Bug Description
and Possible Fix
The
bug in the grep
program
will show up if we pass to the program a particular regular
expression and a file that contains a long line.
Consider the
command: grep -r
'^.*x\(\)\1' file.
When
grep
is
executed, it computes the length of a line in the file using the
following code int len =
strlen(“...the long line...x”);.
Suppose
that in file,
there is a line that contains 2^32+2 bytes, then the integer len
in
the code above will have a negative value due to signed integer
overflow.
A malicious user can take advantage of this bug to
access the memory that normally shouldn't be accessible and perform
an attack on the host computer.
One way to fix this bug is to
change the type of len
from
int to
size_t,
this will solve the signed integer overflow problem, but a malicious
user can still perform a Denial of Service (DOS) attack.
Another Form of
Attack – Denial of Service of Attack by Holey File
A
DOS attack is an attack that aims at using up the computing resource
of the host computer such that the host computer cannot perform
normal tasks.
Even
though now we no longer have the signed integer overflow problem, a
malicious user can still perform a DOS attack by passing a huge file
to the grep
program.
A
malicious user can create a huge file without using a lot of disk
space by creating holey files, which have valid inodes, but most of
their actual data block pointers are empty.
The following figure
illustrates how a holey file is stored on the disk.

The
following figure illustrates how holey files look like when viewed
as a sequence of data.

The
following command generates a holey file that's 2147483650 bytes in
size: echo x|dd > holey
bs=1MiB seek=2048.
When
this command is executed, 2048 blocks, each with size 1MiB, are
skipped, and then the actual data is written on the disk, resulting
in a file with 2147483650 bytes.
Ways to Get Rid
of the Denial of Service Attack
i. grep
Is for Text File Only
Since
a holey file contains a lot of zero at the beginning of the file,
it's not a text file.
The grep
program can do
whatever it wants with the non-text file.
For instance, the grep
program can output an
error if the input file is not a text file.
ii.
Skip 0's – Treat Them as New Line Characters
Treating
0's as new line characters allows the host computer to use much less
memory as it does not need to remember them.
However, this
approach still consumes a lot of computing resource, because the
grep
program has to chew
up a lot of these characters.
iii.
Check If A File Is A Holey File First
There
is no system call that check if a file is a holey file.
But we
can use stat(“file”, &st);
to
get the nominal size and physical size of the file, which are stored
in the struct st.
If
the nominal size and the physical size of a file don't agree, then
the file is a holey file.
And if a holey file is passed to the
grep
program,
the grep
program
gives up.
Why We Need
Holey File
The
holey file can be used to create hash tables as we can perform
insertion without allocating a lot of disk space.
Levels
of A Unix-Like File System
|
Symbolic Link
|
Files that
contain file names
|
|
File Names
|
e.g. “a/b”,
“foo.c”, “/a///c/d”
|
|
File Name
Components
|
Names of
directory entries e.g. “foo.c”, “usr”
|
|
inodes
|
ino_t
|
|
File System
|
(See figure
below)
|
|
Partitions
|
(See figure
below)
|
|
Blocks (8192
Bytes) on a disk
|
Linear array
(in your head)
|
|
Sectors (512
Bytes) on a disk
|
Linear array
(in your head)
|
The
following figure illustrates the relationship between file system
and partitions.

Symlink
File Name Length Limit
Questions:
Can a symlink has a file name that is a TB long?
Answer: No.
There is a limit on the file name length of a symlink.
The
following discuss several ways to store a file name in symlink.
i.
Use A Whole Block to Store the File Name
The
following figure shows how we use a whole block (8192 Bytes) to
store the file name of a symlink.
Inside the inode for a symlink,
there is a pointer to a data block in which we store the file
name.
Since each block has 8192 bytes, the limit on the file name
of the symlink is 8192 bytes long.
So if the symlink content is
small, a lot of storage will be wasted.

ii.
Store the File Name inside the Inode
The
following figure shows how we store the content of the symlink
inside the inode.
Since the inode size is fixed, the file name of
a symlink must be smaller than the size of an inode.

iii.
Symlinks Don't Get Inodes; Symlinks Are Merely Directory
Entries
Instead
of storing the content of a symlink in the inode, we store the
content as directory entry as shown in the table below.
|
Name
|
Inode
#
|
Flag
|
|
mysl
|
/usr/bin/ls
(symlink content)
|
Symlink
|
|
abc
|
27
|
|
This
implementation makes the contents look up faster as we don't need to
find the inode.
The following figure illustrates the Linux –
ext3 v2 directory entry that uses idea above.

There
are two reasons for using both the 16-bit directory entry length and
the 8-bit name length.
The first reason is that by using both of
these two fields, we get a better alignment.
The second reason is
that keeping two fields makes unlink much faster.
The following
figures explains why it's faster.
Before:
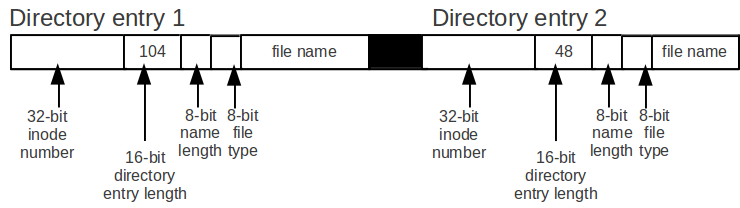
After:

Assume
we have two directory entries, directory entry 1 with a entry size
of 104 and directory entry 2 with a entry size of 48, and we want to
unlink directory entry 2.
The simplest way to unlink directory
entry 2 is to increase the directory entry length of directory entry
1 by the directory entry length of directory length 2.
Remove
Data from the Disk
i. Time Complexity Analysis
Using
the implementation discussed above, the time complexity to execute
the command rm -rf directory,
is O(N^2), where N is the number of entries, because the entries are
represented linearly.
To speed up this command, we can use a hash
table to store the directory entries' offset in the directory's
inode, which will improve the performance to O(N).
ii.
Safety Analysis
Question:
After we execute the command rm -rf
*, are
data of files still accessible?
Answer: Yes, the data blocks,
inodes, and meta data are still on the disk.
To wipe the meta
data out, we can use the command >
filename
, but the actual data may still be on the disk.
To wipe the
actual data out, we first output something random into the file, and
then remove that file.
The sequence of commands dd
if=/dev/random of=x
and
rm x
will wipe out the actual data on the disk.
(Note: A faster
version of this command is to use /dev/urandom, although this is not
as randomized as /dev/random, it's enough for wiping out the data
from the disk.)
Question: Why prefer writing random data instead
of writing zeros?
Answer: There are devices that can read
previous traces of data. If we use zero, it's easier read the
previous traces of data. But if we use random value, it will be
harder.
iii. Shred A File
The
program shred
is roughly the same as using urandom, but it uses its own random
data generator, and it does this three times.
The shred
program works on magnetic disks, but doesn't work on solid-state
drives (SSD) because of the wear-level algorithm.
The only way to
wipe out the data on an SSD is to throw it in the fire.
iv.
shred Program
Issues
A)
Bad blocks
A disk has a bad block table that keeps where the bad
blocks get mapped to.

A
malicious user can still get the content of the remapped blocks.
B)
shred
is too slow
Time to shred a 1TB disk takes a long time.
The
solution to this problem is to encrypt the disk.

We
keep a key that specifies how to decrypt the data on the disk, then
to shred the disk is the same as throwing the key away.
Symlink
vs. Hard Link
i. Overview
Consider
the command ln -s d/a e/b,
which creates a symbolic link e/b that contains the file name
“d/a”.
And consider the command ln
d/a e/b,
which create a hard link e/b that points to the file d/a.
The
following figure illustrates the difference of creating a symbolic
link and a hard link.
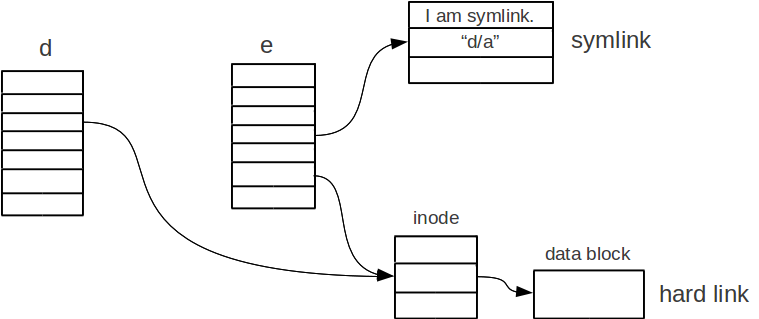
As
illustrated, when we create a symbolic link, we create an inode
that contains the file name of the file that we want to link
to.
When we create a hard link, we set the inode number to be the
inode of the file that we want to link to.
This will increase the
link count of that file by one.
ii.
Difference #1: Symlinks Can Dangle, Hard Links Can't
If
we remove the file “d/a” (assume that the link count has dropped
to zero), then we arrive at a dangling symlink.
And if we execute
the command cat e/b,
we will get a e/b not found error.
Hard links can't dangle
because before all the hard links are removed, the link count is
always greater than 0, and thus the file can not be freed.
iii.
Difference #2: Symlink Is Relative to the Containing Directory
The
following commands illustrate this point.
ln
-s foo d/x
ln d/x e/y
cat d/x
cat e/y
On
the first line, we create a symbolic link d/x that links to a file
named “foo”.
On the second line, we create a hard link e/y
that links to the symbolic link d/x.
On the third line, we try to
print out the content of the file the symbolic d/x links to. This is
command is equivalent to cat
d/foo.
On
the fourth line, we try to print out the content that e/y links to,
which is the symbolic link d/x.
Since now the containing
directory of the file is e, the command cat
e/y is
equivalent to the command cat
e/foo.
iv.
Difference #3: Symlinks Can Loop
If
we execute the command ln
-s / /usr
we will create a loop.
The following figure illustrates this
loop.

Then
the commands ls
-l /usr/bin
and ls
-l /usr/usr/usr/bin
etc. will be equivalent.
The following commands also create
loops.
ln
-s a b; ln -s b a
ln -s x x
When
we create the symbolic link, the program cannot detect the loop
because it's slow with a time complexity of O(N).
The program can
detect a loop when resolving a symbolic link.
If the program
follows 16 symbolic links and still cannot resolve the symbolic
link, it will give up.
And the function open(“symlink_file”,
…...);
will fail, and errno will be set to ELOOP.
Question: Why can't
hard links loop?
Answer: Since resolving hard links can be slow,
we don't allow hard link loops to be created.
Name
Lookup
For a
file “a/b/c”, we map the name components “a”, “b”, and
“c” to inodes.
If the file name “a/b/c” is given, the
system will assume that the directory a is in the current working
directory, which is stored in the process descriptor.
If the file
name “/a/b/c” is given, the file name knows that the directory a
is in the root directory.
The function chdir(“a/b”);
changes the process's working directory to a/b.
The function
chroot(“a/b”);
changes the process's root directory to a/b, and will result in
“chroot jail”.