Notes by David Gonzalez and Anthony Ortega
3/4/13
In programming we often have problems with unreliable processes. Some of the major issues occur when dealing with bad memory references, subscript errors, and deferencing null, uninitialized, or freed pointers.
Possible solutions to the aforementioned problems are:
Hardware approach
A simple approach would be to add 2 extra registers that could keep track of the base and bounds of allowed memory.
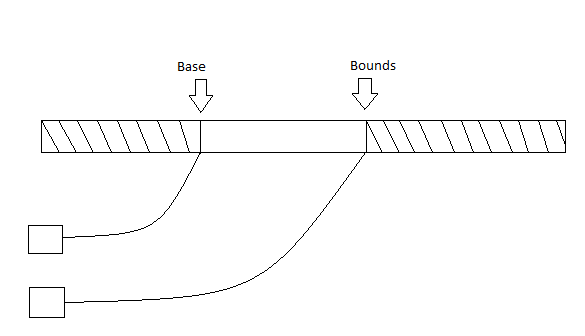
The hardware will be responsible for checking each memory access. If you attempt to access the forbidden areas, the program will trap and the kernel will determine the next course of action.
Issues
To fix the absolute address problem:
gcc -fpic or gcc -fPIC
Now what if you wanted processes to share memory? You can try and have multiple base bounds pairs. It would look something like:
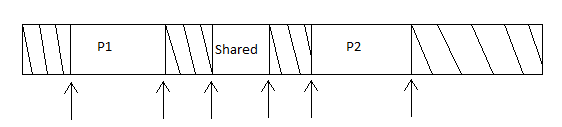
Multiple base bounds pairs would not really work because it would require many registers. Our registers are limited which means we need another way. How about a system call to create a domain?
map_domain(size,permissions,...)
The permissions are r, x, rx, rwx (It would be unusual to just have 'write' permission because the program would not be able to read what it is writing). These permissions would need to be supported by the hardware.
Traditional x86 hardware originally only supported read and write. If you were granted read and write permissions you were also able to execute. This meant that you would be able to execute the stack. This made buffer overflow attacks easy!
Some possible uses for a domain are in the:
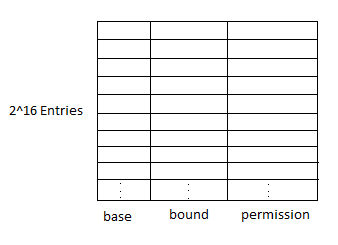
Another way to deal with shared memory is by using segmented memory. This is called Segmentation. Segmentation uses a table that is under control of the hardware and can only be changed by privileged calls. A pointer can be represented like this:
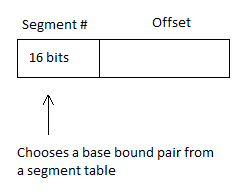
The segment table would be something like this:
Will this work? The number of segments we have can become a problem. Say we have something like:
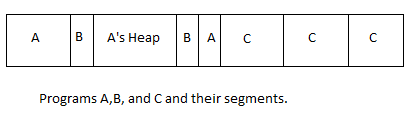
What would happen when programs try to call malloc? Say A in the above diagram needs to grow its segment. You can move over the other segments but it would be expensive.
In order to solve this problem we can use solutions that resemble those of filesystems.
Let's make pages all the same size. Say 8 kiB. We get the following:
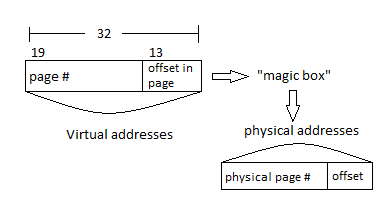
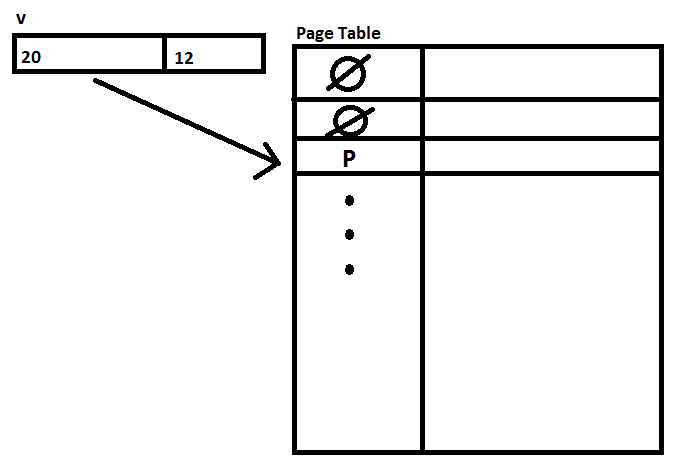
The 'magic box' is the page table. Each process will have it's own page table with a register pointing to it. Here is a simple diagram of a page table:

Now if a process calls malloc, it would just have to add an entry to the page table.
To implement shared memory we can do something like this:
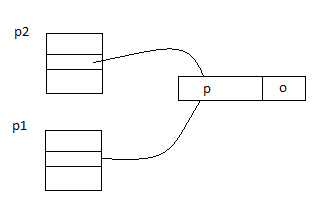
The above picture resembles hard links in filesystems
Note that the system should(and most likely will) prevent us from doing something like this:
There are several ways to implement page tables. One way is by using a linear page table.
Linear Page Table
One way to map from virtual to physical memory is with the linear page table. Here the code takes the virtual block number and looks up the correct physical block in the page table. Each entry is called a page table entry and holds an integer that denotes the physical block. The leading bit in the entry denotes whether the page is actually in physical memory.
Pages in x86 are 4KiB big and virtual addresses are split with 20 bits being the page table lookup and the last 12 bits of the integer are extra data bits. So each process has its own page table with 2^20 entries and each entry is 4 bytes long. The code for lookup looks like this:
phys_page p = pmap(virt_page);
int pmap(int v){
return PAGE_TABLE[v];
}
Where PAGE_TABLE is stored in a register (usually %cr3) and v denotes virtual page number and p denotes physical page number. The actual page table layout looks like this:
Thankfully this is a fairly fast operation. Page table look ups don't kill performance so they could be a good option. Unfortunatelly basic linear page tables aren't very good with memory usage. Doing some quick math we can see the size of the page table. Size = 2^20 entries * 2^2 bytes = 2^22 bytes or 4MiB. Since each process has its own page table we can see that they take up a lot of space. More importantly a lot of the PTE's go unused and as such quite a big amount of RAM gets wasted too.
So the next question we should be asking is can we improve upon the linear page table to improve its memory usage. Well we can take a look at how approached big files for file systems. In file systems we used indirect blocks as a way of keeping inode size small. Is this possible for page tables? As it turns out it is, x86 supports whats called two level page tables. In two level page tables the top table entries map to lower pages whose entries then map to the physical block. The virtual address split has 10 bits to denote top level page, 10 bits for second level page and the remaining 12 bits performing the same tasks as the linear page table.
The code to obtain the maping gets a little trickier but is still manageble. It looks like this:
int pmap(int v){
int hi = v >> 10;
int lo = v &(1 << 10) - 1;
pt * p = PAGE_TABLE[hi];
if(!p)
return 0;
else
return p[lo] >> 1;
}
The two level page table layout looks like this:
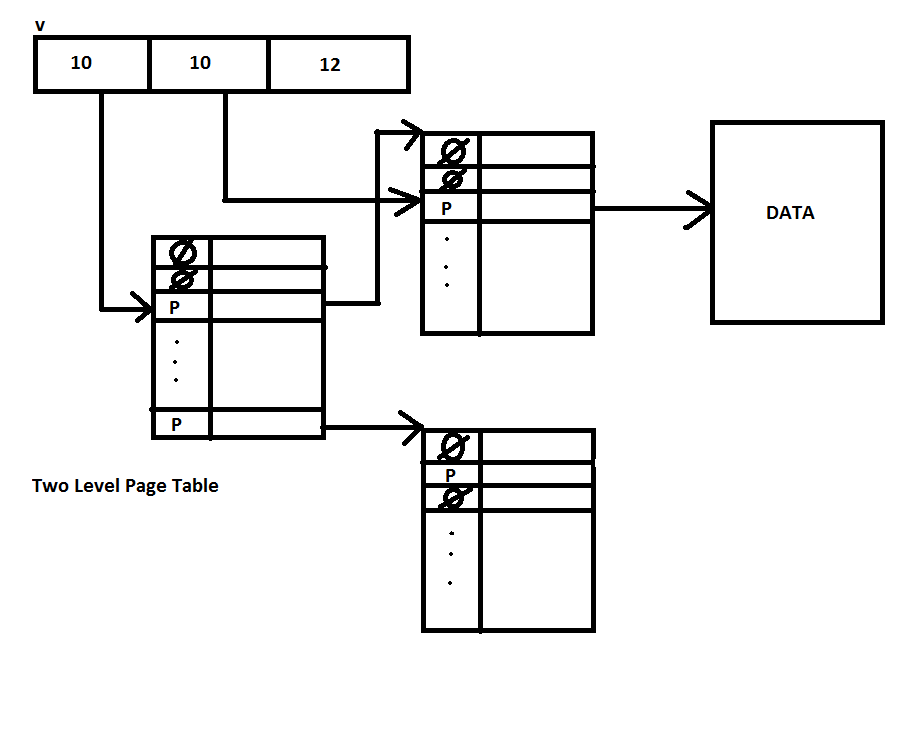
This is still a fairly fast operation so using a two level layout isn't going to slow the OS down significantly Its memory usage is also much better, instead of 4MiB per process the two way the amount is 3 * 4 * 2^10 bytes which is about 2^13 bytes or 8KiB. The only thing left is that we add a control bit to tell the OS whether we are using a linear page table or a two level page table.
Page Swapping
Now on any modern system we have numerous processes each having certain memory requirements. As these processes run they pull more and more of their pages into RAM and fill their page tables. What if we run out of RAM? What tricks can we play with virtual memory to avoid this?
The answer is fairly simple. The OS Kernel lies to the hardware and tells it that the current process is smaller than it acutally is. This is done quite often, usually when a process requires more RAM than the system has access to or if the system wants to limit the amount of RAM that a process consumes.
How do we actually do this? Well the disk reserves a certain area called the Swap Space. This area contains a copy of all virtual memory used by all currently running processes. Main memory is then used as a cache for the current process (or any other running process). So as a running process requires a page, if its not in main memory already then the OS loads it from the swap space and writes any page it may have overwritten back to the swap space.
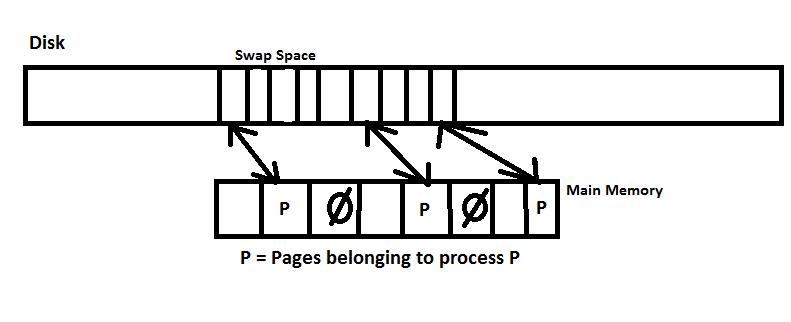
The action of a process having to load its page into main memory is called Page Faulting (which causes a trap). This operation is very slow and not an advantage. Not only does the very slow main disk have to be read from, ocasionally it has to be written to as well. A process that page faults an excesive amount will run very slowly.
Page Faulting
Lets take a look the mechanism for page faulting
The overall logic goes something like this: Trap due to page fault, enter kernel, inspect faulting address, see if page is loadable, if loadable decide which page to get rid of, write that page to swap space, load requested page into memory, update page tables.
The code for the trap itself looks like this:
void pfault(int v, int access, ..others..){
if(swapmap(v, current_process) == FAIL)
kill(current_process);
else{
(p,va) = removal_policy();
pa = p->pmap(va);
p->pmap(va) = FAULT;
read(pa, swapmap(current_process, v));
current_process->pmap(v) = pa
}
}
Where p is the process holding the page to be killed, va is the virtual address of the victim, and pa is the physical address of the victim. removal_policy is the function that determines which pages are eligible to remove.
Now we have to keep track of which pages can be removed. For linear page tables, the answer is most of them. Memory manager pages are always wired to the memory and can't be removed. Else it would be impossible to actually swap pages in and out. Two way page tables are a bit more complicated. Base pages (ones with the data) are usually able to be removed. Pages acting as page tables in the level above the main memory pages can also probably be removed. The top level page that keeps track of the second level pages probably should be left alone.
Virtual Memory Improvements
Now that we have our virtual memory worked out (the base mechanics at least) we can try to tweak it for run time improvements. There are a few that we can try but we will focus on two.
Every store instruction can change this bit. If there hasn't been a change then we don't write it to the swap space.
The Dirty bit can be kept track of in the 12 extra virtual address bits but this is more work for the hardware if done seperately. A better way to do this is to clear the write bit in the PTE on a load. Since the process itself knows that it has write access to data this will cause a trap. Upon the trap we can set both the write bit and the dirty bit and trigger the disk write if necessary for a swap.