CS111: Operating Systems (Winter 2013)
Lecture 15: Caching Policies and Distributed Systems
Wednesday, March 6, 2013
By Fahad Nathani, Nabil Nathani, Robert Nguyen
Caching Policy
In our discussion of Virtual Memory we have a general problem with caching, and this caching problem occurs at several levels in the Memory Hierarchy:
Memory Hierarchy
- Registers
- L1 Cache
- L2 Cache
- RAM
- Disk or SSD
- Backup (slow disk, tape, network disk)
At each of these levels we have caching problems. Ideally we would want to use registers as much as possible. However, in practice there are things that are too big for registers so they must be placed in the cache, and then the RAM, and then into the disk.
When you are trying to actually use a multilevel cache like this, at any particular level you will ask yourself:
Which part of the disk should we put into the RAM now?
This is a policy question that comes up no matter what mechanism we use and can be answered at a high level, answered somewhat independently of hardware.
Which page should be pulled to disk?
If you can answer this question at any moment in time, you know what policy you're going to take and thus you can answer many questions about the performance.
Suppose we have random access to virtual memory, where the Virtual Memory lives on disk if not enough room on RAM:
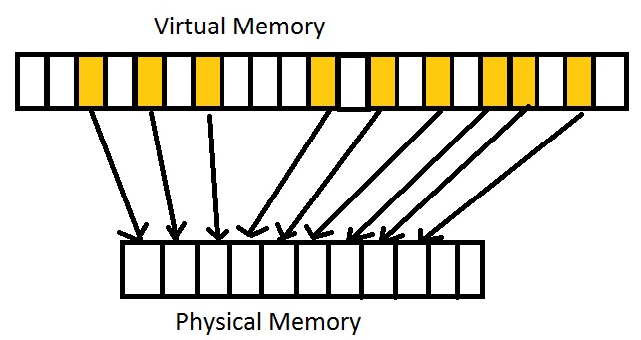
To answer the above question about which page to pull into physical memory, since accesses are random, it doesn’t matter what page you choose. For most practical computations, this supposition is wrong and rare in practice. What you typically see is Locality of Reference:
FIFO (First In First Out)
Suppose we have locality of reference:
We need to decide which ones to bring to cache, ie. physical memory
Here is a simple one: FIFO
- Pick as victim the page that has been sitting in memory for the longest under the assumption that pages get accessed for a short while and then the program loses interest in them.
- One way to check how well FIFO works is to run it on lots of applications: (get their reference strings)
- A cheap way to do this: figure out what page it reference, and in what order. You don’t need to actually run the program.
- Reference String: A list of virtual page numbers in the order that the program needed those virtual pages
- Run FIFO algorithms on the Reference Strings
Suppose for example we have a machine with 5 virtual pages, 3 physical pages: and a reference string: 0 1 2 3 0 1 4 0 1 2 3 4
| 0 | 1 | 2 | 3 | 0 | 1 | 4 | 0 | 1 | 2 | 3 | 4 | |
| A | 0 | 0 | 0 | 3 | 3 | 3 | 4 | 4 | 4 | 4 | 4 | 4 |
| B | - | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 2 | 2 | 2 |
| C | - | - | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 3 | 3 |
Total of 9 Page Faults
For many programs, page faults are the number one cause for efficiency. Since they are so costly, we try to have as little page faults as possible.
Buying two more physical pages: 5 virtual pages, 5 physical pages => 5 page faults (lower than with 3 physical pages)
Let’s say we could only buy one more physical page: 5 virtual pages, 4 physical pages, 0 1 2 3 0 1 4 0 1 2 3 4
| 0 | 1 | 2 | 3 | 0 | 1 | 4 | 0 | 1 | 2 | 3 | 4 | |
| A | 0 | 0 | 0 | 0 | 0 | 0 | 4 | 4 | 4 | 4 | 3 | 3 |
| B | - | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 4 |
| C | - | - | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 1 | 1 |
| D | - | - | - | 3 | 3 | 3 | 3 | 3 | 3 | 2 | 2 | 2 |
Total of 10 Page Faults
In the above case, we bought one more physical page, but had more page faults! This is known as Belady's anomaly – when programs got slower even when we bought more memory. This presents a problem with the FIFO caching policy.
Imagine you have an oracle that can tell you what your future reference string will look like, what would be the best policy?
Pick the page that is not needed for the longest time
Applying the Oracle's Policy:
| 0 | 1 | 2 | 3 | 0 | 1 | 4 | 0 | 1 | 2 | 3 | 4 | |
| A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 2 | 2 |
| B | - | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 3 | 3 |
| C | - | - | 2 | 3 | 3 | 3 | 4 | 4 | 4 | 4 | 4 | 4 |
Total of 7 Page Faults
LRU (Least Recently Used)
Registers can sort of do future reading for compile time of straight line code
There are cases when you can kind of consult an oracle in the memory hierarchy:
Register allocation - If you are doing compile time analysis of a long line of code, the compiler can look at the assembly code instructions and see which pages should be placed in registers, which should be kept in RAM
Approximation to an oracle is the LRU (Least Recently Used) Policy, where you throw out the pages that were least used in the past.
| 0 | 1 | 2 | 3 | 0 | 1 | 4 | 0 | 1 | 2 | 3 | 4 | |
| A | 0 | 0 | 0 | 3 | 3 | 3 | 4 | 4 | 4 | 2 | 2 | 2 |
| B | - | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 3 |
| C | - | - | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 4 |
Total of 10 Page Faults
Its worse than FIFO! On this particular reference string, LRU is worse than FIFO. However, LRU is normally better than FIFO in practice. It turns out this is just a counter example (a bad case).
What is the mechanism for LRU?
Say you want your page replacement algorithm to use the LRU policy. If you recall we have a page table, which has page numbers, access bits, etc. The kernel wakes up, and it has to pick a victim. How can it tell which page is least recently used by looking at the page table?
We are going to need help from the hardware. So every time a user uses a page the counter needs to go up by one. That’s going to slow down accesses. Plus the use-count can be used from a long time ago (the page was used 1 billion times). So it is not a counter you want, it is clock values. Every time you use a page you put a timestamp into this column (virtual memory table). Still, you are going to need help from the hardware. The clock is actually going to be a small counter of a certain number of bits.
It will work if the hardware guys implement it, but they hate this approach. Is there a way to simulate this in software, without asking the hardware guys’ permission?
They want to be doing accesses as quickly as possible. Is there some way we can come up with an approximation, maybe not the exact correct clock value. But something close?
Suppose we wanted N to be 1 (a 1 bit clock). Could we implement it then, using the techniques we already know how to do with page tables?
Make the page read only, even though it was read-write, so that we can get a page fault, so the kernel can get some information about that access, and then go and set the bits the way we wanted to.
Initially make all the pages inaccessible (accessing the page would trigger a page fault). When that happens, we set the bit to 1, we make the page accessible and we keep going. When we are done in effect we will have a bit here that is 1 if the page was accessed, and 0 if it wasn’t. Therefore we have a 1 bit clock. So you can look and see if a page has been accessed since the last time you cleared all the bits. It is really an awful approximation to having a clock but it is better than nothing. It is cheap to compute and doesn’t require any help from the hardware guys. This a trick that you can play to get the “oracle” functionality. It’s a very low resolution clock.
So start off with all 0’s, and the permissions are that you can’t do anything with these pages. As people access pages, they get a page fault. After, make the pages read-write and turn the bit to 1. After a while, there will be a bunch of pages with 1’s. Sooner or later, a victim will have to be chosen. Pick the one with a 0. Once every 10s, set all the bits back to 0. And start over again. This approach is much worse than having a good clock, but better than having no information at all.
Paging from Hard Disk
The Idea:
One way to think about it is to model the pages this way: A big long array of pages with a read-write head that points somewhere. It is relatively cheap to access pages in the neighborhood of the read-write head. But more expensive on the sides, because you have to do a seek: physically move the read-write head. Seek time (~9ms).
In reality it is as a 3D object and the geometry complicated. But using the simple, linear model we can assume the cost of an I/O is proportional to the distance. This idea being if you are at location (i), and you want to do some I/O to some page at the end of the disk (j), the cost is proportional to | i - j|.

Let us suppose we are randomly accessing the disk. The cost of one of these random accesses is the difference between the two locations (0-1). Worst case, it takes 1 second to read the end if you were at the beginning. If we make all these assumptions, the average cost of an I/O is:
- If we assume the read-write head is at 0, the average cost is 0.5.
- If the read-write head is at 0.5 (middle of the disk), the average cost is 0.25.
- 3. At any point on the disk, the general formula for the average distance between h and i is the integral from 0 to 1 of (h(h/2)+(1-h((1-h)/2))dh = 1/3
Can we do better than this?
Better Disk I/O Algorithms
Assuming first come first serve. The disk requests come in, and we just obey them. If the requests are random, we will just be flopping the disk-head back and forth. In practice, this isn’t a good strategy. What we would probably do is have several outstanding requests to the disk. The OS has several I/O requests outstanding. To some extent, because we have several I/O requests outstanding, we are a small fraction of an oracle. The outstanding requests can give us a window into our future. We can use that information in order to do a better job than FIFO would do.
Let’s say you were a busy OS. And we have 4 different requests. Which request should we do first? It’s tempting to do the cheapest first.
Algorithm 1: Shortest Seek Time First
Look at all outstanding requests, and look where the diskhead is, and choose the shortest seek time first.
+ Minimize time to do next request. Aka maximize throughput
+ Handling requests as fast as you possibly can
- Starvation (other processes won’t get time, because read head would be busy doing a requests with shortest seek time)
Algorithm 2: Elevator Algorithm
Is shortest seek time first, but you keep going in the direction you are going, until you reach the end (if possible).
Ex. Elevators continuing in the same direction before processing requests in the opposite direction
+ No starvation
- Less throughput
- Give up throughput for fairness
- Not fair those whose files are at the end of the disk. Using the elevator algorithm, you’d want to put your files in the middle of the disk. The average wait time to get to the middle of the disk is less than the wait time to get to the end of the disk
How can we fix the elevator algorithm, so that the middle area is not preferential?
Circular elevator algorithm. Elevator that always goes up. Ex. when u get to the end of the disk, do a seek back to the start. (Or go to the lowered numbered request). The circular elevator gives you less throughput than the elevator. But you get more fairness.
Algorithm 3: Shortest Seek Time First + First Come First Serve
If you have a ton of requests, keep track of request queue in order of arrival. Bite off first 20, serve these in SSTF order. When you are done, do the next 20. Do these in chunks. Therefore you maximize throughput, and improve fairness, as opposed to SSF or FCFS individually. So you try to compromise throughput for fairness.
+ Creates fairness (no preferred location)
- Less throughput
Distributed systems
With virtualization, you program up a physical machine to act like some other machine with some other instruction. We use virtualization to enforce modularity. But there is a different way to enforce modularity. If you are worried about users’ code stepping into the OS, there is a more extreme approach. Put the OS on a completely different machine. Use distribution instead of virtualization.
What we are used to thinking of being the kernel and user code becomes a server and a client. Two different programs running in parallel on different machines that can talk to each other over a network. In some ways it is very nice. If we thinking of building things this way we notice that the caller (client) and the callee (server) don’t share the same address space. That wasn’t true before. When we did virtualization, once you tracked into the kernel, the kernel has access to the physical memory, so it can look at everything you look at plus more. So if you wanted to leave a message for the kernel in the virtualization approach, the kernel can already see what is in you buffer.
This is not true for a client server approach. The client can’t see what is in the server. An advantage is that we get hard modularity for free. There is nothing that the client can do to access the servers memory. The downside since they don’t share address space is that is less effective to transfer data between client and server. In a virtualized approach the data is instantly there. But in a CS approach you have to copy data over the network. Therefore this is no call by reference.
Ex. read(fd) // Pointer to a buffer of size bufsize, uses call by reference
You can’t do that in CS approach. Pointers are only good inside the client. All we have is call by value, meaning you copy the value from caller to callee. Some calls, you can get call by result (return buffer might be copied to the server). Caller and callee may disagree about a fundamental architectural decision: Ex. Floating point format, x86, IBM mainframe. Integer format (little endian vs. big endian-MSB is first byte). Width size (32 bit long, 64 bit long) Therefore you have to be careful about copying data back and forth between client and server.
You have to have a protocol for copying data between the networks.
Marshalling
Network protocol must specify how the data is represented on the wire. For integers, we represent integers at 32 bit quantities in little endian format.
Callee and caller, if don’t use the same format, have to convert it before the send data/receive data.
A process called marshalling—what happens when you have your internal data structure (OO or tree structured). The data structure gets copied in a conventional way, and the server builds its on a data structure that might be different than the original (unmarshalling). Get data in network order. Server does its processes, and sends answer back to client(marshall → unmarshall).
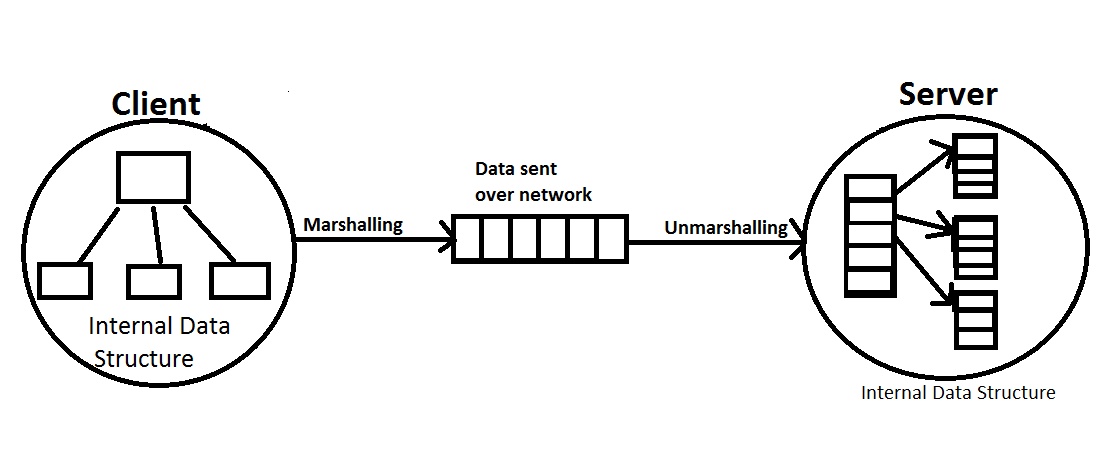
Implementing client code in this way: treat network server as if it were a kernel. You are making calls, getting results back. A common client server pattern is called remote procedure call (RPC), where instructions are basically executed remotely on the server side. From the client’s point of view, it is making a call.
Ex. Client wants to know what the time is in Casablanca
From clients point of view:
time_t t = tod("Casablanca");
That’s the code we’d like to write if we were using RPC. But we can’t, because we didn’t do marshalling/unmarshalling.
So in practice, we do something like this:
Client Code:
package("casablanca", hd);
setupIp(hd, server addr);
send("hd");
receive();
Server Code:
tod(char *loc)
{
// Fancy code involving Ramadan
return 1093726317;
}
This approach gets boring and error prone of you make a mistake. There are programs that will generate this code. They automatically generate all the packaging code. Or more commonly write specification for the time of day. The wrapper code will do marshalling/unmarshalling.
What can go wrong with RPC?
- Mesages can be corrupted
- Messages can be lost
- Messages can be duplicated
The network isn’t perfect. As you send data through network, messages can be corrupted. Bits can be flipped. Can this happen with virtualization? Yes it can. It can happen with RAM too. But happens a lot more with networks than RAM.
Solution: There is a 16 bit checksum appended to every IP packet. If it doesn’t match, then the packet gets rejected.
Leads to another problem: messages can be lost! Send a packet, and a bit flip, so it got thrown away. Or router overloaded and starts ignoring packets. So messages can be lost. Or message can be duplicated! Send a packet to a recipient, and it gets two copies. We want our distributed operating system to work well even if messages are lost, corrupt, or duplicated.
Suppose client is trying to send message to server. Client trying to remove file from server.unlink("/home/eggert/hw5.txt");
Suppose it never hears back from the server. What should it do?
Approach 1:
If no answer, client can keep trying. Has a timeout (100 ms, 2s, 20s). Longer and longer waits, but keep trying. And never give up. Keep trying until you get an answer back. At least once RPC. Guaranteeing that your request will be implemented at least once. The message could’ve gotten to server, but server response didn’t get back to you. So you removed the file at least once.
Approach 2:
Another approach is to return an error. From client point of view, make function call. After a certain period of time, return error (ERRNO = ESTALE). Specify that you tried to unlink file, it failed because we couldn’t talk to the server. The program has to be written to look at errno, and you don’t know if it succeeded or not.
Which option is better? Keep trying? Or Error?
Combination of the 2: Keep trying for a couple of times, if not then return error.
Notice you can get strange error numbers with option 1. After multiple tries, you removed the file. You didn’t get the server’s response. So you try again to remove the file, but the server says “there is no file here to remove”
If you use method 1, if the unlink fails it should check the error message. If it got the specific error message, it knows the file was actually already removed, you just didn’t receive the response message.
Approach 1: At least once RPC.
Approach 2: At most once RPC. Know you did the operation at least once.
What we want is exactly once RPC, but it’s too hard for anybody to do it.