CS111 Scribe Notes: File System Design
Prepared by Xin Wei for lecture by Professor Eggert on February 2, 2013
Important of File System Design
Suppose you get a bug report from a client. It involves how much disk space you're using.
$du //Display Disk Usage
76 a/b
97 a/c
263 a
However the client didn't care about all of this. There is a -s option in which it omits the details
$du -s a //Display Disk Usage on aNow this is fine, but however when he tries to do this.
263 a
$du -s a a/bThat displayed the same thing without listing anything for a/b. Ok, let's try the other way around.
263 a
$du -s a/b a$du is busted! But the disk usage he is seeing is in fact correct. There is no bug in it!
76 a/b
157 a
So uh ... What's going on then?
$du tells you how much disk space you are actually using. $du and similarly with $df are about how much space is actually being used, not about the apparent size. The apparent size and real size does not have to to match.
So why do this? Why don't real and apparent size equal to each other?
For the case with real size > apparent size, this can be used to reserve memory for future use. However notice that the data here won't be persistent. Because everything is stored in RAM, you will lose all of the data when you turn off your computer.
How about the case for apparent size > real size?
Hard Links! Two Directories, pointing to the same file. Directory 1 takes up 4 blocks. Directory 2 takes up 4 blocks. And a file that takes up 100 blocks.
Now if you run du on dir1, it will have 104 blocks. This is the same case for dir2. But if you run:
$du dir1 dir2This is the same if you run the other way around.
104 dir1
4 dir2
$du dir2 dir1This is happening because $du doesn't count the same space twice! Now let's say if our file system is 100% full. If we run the command
104 dir2
4 dir1
rm dir2 file, we gain 0 disk space because we just erased the pointer between dir2 and the file.
Definition of File Systems
What is File System? To the user, it is a collection of files. But to the implementer, a file system is a bit more complicated. It provides an abstraction of a set of organized files.A Dumb File System (Circa 1974) - Created by Eggert himself

We pretend here that a disk drive is a big length of blocks. Everything else is just unused space. But one problem here ... how do we know where the files are? We have a table at the beginning.
- [-] To create a file, you have to tell the file system how much space it's gonna need, hence you need to know the size in advance.
- [-] Limited Length of File Names (Only 16 Byte Array)
- [-] External Fragmentation - Free Space is Scattered and in Pieces
- [-] Internal Fragmentation - Free Space Doesn't Start on Sector Boundary
- [-] External Fragmentation - Free Space is Scattered and in Pieces
- [+] Contiguous Files - Hence very fast access for sequential files
- [+] Very Simple
- [+] Real Time
How to solve Fragmentation? Use a Defragmenter!
Defragmenter is usually very slow. Ideally with two disk drives. One to read and one to write. This works well if these files are READ_ONLY. But if the file system is active and there are files that wanna grow. If you run out of the power while running a defragmenter ... then you lose.
Defragmenter is usually very slow. Ideally with two disk drives. One to read and one to write. This works well if these files are READ_ONLY. But if the file system is active and there are files that wanna grow. If you run out of the power while running a defragmenter ... then you lose.
FAT (File Allocation Table)
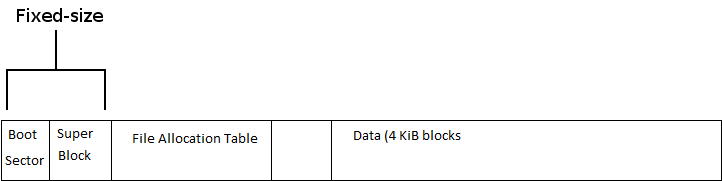
In this file system, a disk is a block, it utilizes 4kb block size. Most of the FAT file system is allocated to data. FAT utilizes a superblock that is in the beginning of the file system, right after the boot sector. We have a special kind of file called the directory - basically a file that maps file names to numbers. In the superblock, there is the root, which contains the block # to find the first directory (root directory).
- [-] Files aren't contiguous, hence sequential reads are very slow. (This is because the seek time involved)
- [-] lseek turns into an O(N)
- [+/-] No Hard Links
- [-] External Fragmentation is still a problem.
- [-] Moving Files is a pain - Not atomic (imagine moving a file, then suddenly your computer crashes, the file will then exist in either both directories or nowhere on your file system
- [+] Easy to grow files
- [+] No artifical limitation on number of files
Directories in FAT
A directory in FAT is just a file that contains zero or more directory entries. Each directory file resides on disk and grows the same way a regular file is grown.This is FAT-16 because the block number are 16-bit numbers. 2^28 is the limit of the bytes that your file system can go. (28 from 4Kb - 2^12 and 16-bit, so 16+12=28).
Berkeley File System / UNIX Style File System

Whereas in FAT you have to search for -1 in order to get the whereabouts of freespace. In this file system, we use inodes. A inode entry is like a table and is fixed size. It contains metadata entry on every file that is present on the file system. Running out of space? No problem! The last two blocks of the inode entry can point to an indirect block. A indrect block table is simply a table consist of various entries of inode tables. Still running out of space in the table? Then we can also use the last two blocks of that to create a double indirect block (essentially a block that points to an array of indirect blocks).
Note that in an inode table, the name of the file is omitted, and only location is shown. This is because we want renaming to be simple and easy. The max size of a file in this system can be: 80 kb (only direct data blocks). But if you add in indirect blocks you can get up to 80kb+16mb (direct blocks + indirect block). If we utilize a double indirect block, then it can go up to 80kb+16mb+32gb (direct blocks + indirect block + double indirect block). The inode table can also have holes. Holes are not allocated, read as zeroes, and created on write. Why holes? Because of lazy writing out files and external hashing.