CS 111 - Lecture 15 Scribe Notes
by Derong Liang
Table of ContentsVirtual Momory1.Caching policy
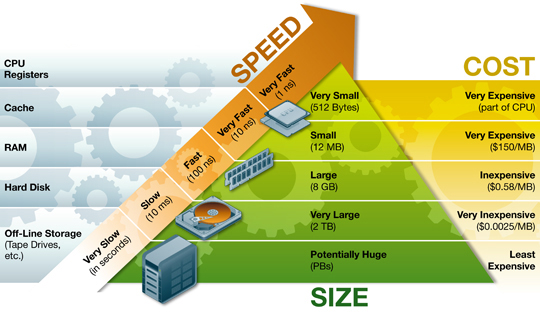
Memory Hierarchy We want to use the registers mostly because it’s the fastest. At any level, we have caching problem. For example, between RAM & disk: Which part of disk should we put into RAM now? This is a policy question, no matter what mechanism, which level, it can be answered independently of hardware. The policy issue is which page should be the victim? If it is answered, we can answer almost all of the other questions. Approach 1): Suppose we have random access to virtual memory
Who should be the victim? ------ Answer : Pick the first page, it doesn’t matter! This is rare in practice, we typically see LOCALITY OF REFERENCE. Approach 2): Suppose we have LOCALITY OF REFERENCE. ( Lots of heuristics! ) Simple one: FIFO (First In First Out), pick the victim sits in for the longest time, since it might be the most boring page. The way to check how well FIFO works, is to run it on lots of applications. But we don’t need to actually run the program, since we don’t care about the execution time, we can just get their reference strings! Suppose we have a machine with 5 virtual pages, 3 physical pages (less physical memory than virtual memory) The reference string is:
We run FIFO, evaluate with counting the page faults. Physical page A,B,C Virtual page 0,1,2,3,4 Run FIFO
The virtual page number in red means that it cause a page fault. --------- There are totally 9 page faults this case. Is there any way to improve the performance? Hardware solution: 1. We could buy 2 more physical pages, so now we have 5 physical pages. -------- The number of page faults will decrease to 5. 2. If we just buy 1 more physical page The reference string is:
Physical page A,B,C,D Virtual page 0,1,2,3,4 Run FIFO
--------- There are 10 page faults now. The number of page faults increased sometime when we have more physical memory, this is called Baledy’s anomaly. But it is rare in practice. Software solution: If you have an oracle, that knows the future reference string, what’s the best policy? ------- Pick the page that is not needed for longest. The reference string is:
Physical page A,B,C Virtual page 0,1,2,3,4 Run with an oracle
--------- There are 7 page faults in this case. While the compiler compiling, the compiler actually decide whether store the code into the registers or the RAM base on the solution above. Since we don’t have a real oracle in our life, here is the approximation to an oracle. We called it LRU, short for “Least Recently Used”. The reference string is:
Physical page A,B,C Virtual page 0,1,2,3,4 Run LRU
--------- This time we have 10 page faults. But in most of the case, using LRU will improve the performance. What’s the mechanism for LRU? In our page table,
If we use the timestamp to mark each page we used, it would make the page table too large. Here we are going to use a similar approach like the dirty bit in the previous lecture. 1) We set all the pages to be inaccessible. 2) If we want that page, we will cause a trap and enter the kernel, the kernel will mark a bit to 1 for that page. 3) Choose the page that hasn’t been set that bit to 1. 2.Paging to hard diskAssume the pages in disk as below and the time for the disk arm to move from the beginning to the end is 1. And also we use a simple model as cost of I/O is proportional to distance. So we can mark the first page with position 0 and the last page with position 1.
Assume now, our read-write head is at position i and the page we want is in position j. So the cost of I/O is proportional to |j-i| . Assume we use FCFS for I/O request and the access to disk is random, then the average cost of an I/O is 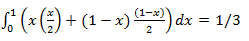
But in practice, the OS has several I/O requests that are outstanding. Some other access strategy: 1. SSTF, short for “Shortest Seek Time First”, also means “Shortest Distance First” Cons: Maximizing the throughput. Pros: Starvation may be possible. 2. Elevator Algorithm Cons: no starvation Pros: less throughput, not fair (The people in the middle floor has more possibility to access the elevator than the top floor and the bottom floor.) 3. Circular Elevator algorithm, basically when reach the end of the disk, seek back to the lowest-numbered request Cons: fairness 4. SSTF + FCFS Serve the first 20 first come requests in SSTF order and then serve the other first come 20 requests. Distributed systems & RPC1.Introduction to distributed systemsUntil now, we have focused on virtualization to modularity. And here we want to talk about another approach: distribution We can think that the client is the caller and the server is the callee. But the client and the server don’t share address space: + hard modularity for free - data transfer is less efficient No call by reference such as read (fd, buf, buf_size), instead, call by value, call by result Caller & callee may disagree about floating point format or integer format. (big/little endian, 32/64 bits)
2.Network protocolWe have to come up with a network protocol, that must specify data representation on the wire. (e.g. 32-bit big endian 2’s complement for integer) See SWAB instruction for converting little endian to big endian which usually been used in little endian machine. 3.Data marshalingThe process of gathering data and transforming it into a standard format before it is transmitted over a network so that the data can transcend network boundaries. In order for an object to be moved around a network, it must be converted into a data stream that corresponds with the packet structure of the network transfer protocol. This conversion is known as data marshalling. Data pieces are collected in a message buffer before they are marshaled. When the data is transmitted, the receiving computer converts the marshaled data back into an object. Data marshalling is required when passing the output parameters of a program written in one language as input to a program written in another language. 4.RPCRPC, short for “Remote Procedure Call” It looks like a function call from the client’s point of view. In regular function call, we have the code like below:
But it is not work on the client & server modularity. Here is the way it works:
What can go wrong with RPC?
1.messages can be corrupted (router flakes out, modem flakes out) ------ add checksum, and reject the wrong message 2.messages can be lost 3.messages can be duplicate We need to address these problems. Suppose the client call unlink(“/home/eggert/hw5.txt”) and it never hear back. We can have several options: 1.keep trying (after 100ms) (after 2s) (after 20s) …., until we get feedback, we might receive an error (errno = ENOENT), because the file may be deleted previously but the response message got lost This is called “at-least-once RPC” 2.return an error (errno = ESTALE), but we don’t know if it succeed or not This is called “at-most-once RPC” 3.hybrid between 1+2 exactly-once RPC, hard to implement example: X window protocol (“pixrect on wheels”) Assume Poctor Eggert has an X server in his office and he wants to show something on his server in the office when he is at home. He type in the client code as below to show pixels or triangles on the display of the X server
The client can just issue lots of requests simultaneously and response can be sent back without order. But this will no longer be RPC since it is like call-call-call-…-response-response |