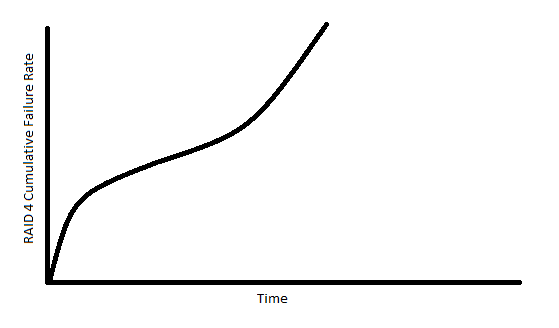
Suppose we have a client-server setup where the client sends requests to the server and recieves responses from the server. A possible plan of execution is to have the client send requests and wait for the server to respond before sending more requests. While this method works, it is slow and we would like to speed up the process.
Possible solutions:
We would like a NFS to act like a regular local file system.
Mount tableFrom the OS point of view we have a mount table that maps inodes in the local file system to inodes representing other file systems. Specifically, the mount table contains information about the device number of the parent file system, an inode in the parent file system, the device number of the child file system, and the inode into the child file system, among other things. Now we have a (device #, inoode) pair that uniquely identifies a file. To avoid problems with mounting file systems onto sensitive files, file system mounting is restricted to root in many operating systems.
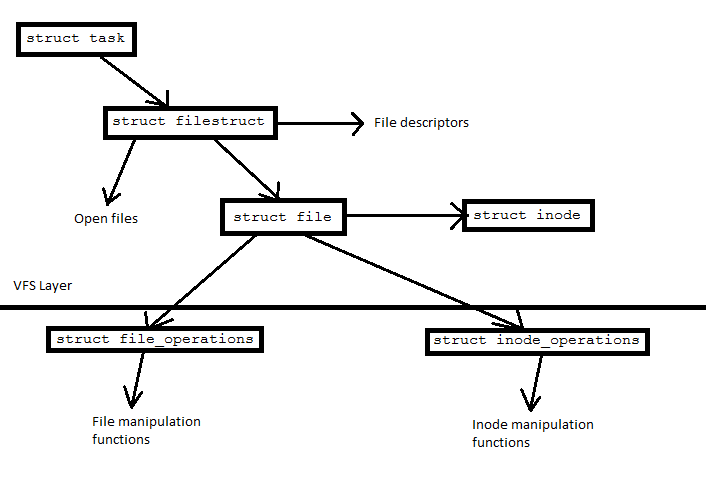
ImplementationA struct task points to a struct filestruct (which
contains file descriptors) that points to struct file's, which
point to struct inode. A virtual file system (VFS) layer hides a
set of struct file_operations and
struct inode_operations for each file system that contains
pointers to file operation functions (such as read and write) and inode
operation functions (such as link and unlink), respectively. This part of the
Linux kernel is Object Oriented; the structures under the VFS layer act as
objects.
 NFS Protocol
NFS Protocol
The NFS client code inside the kernel acts as a file system implementation
abstraction from the user. Clients can send requests according to a protocol
across the network to a NFS server.
An NFS Protocol is a RPC protocol containing a set of RPC's for interactions
between the client and server. These RPC's are similar to Unix system calls:
MKDIR(dirfh, name, attr) returns the newly created directory
and its actual attributes.
REMOVE(dirfh, name) returns the status LOOKUP(dirfh, name) returns the directory and attributes
We want to have something similar to file descriptors for a NFS, but file descriptors will not work; if the server crashes, then the file descriptor table is lost and the client's file descriptors become useless. We want NFS to survive crashes without the clients noticing any problem (except perhaps performance issues). To satisfy the above constraints, we implement file handles which uniquely identify files for a NFS. A file handle is a bit pattern combination of the device number and inode number, allowing the server to uniquely identify which file the file handle refers to. The client does not need to know any details about how the file handle works; the server will take care of operations on file handles.
A problem that can arrise from file handles comes from the fact that NFS servers are "stateless", meaning that the server does not have any information about how the clients are interacting with the files (such as opening files). In Unix file systems, if a file's link count reaches 0, an application that still has a file descriptors pointing to the file can still read and write to it. A NFS server, on the other hand, does not know when a file handle may still be refering to a file when the link count is 0. To solve this problem, the client can rename the file and still use it, while the link count drops to 0.
SynchronizationFor several reasons, clients may not see a consistent state of the NFS.
Reads and writes may be executed in a different order than the order in which
the client sent the requests. NFS does not have read-to-write or
write-to-read consistency for performance reasons. However, NFS does
guarantee close-to-open consistency; this means that when a file is
closed, all of the pending writes to that file are carried out before the file
is actually closed. This ensures that when we open the file again, all of the
modifications we previously made are actually there. Note that
close is a system call, not a RPC. This means that in order for the
server to send back an error due to a close (such as a pending write failing),
the close system is allowed to set errno to EIO (I/O error) to
signify that an I/O error occured.
One possible solution for synchronization errors is to use
synchronous write flags that allows the client to wait for writes to
finish before proceeding. Unfortunately this is quite slow and is rarely used.
Instead we must accept the syncrhonization issues so that performance does not
suffer.
A media fault occurs when disk blocks get corrupted, or otherwise go bad. Media faults will cause reads and writes to return errors. Redundant Array of Independent Disks (RAID) is one method to help prevent and recover from media faults. In general RAID attempts to distribute data across multiple disks for various benefits. Here we assume a single point of failure, meaning at most one disk fails at a time.
RAID 0: No redundency
We make multiple copies of each data block. If a read or write fails, then we can replace the disk and copy the data from the good disk onto the replaced disk. This is simple to implement but doubles the cost.
RAID 4: Parity diskWe add in an extra parity disk that allows for the recovery of data. The parity disk is a bit for bit exclusive-or of corresponding bits from the actual data disks. If a read fails, we can use the parity disk to recover the data (we take the exclusive-or of the corresponding bits of the other disks, including the parity disk, to recover the lost data).
Some downsides to this approach include the fact that writing now takes two writes instead of just one. In particular, the parity disk is written to everytime a write to another disk is carried out; this means that the parity disk can become a bottleneck if multiple writes are being executed. Another problem is that reads are much slower if they fail because we need to read from every other disk in order to recover the data. One upside to RAID 4 is that we can easily add more disk space to the system. We simply need to zero out the new hard disk. Compared to RAID 5, which distributes the parity bits across the data disks themselves, this is much easier.
Failure RatesThe failure rates of hard disks with respect to time are generally high at the beginning and drop down sharply and then increase as time goes on. The reason for the large failure rates at an early time is due to possible manufacturing errors and other defects. The failure rate increases over time because of simple mechanical use and wear.
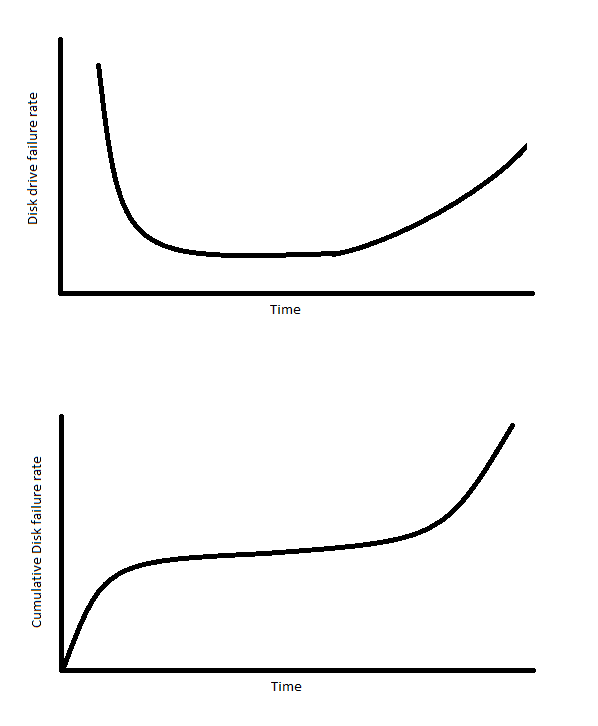
For a RAID system with multiple disks, the failure rate is amplified because a disk failures are going to occur more often since the system is composed of multiple disks rather than a single disk.