VM and Processes | Distributed Systems
Rory Snively, Louise Lehman
Contents
Caching Policy
Memory Hierarchy
What Part of Disk Should We Put in RAM?
FIFO
LRU
Paging from the Hard Disk
SSTF
Elevator Algorithm
Circular Elevator Algorithm
SSTF + FCFS
Midterm Scores
Distributed Systems & RPC
Remote Procedure Call
What Can go Wrong with RPC?
What Part of Disk Should We Put in RAM?
FIFO
LRU
Elevator Algorithm
Circular Elevator Algorithm
SSTF + FCFS
What Can go Wrong with RPC?
Caching Policy
Memory Hierarchy
- registers <-- want to use this as much as possible
- L1 cache
- L2 cache
- RAM
- disk or SSD
- backup (slow disk, tape, network disk)
Which part of disk should we put into RAM?
- varies with time
- this is a policy question - comes up no matter which mechanism we use for virtual memory at any level
- can be answered independently of hardware
- to answer this question, we have to ask ourselves: "Which page should be the victim?"
-
Suppose we have a randomly accessed memory, i.e. random accesses to virtual memory. Since accesses are random, it doesn't matter which page you choose to remove from memory. But it is rare in practice to have a randomly accessed memory. You typically see locality of reference. If a page has been accessed recently, it will likely be accessed in the future.
-
Suppose we have locality of reference. There are a lot of heuristics to choose from.
A simple one: FIFO (First In; First Out)
- pick the page that's been sitting in RAM the longest
- the way to check how well FIFO works is to run it on lots of applications
- You could actually run them, but you only care what pages it referenced and in what order, so you just want to get their reference strings.
| 0 | 1 | 2 | 3 | 0 | 1 | 4 | 0 | 1 | 2 | 3 | 4 | |
| A | 0 | 0 | 0 | 3 | 3 | 3 | 4 | 4 | 4 | 4 | 4 | 4 |
| B | ? | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 2 | 2 | 2 |
| C | ? | ? | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 3 | 3 |
There is a page fault per page we load in. This is the most important measure of efficiency.
For this reference string, using FIFO to select our victim results in 9 page faults. This is the cost of our algorithm.
- buy 2 more physical pages: # of page faults would shrink to 5 (one for each virtual page to be loaded into physical pages)
- buy 1 more physical page:
| 0 | 1 | 2 | 3 | 0 | 1 | 4 | 0 | 1 | 2 | 3 | 4 | |
| A | 0 | 0 | 0 | 0 | 0 | 0 | 4 | 4 | 4 | 4 | 3 | 3 |
| B | ? | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 4 |
| C | ? | ? | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 1 | 1 |
| D | ? | ? | ? | 3 | 3 | 3 | 3 | 3 | 3 | 2 | 2 | 2 |
FIFO with 4 physical pages: 10 page faults ("But we bought more memory!?")
This an example of Belady's Anomaly - the number of page faults increases with more memory.
Belady's anomaly is famous for being counterintuitive, yet is rare in practice.
If we had an oracle that knows the future reference string, how could we use it to determine the best policy?
Answer: Look at all the pages in use. Pick the page that is not needed for the longest to be the victim.
| 0 | 1 | 2 | 3 | 0 | 1 | 4 | 0 | 1 | 2 | 3 | 4 | |
| A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 2 | 2 |
| B | ? | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 3 | 3 |
| C | ? | ? | 2 | 3 | 3 | 3 | 4 | 4 | 4 | 4 | 4 | 4 |
Magic/Oracle: 7 page faults
This may seem unrealistic, but in many cases, applications know which pages they will be accessing far ahead of time because they rely on pre-compiled code. In dealing with operating systems code, we dono't usually have this luxury. For situations such as these, there are other methods we can use to guess which pages we will need in the future.
What's a good approximation to an oracle?
Answer: We can keep track of how often we've run things in the past.
LRU (Least Recently Used)
| 0 | 1 | 2 | 3 | 0 | 1 | 4 | 0 | 1 | 2 | 3 | 4 | |
| A | 0 | 0 | 0 | 3 | 3 | 3 | 4 | 4 | 4 | 2 | 2 | 2 |
| B | ? | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 3 |
| C | ? | ? | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 4 |
LRU: 10 page faults
We have an oracle that's faulty!
In practice, LRU normally results in fewer page faults than FIFO.
| - | 0 | |
| rw | 1 | |
| rw | 1 | |
| rw | 1 | |
| - | 0 | |
| rw | 1 | |
| rw | 1 |
- First implementation: every time you use a page, put a time stamp in the Page Table (as a clock value).
- clock - small counter for a certain number of bits
- But you'll need help from the hardware, and the hardware guys won't want to do this. Is there a way to do it without help from the hardware?
- Yes, initially make all the pages inaccessible and have a 1 bit clock.
- Page Table Entries will have one of two values:
- 1 page accessed since you cleared all the bits
- 0 page wasn't accessed since you cleared all the bits
- Pick one of the PTEs with a 0 as its clock value as the victim.
- this is cheap to compute
- you don't need help needed from the hardware
- Start off with all clock values in the PTE being zeros and the entries' permissions as inaccessible (can't read or write).
- Change the permissions to rw and the page's block value bit to 1.
- Once every 10 seconds or so, reset all the clock bits to zero.
- This clock is very low resulotion, but is much better than having no information at all.
Paging from the Hard Disk
When dealing with reads to and from a hard disk, the cost of I/O is proportional to the distance the disk arm has to move (seek time).
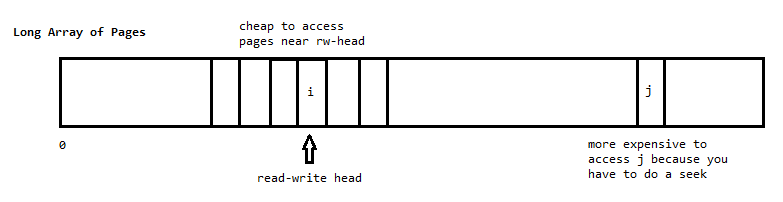
The average seek time differs depending on the current location of the disk arm. Suppose reading across the entire hard disk has a seek time t. Then if the disk arm is located at either end of the disk, the average seek time is t / 2. If the disk arm is located in the middle of the disk however, the average seek time shrinks to t / 4. With a little calcululs, we can deduce that the average cost of I/O is t / 3. In practice, the OS has several outstanding I/O requests at a time (these may have accumulated during the execution of the previous I/O). Clearly, the most efficient method of servicing these requests will have something to do with the distance the disk arm must seek. We have several methods to choose from.
Shortest Seek Time First (SSTF)
This approach examines the current requests, and responds to the one which requires the least disk arm movement.- + maximizes throughput
- - starvation is possible (requests could keep coming in near the head, and requests with high seek times could never get served)
Elevator Algorithm
Like SSTF, this method involves responding to the request which requires the least disk arm movement, but the disk arm continues in the same direction until it hits either end of the disk.- + no starvation
- - less throughput than SSTF
- - not fair to files on end of disk, because their maximum wait time is 2, while files in the middle have a maximum wait time of 1
Circular Elevator Algorithm
This method augments the elevator algorithm so that the disk arm continues in the same direction, and when it gets to the end of the disk, returns all the way to the request nearest to the start of the disk.- + more fair than the Elevator Algorithm
- - less throughput than Elevator Algorithm
SSTF + FCFS
To combine the fairness of FCFS with the high throughput of SSTF, we take our I/O requests a "chunk" at a time (chunk size predetermined). Within each chunk, requests are processed in accordance with SSTF to maximize performance. However, the chunks are pulled in FCFS order, so that starvation does not occur.
There are many more combinations which can be applied in a variety of situations (Elevator + FCFS, Circular Elevator + FCFS, etc...)
Midterm Scores
| Median | 69 |
| Mean | 67.4 |
| Standard Deviation | 12 |
Distribution of Scores
| Score | # of Students |
| 90-99 | xxxx |
| 80-89 | xxxxx xxxxx | xxx |
| 70-79 | xxxxx xxxxx | xxxxx xxxxx | xxxxx xxxxx | xxxxx xxxxx | xxxx |
| 60-69 | xxxxx xxxxx | xxxxx xxxxx | xxxxx xxxxx | xxxxx |
| 50-59 | xxxxx xxxxx | xxxxx xxxxx | xxx |
| 40-49 | xxxxx xxx |
| 30-39 | xx |
Distributed Systems & RPC
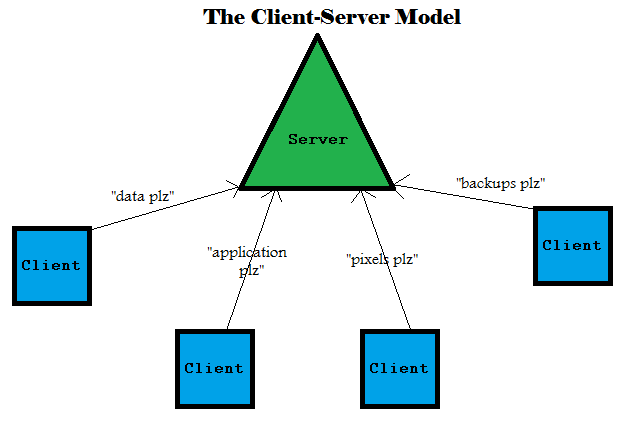
Until now, we've focused on virtualization to enforce modularity. Another approach is to use distribution instead of virtualization.
Instead of a kernel, we have a server in the position of superauthority.Instead of user code accessing hardware through the kernel, we have clients requesting access to something from the server.
The server and client can talk to each other over a network. But, the caller (client) and callee (server) don't share the same address space.
- + get hard modularity for free
- - data transfer is less efficient
- no call by reference
- instead, call by value, call by result (the return buffer might be copied back to the caller)
- caller and callee may disagree about floating point format, integer format (big endian vs. little endian, width of an integer)
- network protocol must specify data representation on the wire (e.g. 32-bit big endian 2's complement for int). If the caller or callee doesn't use that format, they have to convert before sending. see SWAB (swap byte) instruction
- Marshalling - internal data structure is prepared for transport across a network and then unmarshalled on the other end.
Remote Procedure Call (RCP)
(looks like a function call to client)
time_t t = tod("Casablanca"); // client code
(code you want to write, but can't)
time_t
tod (char* loc) {
(fancy code involving Ramadan)
return 10937263117;
}
In reality, client code must be altered to suit the needs of the network (this is usually automated, as modifying client code multiple times becomes extremely tedious).
package("Casablanca", hd);
setupID(hd, server addr);
sent(hd)
receive()
...
The server must also perform some wrapping/conversion after receiving the client request, and before sending its response.
What can go wrong with RPC:
- messages can be corrupted (add check sums)
- messages can be lost
- messages can be duplicated
Client: unlink("/home/eggert/hw5.txt")
We want to delete this file.
Suppose the client never hears back from the server. What should it do?
- keep trying (after 100 ms, 2 sec, 20 sec): at-least-once RPC
- return an error (errno == ESTALE): at-most-once RPC
- hybrid between 1 and 2
- exactly once RPC (what we usually want, hard to implement in practice)
Clients can request actions such as:
- draw pixel (x, y, r, g, b, a)
- draw triangle (x1, y1, x2, y2, x3, y3, r, g, b, a)
- ...
If our client waited to hear back from the server after each request, drawing an entire monitor's worth of pixels would take an extremely long time (considering the speed-of-light limitation on our network speed). To speed up this process, requests are sent from the client to the server in batches. That way the same amount of data is passed from the client to the server without too much network interruption.
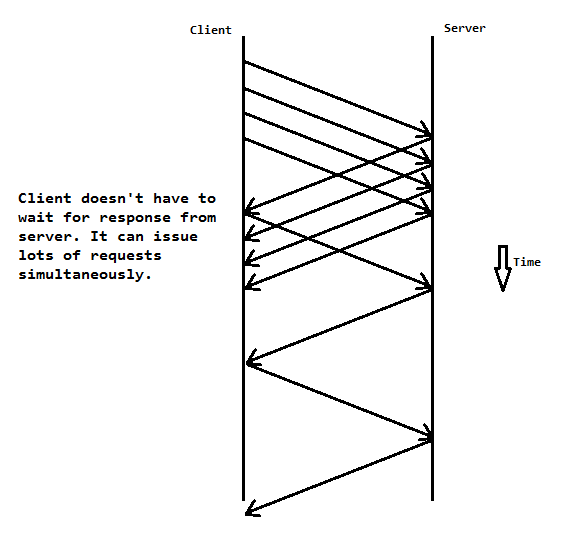
More on client-server interaction next time...