
Date: 3/5/2012
Scribes: Casey Patton, Nick Van Hoogenstyn, Meng-hsun Hsieh
Lecturer: Paul Eggert
Two ideas for surviving power failures
1) Keep a Commit Record
High level idea: Several writes may occur, but only the final write is captured. It is this single, low level write (commit) that counts.
Example sequence of actions:
Phases
1. Pre-commit phase: the stuff you do before you write to the commit record. These writes are not committed to. At any time in the pre-commit phase you can back out and act as if nothing happened. Any writes you've done to the disk are temporary and will be ignored after a reboot.
2. Commit (or abort) phase: you might write a commit record or write a record saying that the transaction didn't work. Commit and abort should be atomic.
3. Post-commit phase: Commit or abort has occurred. You are not making any changes to the file system to undo the command, but you may be writing to the file system for cleanup / efficiency reasons. This involves more writes but they won't change the fact that we committed. If you abort, then from the user's point of view nothing happened; cleanup may also have to be done in this case.
From the top-level view, this is like a transaction. Inside, there are lots of writes and one very important write that comprise the transaction. We’re using the commit record to create a higher level transaction from a simpler one.
2) Keep a Journal
High-level idea: A journal is a way of organizing your file system (or any kind of system) in order to make commit records natural and easy to do.
Implementation
Partition your file system into two areas: cell data and the journal.
Cell data is simply the actual data of the file system. These are the pages / blocks we are used to. One transaction may involve writing to several blocks.
The journal records every change that was made to cell data. As you make changes to the cell data your journal gets longer. For every commit record you add to the journal, any necessary information for identifying that commit record is also added.
Later on, if the system crashes and you want to recover its state pre-crash, walk through the journal and see all the changes. The commit records will tell you what changes happened so you can replace the old state.
If the journal runs out of space, wrap around. Make the journal ~2x the size of main memory, that way you’re probably safe to wrap around. If this is unsafe, stall.
The figure below shows how a journal keeps track of changes to the cell data. In this example, the cell data was changed from B to A, so the journal records this action on its tape for recovery purposes.
Possible Logging Methods
Write-ahead logs:
- Log all the writes you plan to do, but don't actually do them (no writes to cell data yet).
- Commit
- Install new values into cell data.
Write-behind logs:
- Log all the old values into the journal, write the values you're about to erase
- Install the new values into the cell data
- Commit
If you crash in the middle of installing new values, we can check the old values and refill data according to these.
Write-ahead vs. write-behind
Write-behind must be replayed backwards. This leads to faster reboot because all the important stuff is at the end of the log anyway. There is the potential for lower latency.
Write-ahead must be replayed forwards. This means slower reboot; we need to scroll through all the unimportant information. There is the potential for higher latency.
Advantages of using a journal
+ The journal can be put in a contiguous section on disk and the arm can stay there. Writes can be contiguous during bursts of activity. If the application all of a sudden needs 50 writes, put them all on the journal!
+ The journal can also be on a different disk than the cell data. This leaves one disk arm to record transactions and another to read, write, etc. in the cell data. The journal could also be put on a small, fast SSD while the cell data is on the “real” disk.
+ There is no need to put cell data on disk at all; put it in RAM and keep the journal on disk. Recovery will take a while, but typical operations will be fast.
A more complicated approach to logging:
We let user applicationss "look inside" pending transactions. Suppose one process is writing to a disk and it's finished the pre-commit phase, but hasn't yet committed. Another process wants to read from the disk. We let this process see the data that hasn't been committed yet.
+ Better performance / parallelism
+ Lower latency
If the reading process reads the non-committed data and then the writing process aborts, we read the wrong data! We need a way to notify applications that a transaction peeked inside was aborted. A signal could be sent saying that the data read was bad. If an application gets one of these signals it should probably abort because it's working on different data. This leads to cascading aborts. This also leads to compensation actions. This is a common approach for dealing with an abort.
It’s possible to use a commit record without a journal, but it doesn’t make sense to keep a journal without commit records. Most secure systems use both.
Virtual Memory
Problem
Unreliable programs with bad memory references. For example, GNU grep 2.10 on 64-bit host can access any part of memory and stomp on it. If you ran this bad command on WeensyOS, the kernel would crash!
Solutions
1) Hire better programmers and write better software! Quit accessing memory that you shouldn’t! One idea is to formally verify all code for correctness. This works but it can be very expensive.
2) Runtime checking in compiler generated code. This is the method that is used in Java. This works but it is very slow.
3) Base and bounds register pair. Have one register point to base (area you CAN use), and another point to bounds (area you CANT use). Use hardware checks that all memory references fall between base and bounds. This is simple to implement. Below is a representation of base + bound register in a physical RAM.

Issues with base and bounds register pair
1) One would need to preallocate the needed RAM. It’s possible to grow RAM on the fly, but this is awkward and complex. This also makes it tough to use processes efficiently
2) Memory gets fragmented. It gets fragmented both internally and externally. An example of internal fragmentation is that users might ask for more RAM than they actually need, causing a lot of wasted space.
3) Apps can change their own base and bounds register. This would be severe problem, but it has a simple fix: make register access privilged.
4) Shared memory is not practical. Generally, processes can only access their own space.
4) Multiple base and bounds pairs. For example, have one base and bounds pair for read only text, one for read-write data, etc.
Issues with multiple base and bounds pairs
1) Need to allocate base/bounds for every command. For example, say you have text for ‘cat’ between 0x30000 and 0x40000. Now when you compile and link cat, you have tell the linker where cat’s going to execute. Fortunately, this has solutions. One solution is to make all commands use relative jumps. However, this solution requires a rewriting of many commands. Another solution is to use dynamic linking or patching.
2) Fragmentation - A segment can’t grow or shrink easily since they must be contiguous. One solution is to use fixed size pages.
Solution 1: Fixed size pages
One approach to this is for every 64-bit virtual address to have the first 16 bits be a segment number and the last 48 bits are the offset into the segment. This still leaves the fragmentation problem. We can't grow / shrink segments easily because they have to be contiguous.
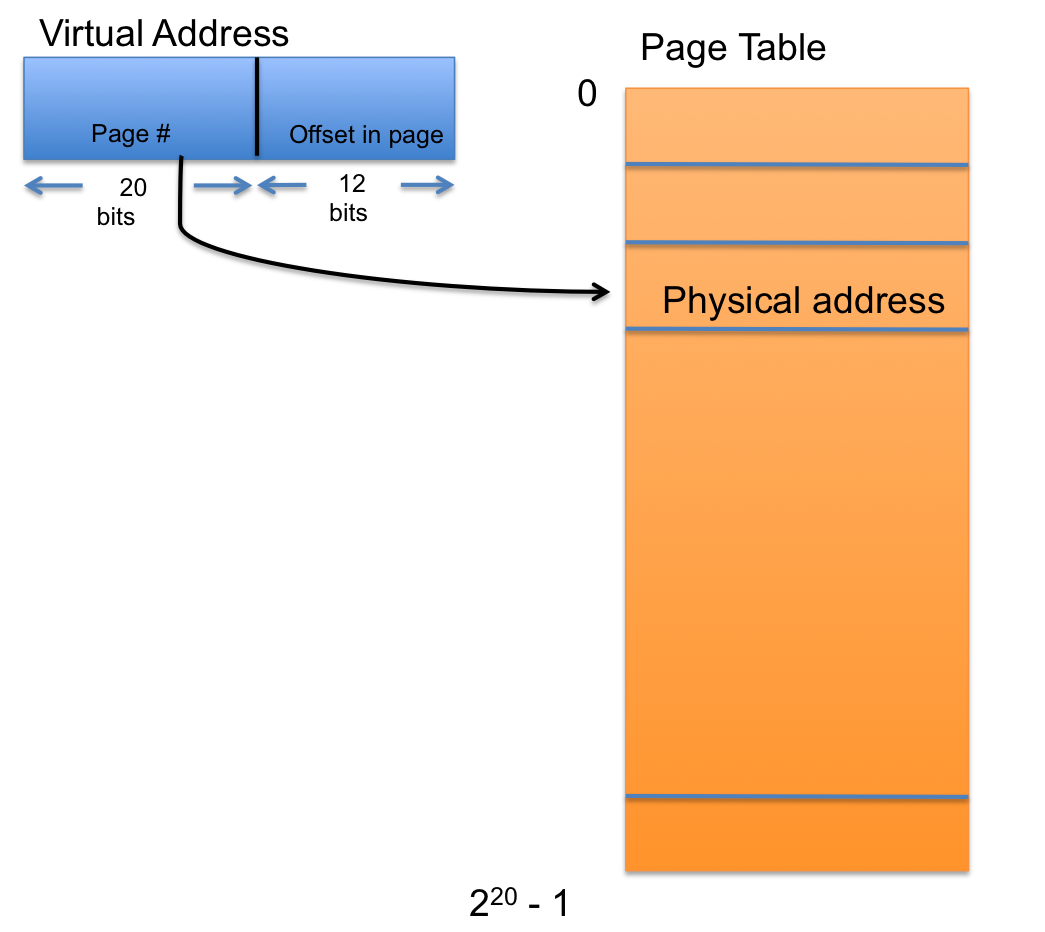
We want to solve the fragmentation problem the same way we did it in file systems. Break memory into fixed size pages. There might be some internal fragmentation still but it's not a big issue. An example size page is 4KiB.
The page number is used as an offset into a page table, and the page table holds pointers that point to the physical address. We also want a way to indicate in the page table that a page doesn't exist. This requires hardware assistance. Every time we do a load / store we present a virtual address to the hardware, it will map through a page table to find the actual physical address. This would be too slow in software which is why it needs to be done with help from hardware.
(An illustration of fixed size page)
Solution 2: Software emulation of 2-level page table
// This is a C implementation of a 2-level page table pmap function
size_t pmap(size_t va){
int offset = va&(1 <<12) - 1;
int lo = va >> 12 & (1 << 10) - 1;
int hi = va >> 22;
size_t *l0page = PAGETABLE[hi]; //privileged register %cr3
if (l0page == FAULT){
return FAULT;
}
size_t *l1page = l0page[lo];
if (l1page == FAULT){
return FAULT;
}
return l1page + offset;
}
What happens if hardware FAULTs due to bad page table entry (PTE)? It can trap. Also, the kernel can terminate the process, send SIGSEGV to the process, and arrange for the accessed page to be loaded into RAM. This can help extend RAM.