CS 111 Lecture 14: Virtual Memory
by Alan Liao, Matthew Arakaki, and Yuncun Shen
Table of Contents:
Introduction
Processes are often unreliable because of bad memory references
Causes: subscript errors, dereferencing null, uninitialized, fixed pointers, etc.
Possible Solutions:
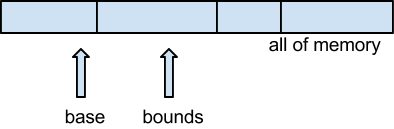
Simple Hardware Approach: Base/Bound Pairs
Add 2 extra registers: base, bounds
This design does a hardware check for each memory access. whenever a process tries to access a forbidden area, a trap is initiated.
Issues with this approach:
EX.
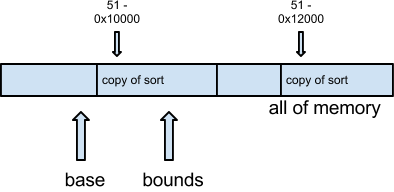
To fix absolute address problem:
How does one protect the base/bound registers?
From now on, let's call the blocks of memory allocated with the base/bound pairs domains (name arbitrary)
Segmentation: Multiple Base/Bound Pairs
What if you want shared memory between processes?
To implement this idea, we would need to add a system call to create a domain
It might look something like this:
map_domain(size,permissions);
Permissions need to be supported by the hardware (execute,read_execute,read_write, etc.).
traditional x86 had only read and write permissions (no execute)
Problem with map_domain - not enough base/bounds pairs
To show this, let’s look at all of the uses for a domain:
To solve this problem, replace base/bounds pairs with registers
ex.
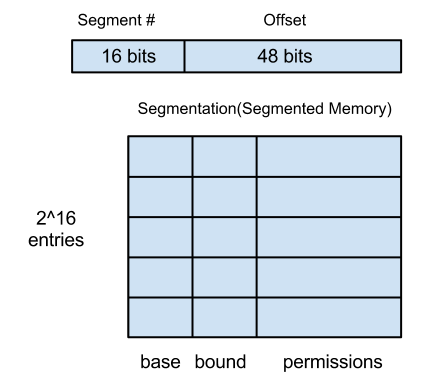
-segment # chooses a base/bound pair from segment table
-privilege needed to change the segment table
This process is called segmentation (or segmented memory)
Page-Based Memory Management
New Problem: new x() or higher level malloc() ie. allocation of dynamic memory
![]()
What if one wants to grow a segment? It's very expensive since you would have to move a lot of data
Solution: Page-Based Memory Management
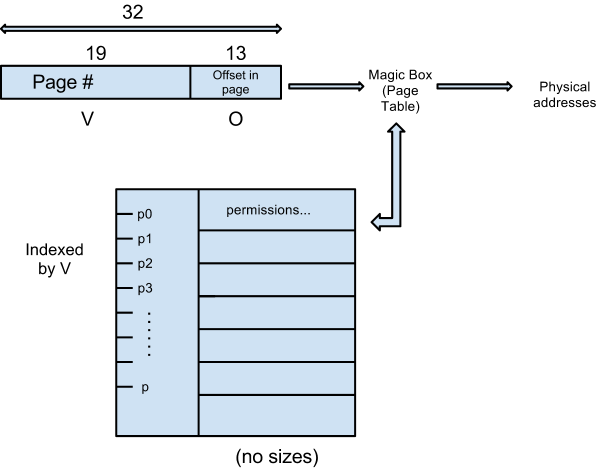
There are a few problems with this implementation though
Security Issue:
Performance Issue:
int pmap(int v) {
return PAGE_TABLE[v] >> 8;
}
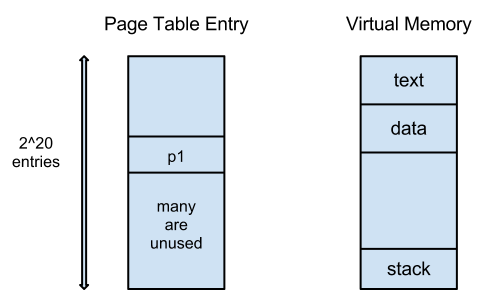
2-Level Page Tables
To fix the performance issues, we can add an extra level of indirection
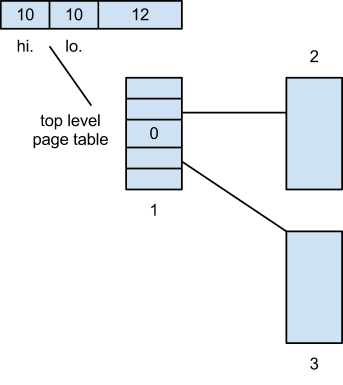
int pmap(int v){
int hi = v>>10;
int lo = v&(1 << 10) -1
pt* p = PAGE_TABLE[hi]
if(!p)
return 0;
return p[10]>>8;
}
Page Faulting
As the OS kernel, we might want to "lie" to the hardware and tell it that the current process is smaller than it actually is in the hardware page table.
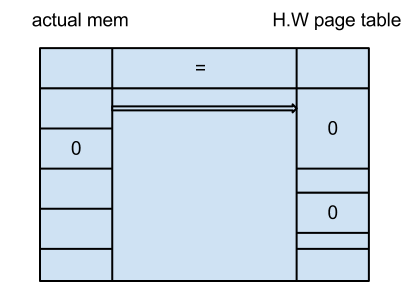
This is actually fairly common. Often, a program thinks it has more memory than it actually has (ex. program thinks it has 3.5GiB but it actually has 100 MiB)
To allow dynamic memory:
swap space on disk
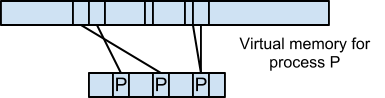
AKA Page faulting (causes a trap)
Mechanism for page faulting:
trap -> enter kernal -> it inspects the faulting address
ex.
p = process(addr,victim page)
va= virtual addr of victim
pa = physical addr of victim
void pfault (int v, int access) {
if(swap_map(v,current_process) == fail)
kill (current_process);
else{
(p,va) = removal_policy(); //picks a physical page
//as victim
pa = p-> pmap(va);
p->pmap(va) = FAULT; //mark as bad, placed before write
//to avoid race condition
write(pa, swap_map(p,va));
read(pa,swap_map(current_process,v));
current_process->pmap(v) = pa;
}
}
Memory Manager Pages are never selected as victims
Virtual memory Tuning
1) Demand Paging - when you start the program, load just its 1st page (popular)
2) Dirty Bit - 1 bit/page that keeps track of whether the page has been stored into (only needed for pages with w permissions)