits of using DMA are:
- DMA reduces the load of bus, as there is no need to transfer data twice.
- DMA reduces the workload of processor, as it does not need to retransmit data.
-
Suppose the program runs so slowly that CPU processing speed is the same as buffer reading speed. If the buffer size is kept unchanged (just enough as a process buffer), processing data can be illustrated below:
| data1 data2 data3
CPU | ==== ==== ====
| data1 data2 data3
I/O | ==== ==== ====
|
|
As I/O buffer is reading in data, the CPU keeps iterating to check if the buffer is ready--not doing something useful. Later, after the buffer read in all required data, the CPU begins processing, but then I/O device becomes idle. However, being idle is usually a waste!
One solution can be to double the size of buffer (as illustrated below). While the CPU is processing data1, I/O buffer reads data2. Ideally, when I/O devices finish reading data2, the CPU also finishes processing data1, and can immediately move on to data2 in I/O buffer. The previous process buffer (holding data1) then serves as the I/O buffer to read in data3
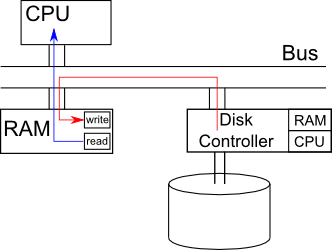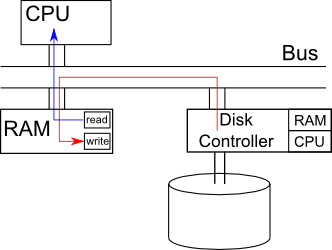
src: http://www.cs.ucla.edu/classes/fall10/cs111/scribe/3a/
|
The process can be illustrated below in terms of data flow.
| data1data2data3
CPU | |====|====|====
| data1data2data3
I/O | ====|====|====
|
|
With larger buffer size, the performance can be improved by two. However, there are some interesting assumptions worthy of consideration as well.
- If we triple the buffer size
- There is no performance improvement, as the extra buffer may not even be used given the same I/O speed.
- If CPU_time == 0.5 I/O_time
- Assuming I/O speed is unchanged, we increase only CPU speed by two. There can still be some improvement.
| data1data2data3
CPU | |== |== |==
| data1data2data3
I/O | ====|====|====
|
- If 0.5 CPU_time == I/O_time
- Assuming CPU speed in unchanged, we increase only I/O speed by two. There can still be some improvement.
| data1data2data3
CPU | |====|====|====
| data1data2data3
I/O | == |== |==
|
or if buffer size is unlimited, I/O keeps reading in data, then
| data1data2data3
CPU | |====|====|====
| d1|d2|d3
I/O | ==|==|==
|
-
Recall the read_sector() function:
1 void wait_for_ready ()
2 {
3 while (inb(0x1f7) & 0xc0 != 0x40)
4 continue;
5 }
6
7 void read_sector(int s, char* a)
8 {
9 wait_for_ready();
10 outb (0x1f2,1);
11 outb (0x1f3, s&0xff);
12 outb (0x1f4, (s>>8) & 0xff);
13 outb (0x1f5, (s>>16) & 0xff);
14 outb (0x1f6, (s>>24) & 0xff);
15 outb (0x1f4, 0x20);
16 wait_for_ready();
17 /* output the count to the screen */
18 insl (0x1f0, a, 128);
19 }
Note that there are multiple copies of this function in a machine.
- in BIOS (since we need BIOS to copy this function into RAM)
- in MBR (or in VBR)
- in the VSWC program
Though for a mini-program like this, memory space is not that important, but as a program scales up, cache is usually precious. One way to save cache is keeping only one copy by storing the function only in BIOS. This method worked (Microsoft once pressed Phoenix to add function inside BIOS) (ref: lecture).
However, one obvious problem with this design relates to the fact that BIOS is stored inside a read-only space in memory. On the one hand, since the function cannot be modified, it
- sets constraints on disk controller and OS (e.g.fixed sector size)
- assumes that every application and device reads section in the same way
- does not support new features (e.g.still fixed sector size)
On the other hand, developers should not always bother to write a particular version of read_sector(). As a solution, OS keeps a copy of the function.
-
-
-
/* @description: a function that calculates the factorial of n */
int fact (int n)
{
if (n==0) return 1;
else return n*fact(n-1);
}
By compiling the above code with "gcc -S fact.c" on a (x86) machine
Processor: 2x Intel(R) Pentium(R) CPU P6000 @ 1.87GHz
Operating System: Linux Mint 13 Maya
Default C Compiler: GNU C Compiler version 4.6.3 (Ubuntu/Linaro 4.6.3-1ubuntu5)
I obtained the following code (with modification) (the assembly code is different from that given in class)
fact:
.LFB0:
pushl %ebp //save old %ebp
movl %esp, %ebp //set new stack base pointer
subl $24, %esp //create a stack
cmpl $0, 8(%ebp) // if-else
jne .L2 // if not equal
movl $1, %eax // if (n==0) set %eax to 1
jmp .L3
.L2:
movl 8(%ebp), %eax
subl $1, %eax // n-1
movl %eax, (%esp) // prepare for argument
call fact // recursive call
imull 8(%ebp), %eax // n*fact(n-1)
.L3:
leave
ret // return %eax
And the resulting stack is shown below (stack grows downward)
|-----------------------------|+8
| argument n |
|-----------------------------|+4
| return address |
|-----------------------------|0<----%ebp
| |
|-----------------------------|
| ...... |
| |
| argument n-1 |
|-----------------------------|-24 <---%esp
| return address |
|-----------------------------|
|stack of next fact() instance|
|-----------------------------|
| ......... |
From this simple example, we have a feeling of caller-callee contract, as stated below:
- %ebp must be set to the return address
- -4(%ebp) must be the first argument, i.e. n
- %eax holds return value
- %esp == old %esp + 4 as %esp holds return value
- enough stack space must be reserved
- callee must set %ip (next instruction pointer) to return address and return
if the contract is violated, any bad thing can happen (e.g.stack overflow). Errors in this case can propagate easily from callee fact() to caller fact(), and even to caller of fact(). This is known as soft modularity.
-
Suppose the factorial function is made available on-line, and the result for each valid integer is made a page, accessed like this (factorial of "23"):
http://factorial.cs.ucla.edu/23
This time, it is harder for an error to propagate between modules, so it is a hard-modularity by definition.
Under this mechanism
- A client builds an argument message and sends it to a server.
- The server extracts arguments from the message, computes, builds a response message including the result, and sends back/responds.
- The client receives the message and extracts the result.
Advantages
- separate client&server geographically
To some extent it prevents both sides break down together. For example, an earthquake may hit client in Los Angeles, but the server remains contact in New York.
- no shared state
Client and server interacts with messages, thus an error can only propagate in one way. If the client and the server validate the message, they can control the way errors propagate.
- only well-defined messages are allowed
Many errors cannot propagate, such as stack corruption on the client.
- well-defined interface
It is convenient for developers, as they don't need to know the internal of client module if they are working on the server side, and vice versa.
Disadvantages/Cost
- equipment
Usually require one computer per side.
- performance
There is some overhead (e.g.sending request, acknowledge that request, transmission of packet), it is really inefficient if the function is small and simple, but works fine for relatively large function.

|