CS 111: Operating System Principles
Lecture 9: File Systems
Data Presented: Wednesday, February 13, 2013
Professor: Paul Eggert
Scribe: Alexander Lin
Introduction
Most programs need a place to access, process, and store data.
Although RAM provides some implementation for memory management, it is inadequate for meeting the demands of most applications.
File systems are implemented to manage information on a much larger scale.
The following properties characterize the benefits provided by any adequate file system:
- Persistent Storage
-
Without a file system, there is no place to store data for an extended period of time.
-
RAM cannot store important data beyond the life of a program.
-
Files store data for later use.
- Organization
-
The file system keeps track of files and their locations for quick and easy access.
- Space
-
In many cases, the amount of information needed by a program takes too much memory for RAM to store it.
-
Files provide programs with more space to store data.
- Security
-
File permissions implement basic security by allowing users to allow or prevent others from accessing or manipulating their data.
- Reliability
-
Like all programs, file systems are expected to be accurate and robust when handling requests for accessing and processing files.
- Performance
-
The file system should find and access files quickly.
-
The delay between a sent request and a received response should be minimal.
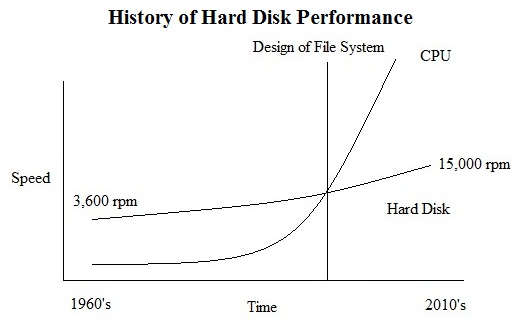
CPU performance has increased on a non-linear scale as time has passed.
However, disk performance continues to only improve at a steady, almost constant rate.
With the development of the file system, CPU performance has far surpassed disk performance.
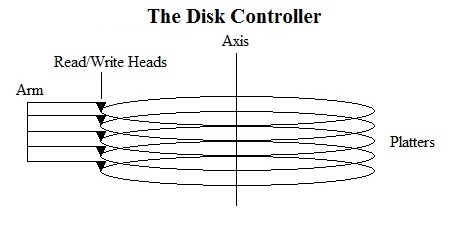
The Disk Controller
A hard disk contains several platters containing data.
The disk controller consists of an arm possessing several read/write heads for accessing data contained in each platter on the diak.
As the disk rotates about an axis, sectors of the platters spin under the heads and are read into a buffer.
The heads are aligned, so a cylinder of data is read for every disk rotation.
The arm manipulates which cylinders of data are read by moving the heads to different cylinders of the platters.
To read a specific sector from the disk, the arm must move the heads to the right cylinder and wait for the sector to rotate under the head.
Devices
Device Metrics
- The external transfer rate is the rate at which data is transferred from the disk controller's buffer to the bus.
-
The sustained transfer rate is the rate at which data goes under the heads in the disk controller.
This data is transferred from the heads in the disk controller to the buffer.
- The average seek time is the average time to move from one cylinder to another at random.
- The amount of time before a given sector is read is approximately half the time for one rotation.
- Assuming the disk head is in the correct cylinder, a sector to be read may be on the opposite side of the disk.
- The number of contact starts/stops is the number of times disk can be turned on or off before wearing out.
- The annualized failure rate is the frequency of failure in a year.
- Operating shock is the maximum amount of force that the device can handle without being damaged enough to affect operation.
- Non operating shock is the maximum amount of force that the device can handle before becoming completely inoperable.
Hard Disk Drives (HDD)
A hard disk drive is a storage device that uses disks to store data.
The drive contains a disk controller for managing data on a hard disk.
Many of the metrics of the hard disk are influenced by the spinning disk.
Hard Disk Drive Example: Seagate Barracuda LP 2
| Device Metrics | Seagate Barracuda LP 2 |
| Total Storage | 2 TB |
| Cost | $150 |
| External Transfter Rate | 300 MBits/s |
| Sustained Transfter Rate | 90 MBits/s |
| Average Latency | 5.5 ms |
| Average Seek Time | 10 ms |
| Cache Size | 32 MB |
| Disk Rotation Speed | 5900 rpm (98.33 Hz) |
| Contact Starts and Stops | 50,000 |
| Power (Operating) | 6.8 W |
| Power (Idle) | 5.5 W |
| Read error rate | 10^-14 nonrecoverable read errors per bit |
| AFR | 0.32% |
| Operating Shock | 70 G |
| Non Operating Shock | 300 G |
| Noise (Operating) | 2.6 Bels |
| Noise (Idle) | 2.5 Bels |
- Much of the noise produced by a HDD is caused by the spinning of the hard disk.
- Disk latency for a given sector to pass under the heads in the disk controller reduces the performance of the HDD.
- Since the HDD heavily relies on moving parts, it is more negatively affected by impacts.
Solid-State Disks (SSD)
An SSD is a storage device that uses integrated circuits to store data.
Data is stored electronically in the circuits instead of on a disk.
SSD's contain no moving mechanical components, so they produce less noise, have smaller access times, and are less fragile than hard disks.
SSD Example: Corsair Force GT
| Device Metrics |
Corsair Force GT |
| Total Storage | 60 GB |
| Cost | $90 |
| External Transfter Rate | 3 GBits/s |
| Sequential Read Rate | 280 MBits/s |
| Sequential Write Rate | 270 MBits/s |
| Mean Time Between Failure | 1 Million Hours |
| Shock Capacity | 1000 G |
| Maximum Power | 20 Watts |
Comparison
| Device Metrics |
Seagate Barracuda LP 2 |
Corsair Force GT |
| Total Storage |
2 TB |
60 GB |
| External Transfter Rate |
300 MBits/s |
3 GBits/s |
| Cost |
$150 |
$90 |
- Hard disks generally hold more storage than SSD's.
- Storage costs less per unit for a hard disk than for an SSD.
- However, SSD's achieve faster transfer rates than those for hard disks.
Performance Strategies
Speculation
A file system uses speculation to improve performance by predicting requests ahead of time and processing them before the application makes them. The file system finishes work ahead of time to mask delay.
Example: Prefetching
Suppose an application reads blocks based on a predictable pattern. The file system could predict future blocks that the application will request and read them ahead of time.
For example, if an application read adjacent blocks, the file system could read the next adjacent block before the application requests it.
Example: Batching
Suppose an application makes many requests to read data from a given location.
Instead of reading one of these blocks each time the application requests one, the file system could read a large batch of blocks at once to prepare for future requests.
Dallying
When given a request by the application, the file system waits instead of processing the request immediately. Future requests may be done simultaneously with the previous request to save time as opposed to processing each request individually. Time is saved if simultaneous processing results in the prevention of repeating similar instructions for each request.
Example: Batching
Write data is placed on a buffer to write to the disk. Instead of performing a write for every write request, the file system delays writing to the disk until the buffer is full. Batching increases the amount of data to write but reduces the number of disk writes which saves time.
Example: Reading
Suppose an application requests a read from a given location and then requests another read from a different location. The file system could delay the processing of the request and instead wait for any future read requests from the current location.
This reduces the amount of searching done for the file system.
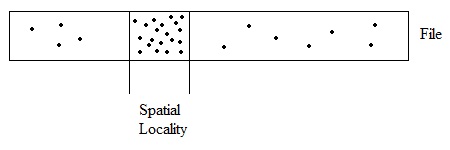
Locality of Reference
In practice, data requests have patterns which can be analyzed to predict the application's next request.
Spatial Locality
The file system can take advantage of spatial locality if the application repeatedly requests data in locations that are adjacent to each other.
Speculation can be used to access memory early and get data in adjacent locations before the application requests them.
Dallying can be used to wait for all requests from the current location before accessing memory.
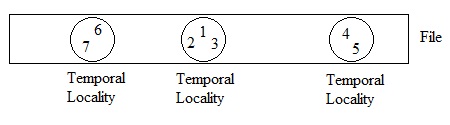
Temporal Locality
An application may make several requests for data in a small location during a given time interval.
Dallying can be used to wait for all requests from the current location.
Performance Metrics
- Latency is the delay between a request and its response.
- Throughput is the number of requests per second can the file system handle.
- Throughput is inversely proportional to latency.
- Utilization (of CPU) is the percentage of the CPU that is devoted to useful work.
- Utilization (of disk) is the percentage of disk that isdevoted to useful data.
Example Problem
Simple Problem
Consider a machine with the following properties:
- Cycle time = 1 ns
- Each instruction takes one cycle
- 1 programmed I/O (PIO) = 1000 cycles = 1 microsecond
- The PIO must go into bus and collaborate with other devices on the bus
- 5 PIO's to send a command to a disk = 5 microseconds
- Disk latency = 50 microseconds
- 1 PIO per Byte of data to read = 1 microsecond
- Computation (mostly read-only) = 125 cycles per Byte = 0.125 microseconds per Byte
The following code reads and processes one character at a time:
for(;;) {
char c;
if(sys_read(&c) < 0) {
break;
}
process(c);
}
Analysis of Simple Problem
The latency per read is:
5 microseconds (send command)
+ 50 microseconds (disk latency)
+ 1 microsecond (inbyte)
+ 0.125 microseconds (compute)
= 56.125 microseconds
- Throughput = (number of requests)/(latency) = (1 request)/(56.125 microseconds) = 17,817 requests per second
- Utilization = (computation time)/(latency) = 0.125/56.125 = 1/500 = 0.2%
A machine that uses this simple strategy for reading and processing bytes experiences high latency and low throughput.
Utilization is also very low.
Batching Problem
Instead of processing only one Byte at a time, batch with 40 Bytes to increase throughput.
for(;;) {
char buf[40];
if(sys_read(buf, 40) < 0) {
break;
}
process(buf, 40);
}
Analysis of Batching Problem
The latency per read is:
5 microseconds (send command)
+ 50 microseconds (disk latency)
+ 40 microseconds (1 PIO/Byte * 40 Bytes)
+ 5 microseconds (0.125 microseconds/computation * 40 computations)
= 100 microseconds
- Throughput = (number of requests)/(latency) = (40 requests)/(100 microseconds) = 400,000 requests per second
- Latency per request = 1/(throughput) = (1 second)/(400,000 requests) = 2.5 microseconds/request
- Utilization = (computation time)/(latency) = 5/100 = 5%
A machine that uses batching for reading and processing bytes experiences a lower latency and higher throughput for each requested byte in comparison to the simple strategy.
Utilization also increases but is still small.
Overlapping Input and Computations
The elapsed time for processing a request can be improved by implementing device interrupts.
Interrupt handlers can handle PIOs and computations in parallel.
The following pseudocode handles device interrupts:
do {
block until there is an interrupt
handle interrupt()
} while (more data);
handle interrupt() {
Issue PIOs for next request
compute
)
Analysis of Overlapping Problem (Part 1)
The latency per read is:
5 microseconds (send command)
+ 50 microseconds (disk latency)
+ 40 microseconds (PIO)
+ "5 microseconds" (computation) (done in parallel with PIO ==> = 0 microseconds)
= 95 microseconds
- Throughput = (number of requests)/(latency) = (40 requests)/(95 microseconds) = 421,052 requests per second
- Delay per request = 1/(throughput) = (1 second)/(421,052 requests) = 2.375 microseconds/request
- Computation time vanishes due to parallelism.
- However, the buffer is too small for parallelism to be very effective.
Analysis of Overlapping Problem (Part 2)
- Use a buffer of 400 Bytes
The latency per read is:
5 microseconds (send command)
+ 50 microseconds (disk latency)
+ 400 microseconds (PIO)
+ "50 microseconds" (computation) (done in parallel with PIO ==> = 0 microseconds)
= 455 microseconds
- Throughput = (number of requests)/(latency) = (400 requests)/(455 microseconds) = 879,120 requests per second
- Delay per request = 1/(throughput) = (1 second)/(421,052 requests) = 1.1375 microseconds/request
- Throughput and delay have both significantly improved.
- In practice, however, there are other factors that contribute to delay such as extra overhead of the interrupt handler.
- This type of parallelism can only be achieved while the delay of computation is less than latency.
Direct Memory Access (DMA)
Direct memory access allows the file system to access memory in parallel with the CPU.
With DMA, the file system can perform computations while the DMA controller completes the transfer of data.
Analysis of DMA
- Suppose it takes 5 microseconds (PIO) to set up the transfer
- There is an extra overhead of interrupt handler (e.g., 5 microseconds)
The latency per read is:
5 microseconds (DMA setup)
+ 50 microseconds (disk latency)
+ "40 microseconds" (PIO) (done in parallel with other work ==> = 0 microseconds)
+ "5 microseconds" (computation) (done in parallel with disk latency ==> = 0 microseconds)
+ 5 microseconds (overhead of interrupt handler)
= 60 microseconds
- Throughput = (number of requests)/(latency) = (40 requests)/(60 microseconds) = 666,666 requests per second
- Delay per request = 1/(throughput) = (1 second)/(666,666 requests) = 1.5 microseconds/request
DMA and Polling
To avoid the extra overhead of interrupts, a polling strategy is used instead of a blocking strategy.
The file system sets up the data transfer for the DMA controller to complete.
Then the file system performs other work while the DMA controller finishes the transfer.
However, the file system polls the disk controller after finishing its work instead of having the DMA controller interrupt it.
Analysis of DMA and Polling
The latency per read is:
5 microseconds (DMA setup)
+ 50 microseconds (disk latency)
+ "40 microseconds" (PIO) (done in parallel with other work ==> = 0 microseconds)
+ "5 microseconds" (computation) (done in parallel with disk latency ==> = 0 microseconds)
= 55 microseconds
- Throughput = (number of requests)/(latency) = (40 requests)/(55 microseconds) = 727,727 requests per second
- Delay per request = 1/(throughput) = (1 second)/(666,666 requests) = 1.375 microseconds/request
- Although this strategy improves throughput and delay, the file system uses polling and thus performs a busy wait.
- The file system continues polling the DMA controller after it finishes until the DMA controller finishes the transfer.
- Polling wastes resources, while blocking saves resources since the file system would sleep until interrupted by the DMA controller.
Multitasking
Multitasking allows processes to run simultaneously through a scheduler.
If the current thread cannot obtain the resources it needs to do work,
then it invokes the scheduler and transfers control of the CPU to another thread that can use it.
- Input is done with this code snippet:
while (inb(0x1f7) & 0xc0 != 0x40)){
yield();
}