Lecture 11: File System Design
By Eric Pham, Thomas Clapp, Vincent Cheung, Vincent KyiTable of Contents
Introduction
What is a "file system"?
From a user perspective, a file system is a collection of files. From an implementation perspective, a file system is a hybrid data structure that serves to abstract a collection of files. It is hybrid in nature because it lives both on secondary storage (i.e. disk) and on primary memory (i.e. RAM). Its design should feature (1) persistence , (2) security , and (3) efficiency.
Simple File System
How does it work?
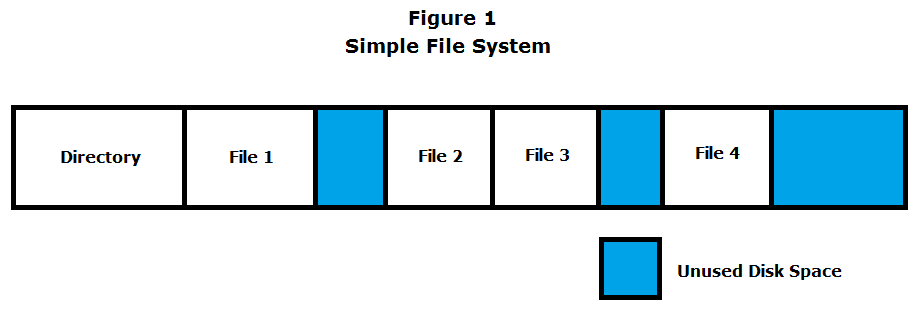
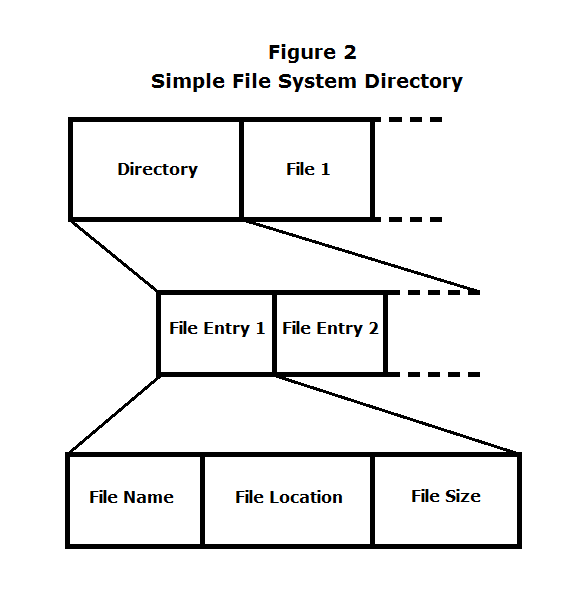
Designed from scratch by Eggert circa 1974, his file system was implemented using a disk treated as a large array of blocks. At the beginning of the disk, there exists a fixed-size directory (Figure 2), which contains file information including: (1) file name, (2) byte location, and (3) file size. The data field follows the directory and consists of contiguous files, which may be separated by unused space (Figure 1).
Advantages of the Simple File System
Disadvantages of the Simple File System
- The size of the directory is fixed. If this size is too small, the directory can store very few files' information so we are limited in the number of files we can create. If this size is too large on the other hand, the consequence is that we waste space on the directory when that space could be used to store files.
- In order to create a file, we need to know its size beforehand so the file system can determine whether the disk contains enough contiguous space to store it.
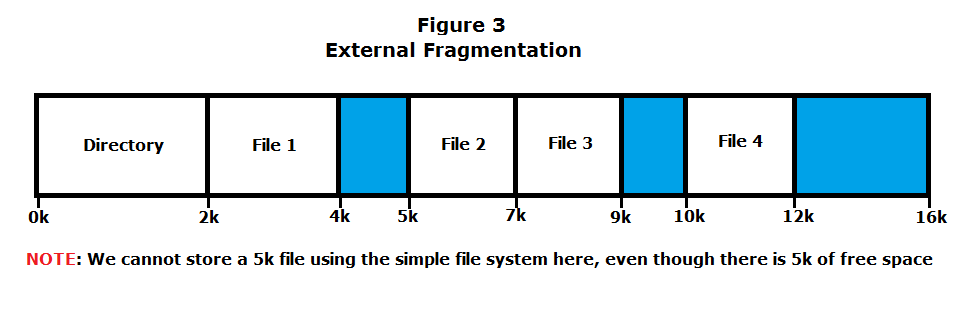
- The amount of files stored can be restricted by external fragmentation (Figure 3), which occurs when the sum of unused space in the disk is sufficient to store a new file, but no contiguous space in disk can do so.
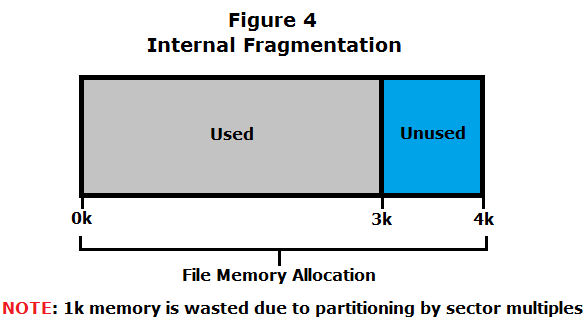
- Disk space can be wasted due to internal fragmentation (Figure 4). This occurs because the file system allocates a chunk of memory that is a multiple of the sector size, for a file to be stored, and the file does not require the entire allocated memory. The excess memory is unusable and goes to waste.
- It is not easy to grow a file. For example, a file may not be easily appended to because the contiguous space following it may become occupied by another file. We could potentially solve this issue by writing a defragmentation program which will rearrange files contiguously when we want to create or update a file, but the program will run slowly.
- We have no way of creating directories, nevertheless a heirarchy of files
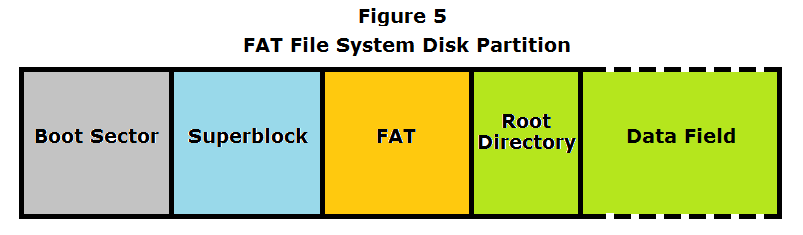
FAT File System
FAT File System Design
-
Partition Boot Sector
A Partition Boot Sector sits at the front of the disk and contains information that the file system uses to access the disk data. For example, Master Boot Record use the Partition Boot Sector on the system partition to load the operating system kernel files. -
Superblock
Just after the Partition Boot Sector comes a superblock , which is small, fixed-sized cluster that contains the file system's metadata (i.e. version information, total number of blocks, etc.). -
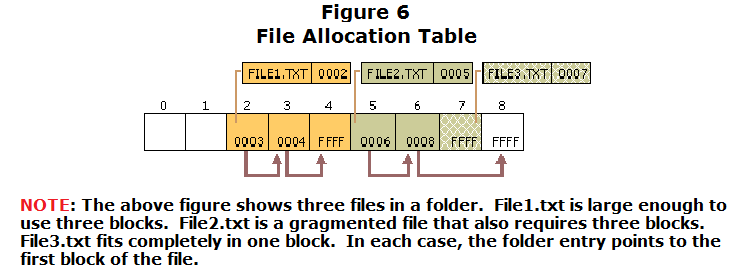
File Allocation Table
Following the superblock is the File Allocation Table, which is the method of file organization the FAT file system is named for. The File Allocation Table stores block indeces that map out blocks within the hard disk. An index can have a value N:- N = -1: mapped block is free
- N = 0: mapped block is 'EOF'
- N > 0: the index of the next block
-
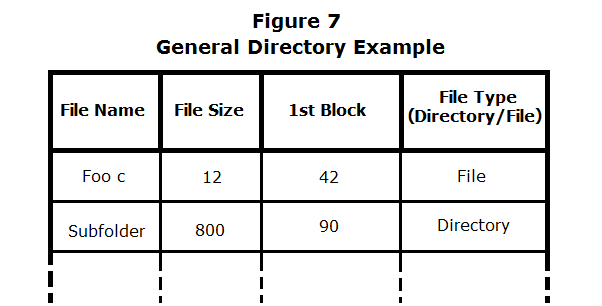
Root Directory and Folders
The root folder is at a specified location and has a fixed number of entries. It contains an entry for each file and folder on the root, namely the first block of each file and folder. Each of these entries contains the names, sizes, first block locations, and type (directory/file), of data within. The same structure follows for all directories/folders. -
Data Field
The remainder of the disk is broken into 4 KiB blocks that store file data.
Improvements from the Simple File System
- Scan the file allocation table for an unused block and the 'EOF' block.
- Modify the 'EOF' block to point the unused block, and the unused block to point to 'EOF'.
- Update the size in the directory and write out the data to the 2 blocks.
Downsides to FAT File System
- Due to file fragmentation (Figure 6), read and write operations will be very slow in comparison to the Simple File System because the disk head must jump around frequently for I/O operations. However, we can solve the performance issue by using the defragmenting program to organize blocks of the same file contiguously, as discussed for the Simple File System
- The lseek() command will degrade into O(N) time because we will need to scan the file allocation table sequentially to access file data. Accessing the file allocation table from disk is already a slow operation, and if we store the table in RAM we may be wasting valuable space.
- We have no way of enforcing atomic writes and no way of implementing hard links.
- Some disk space is still wasted due to internal fragmentation.
UNIX File System
(aka Berkeley Fast File System, BSD, etc)
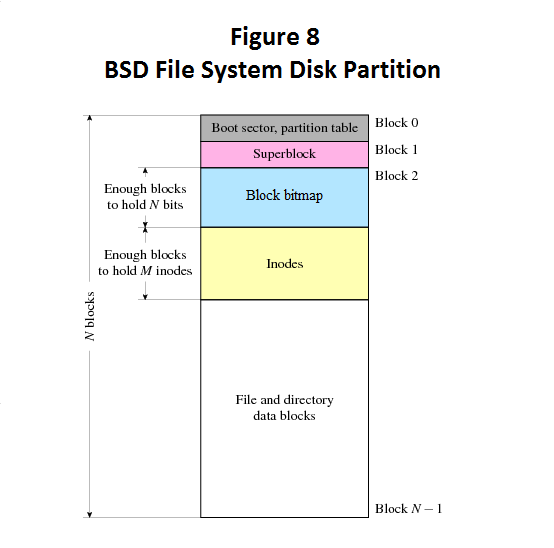
File System Disk Partition
- Boot Sector: same as FAT
- Super Block: same as FAT
- Block bitmap: maps 1 bit to a block of data to indicate whether or not the block is free
- inode table: information on each file and where data is located
- data: location of data
The index-node (inode)
- 10 blocks containing data for the file (direct blocks)
- A (indirect) pointer to a block of pointers which point to blocks containing data for the file. These are indirect blocks of data.
- A (doubly indirect) pointer which points to a block of indirect pointers. (store files ~32 gB in size)