CS111: Lecture 15 Scribe Notes
By: Sung Hwan Oh
Caching Policy
- Registers →→→→→→ Want to use this as much as possible
- L1 Cache
- L2 Cache
- RAM →→→→→→→ Which part of the disk do we want to cache in RAM?
- Disk/SSD
- Back up (Slow disk, tape, network disk)
This is a policy question that can be answered somewhat independently of hardware.
Which page should be the vitcim?
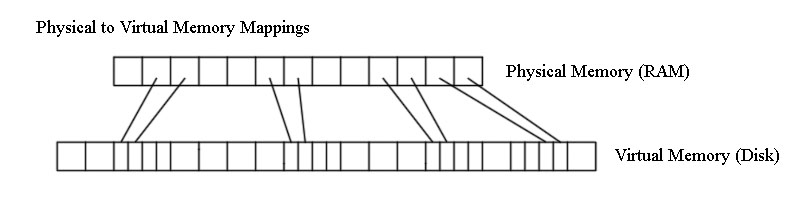
Since accesses are random, it doesn't matter. However, this is rare in practice - we typically see locality of reference
There are many things to consider - for one, the longest page in RAM is probably not the one we need.
Suppose we have 5 virtual pages and 3 physical pages with the following page accesses:
Page Accesses: 0 - 1 - 2 - 3 - 0 - 1 - 4 - 0 - 1 - 2 - 3 - 4
We count the number of page faults that occur.
| Physical Pages | 0 | 1 | 2 | 3 | 0 | 1 | 4 | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | 0 | 0 | 0 | 3 | 3 | 3 | 4 | 4 | 4 | 4 | 4 | 4 |
| B | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 2 | 2 | 2 | |
| C | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 3 | 3 |
→ 9 Page Faults
Can we minimize page faults somehow? Suppose we buy one more page.
5 virtual pages and 4 physical pages.
| Physical Pages | 0 | 1 | 2 | 3 | 0 | 1 | 4 | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | 0 | 0 | 0 | 0 | 0 | 0 | 4 | 4 | 4 | 4 | 3 | 3 |
| B | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 4 | |
| C | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 1 | 1 | ||
| D | 3 | 3 | 3 | 3 | 3 | 3 | 2 | 2 | 2 |
→ 10 Page Faults
Somehow, more memory can hurt performance under FIFO! This is known as Belady's Anomaly.
Can we find a software solution to minimize page faults? We need to change the caching policy (choice of victim).
If we have an oracle that knows the future reference string, what's the best policy?
→ Pick a page that is not needed for the longest.
5 virtual pages and 3 physical pages.
| Physical Pages | 0 | 1 | 2 | 3 | 0 | 1 | 4 | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 2 | 2 |
| B | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 3 | 3 | |
| C | 2 | 3 | 3 | 3 | 4 | 4 | 4 | 4 | 4 | 4 |
→ 7 Page Faults
This policy reduces page faults, however, it assumes that we have a static view of the code available to the compiler. Hence, is not applicable to operating systems.
Can we somehow use this strategy in the operating system?
Least Recently Used (LRU) - Approximation to an oracle
5 virtual pages and 3 physical pages (LRU)
| Physical Pages | 0 | 1 | 2 | 3 | 0 | 1 | 4 | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | 0 | 0 | 0 | 3 | 3 | 3 | 4 | 4 | 4 | 2 | 2 | 2 |
| B | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | |
| C | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 4 |
→ Generally better than FIFO, this is a counter example.
Least Recently Used - Mechanism
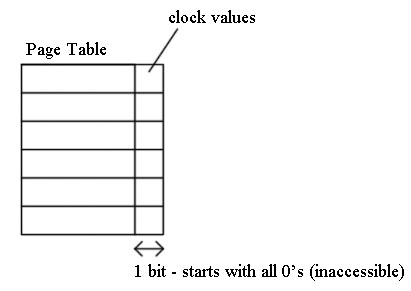
Change permission to r/w and set clock bit to 1.
Every now and then, we reset permissions and set bit to 0.
This implementation needs no help from hardware, but has low resolution.
Paging to the hard disk
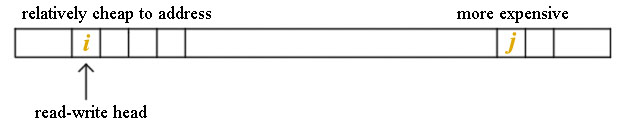
Cost of I/O ∝ distance ↔ Cost of I/O ∝ | j - i |
Suppose accesses to disk are random, then what is the cost of I/O?
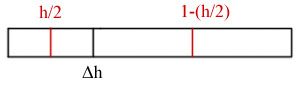
If read/write head is at 0 or 1, avg cost = 0.5
If read/write head is at 0.5, avg cost = 0.25
If the location of the read/write head is random, we can find the avg cost using CALCULUS
Assuming FCFS
In practice, the OS has several I/O requests outstanding. This is a bit of an oracle.
Shortest Seek Time First (SSTF)
-Starvation possible
Elevator Algorithm - like SSTF, but goes in one direction
-Less throughput compared to SSTF
-Not fair to files located at ends of disk
Circular Elevator Algorithm - only goes up (doesn't change direction)
At end of disk, seek back to lowest numbered request.
-Less throughput
SSTF + FCFS

Distributed Systems and RPC
Until now, we've focused on virtualization to enforce modularity.
Consider another approach to modularity: Distribution → separate hardware
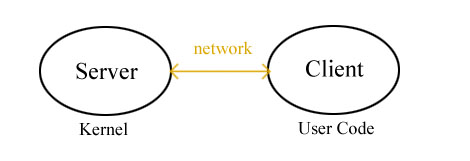
Caller and Callee don't share address space.
− Data transfer is less efficient
No call by reference.
For example:
read (fd, buf, bufsize);The pointer
bufpoints to local memory which is different on a remote machine.
Instead, we call by value or call by result
Caller and Callee may disagree
- Floating Point Format
- Integer Format
- Big / Little Endian
- Width of Integer
- etc.
→ The network protocol must specify data representation.
e.g. Use 32-bit big endian 2's complement integers
*note: we can perform big ↔ little endian conversion using the XCHG/BSWAP instruction.
Marshalling
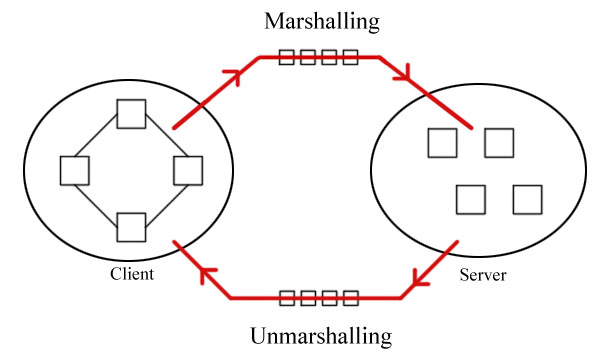
Changes the internal data structure to use on the target machine.
A Common Client Server Pattern
time_t = tod("Casablanca"); //client code
time_t = tod(char *loc) {
... code involving Ramadan and so on ...
return 1093726 ...
}
→ No marshalling / unmarshalling
Remote Procedure Call (looks like a function call to the client)
//Client Code
package("Casablanca", hd);
setupIP(hd, server_addr);
send(hd);
receive();
This process is generally automated
What can go wrong with RPC?
- Messages can be corrupted
- Messages can be lost
- Messages can be duplicated
→ We need to address these problems.
Suppose the client calls:
unlink("/home/eggert/hw5.txt");
What if the client never hears back?
- Keep trying (after 100ms → 1s → 10s ...) → at least once RPC
- Return an error (errno == ESTALE) → at most once RPC
- Hybrid of 1 & 2
- Exactly once RPC
- Most desirable, difficult to implement
Example: X-Window protocol - "pixrect on wheels"
Client: draw pixel(x, y, r, g, b, a);
draw triangle(x1, y1, x2, y2, x3, y3, r, g, b, a);
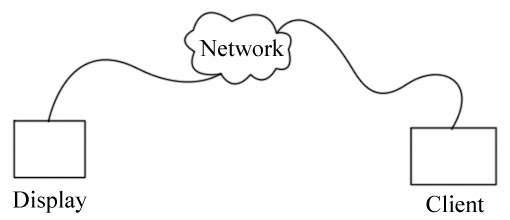
Serving requests one by one can be quite slow.
One solution
