Let's take a look at an upcoming NFS as an example:
Oracle's Sun ZFS Storage 7320 Appliance (Available May 2012)
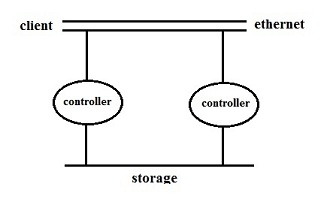
- 2 storage controllers
- 2 10 GbE adaptors
- 8 512 GB SSDs (for read acceleration)
- 8 73 GB SSDS (for write acceleration)
- 136 300 GB 15 kRPM hard drives
Add these all up and you get: 37 TB total exported capacity (32 filesystems)
Observation: Why are there 2 controllers, 2 adaptors, etc.?
This ensures that there is no single point of failure. There needs to be a balance between redundancy vs. performance.
What do the benchmarks look like?
- Taken from spec.org, a website that measures how fast everything is
- Using the benchmarks for NFS v3 (SPECsfs2008_nfs.v3), the performance graph for the Sun system:
Observation: the NFS is roughly 3x faster than a local hard drive. Why/how?
The overhead of sending data over a network < overhead of disk arm movement
Performance and RPCs
RPCs (Remote Procedure Calls) are a part of NFS
- A client issues a request (read, write, etc.) to the server and must wait for a response.
- Say that the wait time between a request and response is 2 milliseconds long. Then, a series of RPCs would look like this:
As one could imagine, a series of RPCs in this fashion would be very slow. How can we speed things up?
Solution: Use multiprocessing
- We now have overlapped reads and writes
- This works well if threads are independant
What about in a web browser?
C: read a page: GET /HTTP/....
S: returns the page
C: read a page: GET /HTTP/.... S: returns the page
etc.....
- Again, this is really slow, but this can be fixed using http pipelining.
HTTP Pipelining
Definition: getting multiple pieces of a website a once and then piecing the webpage together
Like multiprocessing, so speeds up wait times and increases performance
However, we now have the issue of dealing with failed Out of Order (OOO) requests:
If a previous step fails, we will not find out until later
Solutions:
Don't pipeline: be slow; wait for actual responses
Pipeline: be fast; keep going and lie to the user about whether a request worked or not
If implementing solution 2, it is common to report errors on the close operation. We now have that close is slow, but that is okay because everything else will be fast.
Example: if (close(fd) != 0)
// do something with the error
Pros/Cons of RPCs
+ hard modularity (different address spaces)
- messages can be delayed
- messages can be lost (between the client and server)
- messages can be corrupted
Solution: Use checksums. If the server detects a bad packet, report the error and ask for retransmission
If there is no response:
- try again / keep trying (at-least-once-RPC). This method is good for idempotent operations (Ex: read, write, etc.)
- return an error to the caller (at-most-once-RPC). This method is good for dangerous operations (Ex: transactions that involve money, etc.)
- exactly-once-RPC NFS Protocols
NFS assumes a "stateless" server
This means, a controller's RAM doesn't count as part of the state, only the cache does.
Some NFS protocols:
Protocol
Return
READ(fh, data)
WRITE(fh, data)
LOOKUP(fh, name)
fh + attributes
REMOVE(fh, name)
CREATE(fh, name, attr)
fh
- A file handler is just an integer, for simplicity's sake, that uniquely identifies a file (like inodes in an actual filesystem).
- In order for this to work, part of the NFS code will be in the kernel.
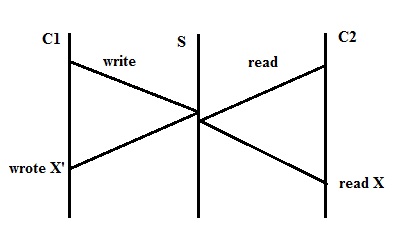
Another problem: 2 NFS clients
Even though C1 writes to the file before C2 reads it, C2 is still stuck with a copy of the old data.
- NFS does not guarantee write-to-read consistency (one client may get old data)
- NFS does, however, guarantee close-to-open consistency (because they are slower) Reliability
What in an NFS can potentially fail?
- bad network --- we can address this using retries
- bad client
- bad server
- bad disk (media faults)
Media Faults
RAID - Redundant Arrays of Inexpensive Independent Disks
Combines multiple disks together into a logical unit for variety of redundancy & performance optimizations/combinations using different configurations (RAID categories)
Defined and presented in a paper at UC Berkeley
Categories:
RAID 0 - concatenation: allows for a bigger virtual disk than physical disk
Idea: string multipe small disks together to get a large virtual disk
RAID 1 - mirroring: reads are faster than average; can also read both disks at the same time
Idea: duplicate disks so that both disks can be read from, making information retrieval faster
RAID 4 - XOR disk: can recover information if a disk fails or is corrupted; fixes media faults
Using RAID4, we can now defend against disk failures
- If the XOR disk fails, we can recompute it by XORing disks 1 to N-1
- If any other drive failes, we can recompute it using the XOR disk
(For example, if B fails, recompute its information via A ^ C ^ D ^ (A ^ B ^ C ^ D from XOR disk))