Threads vs Processes
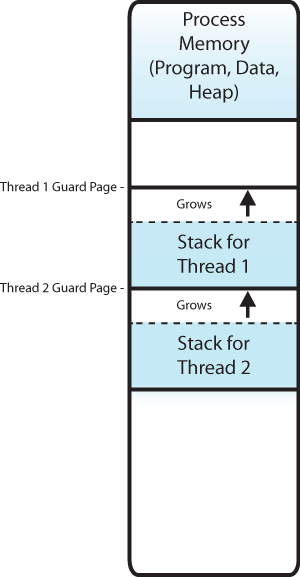
Threads are like processes. They share memory, file descriptors, owner, etc. They don’t share instruction pointers and registers as well as their stack.
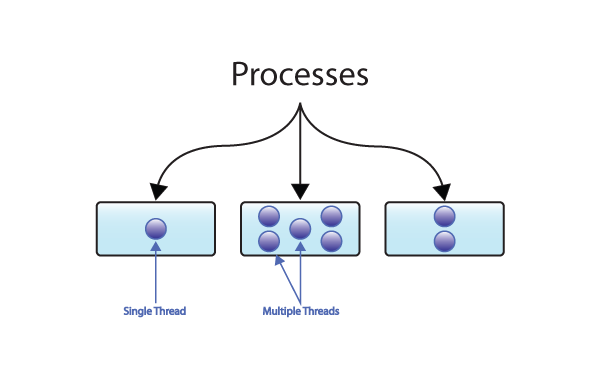
Differences between threads and processes:
- Processes are typically independent, while threads exist as subsets of a process
- Processes carry considerably more state information than threads, whereas multiple threads within a process share process state as well as memory and other resources
- Processes have separate address spaces, whereas threads share their address space
- Processes interact only through system-provided inter-process communication mechanisms
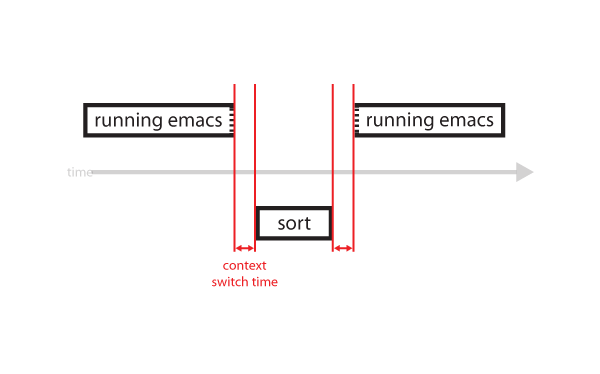
- Context switching between threads in the same process is typically faster than context switching between processes
Advantages & Disadvantages of Threads
+ speed: apply more CPUs to do the same thing
+ easier, faster interthread computations
+ modularization techniques: easy to split large program into smaller parts
- race conditions galore–especially because of shared memory; very hard to debug
POSIX Threads
POSIX threads are usually referred to as Pthreads. They are defined in the pthread.h header file. Pthreads are used to enable potential program performance gains. Compared to processes, threads are created with much less overhead and managed with less system resources.
int pthread_create( pthread_t *ID, const pthread_attr_t *attr, void * (*start_routine)(void*), void *arg); //like fork for processes
int pthread_join( pthread ID, void *status); //like waitpid
int pthread_exit(void* status)
Typically, the number of threads is greater than the number of CPUs.
There are generally two approaches to multithreading:
- Cooperative Multithreading: threads must cooperate with each other and wait on each other for resources
- Noncooperative/Preemptive Multithreading: the operating system determines when a context switch should occur. Can be buggy when a switch occurs at a bad time.
Cooperative Multithreading
Cooperative multithreading is when a thread voluntarily yields its control of CPU every now and then. The thread does this because it is aware that other threads are not running, so it cooperates by giving up its control of the CPU once the thread figures out its time is up. Cooperative multithreading relies on each thread to help out the scheduler by either issuing system calls or calling yield(). As a result, any large loops within the thread must have a yield() in it.
yield() tells the OS to give control to a different process. It is a system call that results in a trap–transfer control to the kernel.
When considering implementing I/O with cooperative multithreading, one must be careful not to have processes continuously wait for input (busy-waiting), which is very inefficient. There are two ways that was discussed when implementing I/O: polling and blocking.
Busy-waiting looks something like this:
while( busy(device) )
continue;
Busy waiting is very inefficient since it can’t wait for user input most of the time, unless for fast devices that have less than 10ms of wait.
Cooperative multithreading places too much trust in assuming each process will give up control to other processes–poorly implemented process can chew up resources and cause system to hang.
Polling is simply implementing yield() continuously throughout functions while waiting for a particular device to be available.
- when yield() is called, kernel gains control
- kernel “loops” through a list of processes for the next process that’s runnable
- after it finds a process, say process P, it loads P’s state into the registers
- instruction pointer points to P, which means we are currently running P
- when P calls yield(), the kernel saves P’s registers, and “loops” again
Polling looks a little like this:
while( busy(device) )
yield();
Polling has the disadvantage that if there are a lot of threads/devices, it takes a lot of time and resources to yield(), save process states, switch between kernel and processes, etc.
Blocking is a lot fancier. Blocking is actively having processes stop and wait for a particular resource to become available, since we don’t want threads accessing a resource when another thread is using it.
Resources include devices, pipes, or other processes.
To implement blocking, a queue of threads is implemented for each device. It stores and keeps track of the processes that are waiting for that device. The queue also determines which process to give control to when the device is interrupted (becomes available).
Associated with each process in the queue is additional information regarding its status, which also needs to be tracked.
Threads can have the state:
- RUNNING
- RUNNABLE (but not running)
- BLOCKED (waiting for a device)
When blocking, we also need to have code to generate an interrupt when the device changes status. For pipes, we need code to notify the OS of any changes. We also need to watch out for any system calls that might change process states.
When a device becomes available, a process must be taken off its wait queue and be unblocked.
Blocking looks something like this:
while( busy(device) )
wait_for_ready(device);
Blocking works better when you have 1000s of threads. However, it makes program much more complex. The OS is now required to keep track of which threads are associated for which device.
Preemptive Multithreading
Preemptive multithreading, or noncooperative multithreading, is when a thread can be interrupted during its execution by another thread. A timer on the motherboard periodically sends a signal to the CPU, which causes the CPU to trap via the clock interrupt entry in IDT and switch to kernel mode. The kernel saves the context of the “uncooperative” thread and then proceeds to manage scheduling before returning control to the process and restoring its context.
The timer sends a signal to the CPU every 10ns. This is fast enough so that it seems instantaneous to users, while slow enough so there is not too much waiting. If the timer were to be too fast (such as 1ns), there would be too much time spent switching and not enough time used for working.
Preemptive multithreading is generally considered superior to cooperative multithreading. Below is a list of Pros and Cons when compared to cooperative:
+ Does not need to assume other threads are cooperative. In cooperative multithreading, if a thread does not cooperate, the other threads will not get a chance to run, resulting in a system lockdown
+ No longer require yield() all over the place, making code more readable
- On the other hand, threads can no longer assume that the code without yield is “safe” (bad for realtime)
- More race conditions
Aside on Signals:
What happens when a signal is received in the middle of a system call (ie. during write)?
The normal solution would be to only deliver the signal when a system call is returned.
However, in the cases of slow system calls:
- system call fails with errno == EINTR and the application must retry.
- signal handlers fire in the middle of a system call
- kernel must now be able to resume a process that’s in the middle of a system call
Event-Driven Programming
Event-Driven programming is the “inverse” of multithreading: instead of dividing the program to be read by multiple threads, the program is divided into chunks of code known as callbacks. Callbacks are executable code passed as an argument and are triggered by a specific event. Callbacks never block (read, write, waitpid) and thus never wait. Instead, a scheduler needs to schedule a request, such as aio_read() which schedules a read request. Once the read is done, a callback is invoked.
An example of callback:
for(;;)
{
pselect(...) //wait for event
invoke its callback;
}
Pros and Cons (when compared to multithreading):
+ less race conditions
- uses only one core
- complex and difficult to read

Scheduling
Scheduling Problem:
Because often times, the number of threads users want to run is larger than the number of CPUs that exist, the OS needs to know which CPU needs to run which thread, and for how long. The way this is done is through mechanisms and policies:
mechanism – how a policy is done: details of the clock interrupt, thread descriptor, RETI to resume a thread
policies – what needs to be done, or the rules that decide which to run: first-come first-serve, shortest job first, etc.
Scheduling is not just limited to CPU. Other examples include scheduling the disk arm, a network device, or even the manufacturing of cars.
Scheduling Scale:
long term – which processes or threads will admit to the system? (Admission control)
medium term – which processes reside in RAM? Which on disk?
short term a.k.a. the dispatching problem – which process gets the CPU? aims for the simplest and fastest algorithm (two qualities which compete with each other)
Scheduling Metrics:
wait time – the time it takes from the job request arriving to actually starting the job
response time – the time it takes from the job request arriving to seeing the first visible result
turnaround time – the time it takes from the job request arriving to finishing the job request
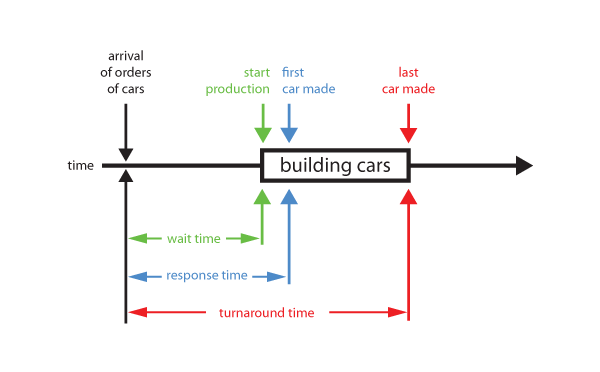
Scheduling Statistics:
average time case – how long the wait and turnaround times usually take
worst time case – the worst case scenario for how long the wait and turnaround can take
utilization – percent of the CPU devoted to useful work (work that is not useful would be like context switching)
throughput – the amount of work done per time (e.g. number of cars produced in a day)
Scheduling Algorithms:
First-Come, First-Serve (FCFS) – A policy that addresses requests by order of arrival
+ Favors long jobs
- Convoy effect (handling long jobs causes a long list of other jobs to wait)
Example:
Arrival Order:
{AAAAA}
. {BB}
. . {CCCCCCCCC}
. . . {DDDD}
Run Order:
Δ {AAAAA} Δ {BB} Δ {CCCCCCCCC} Δ {DDDD}
| Job | Arrival | Run | Wait | Turnaround | Utilization |
| A | 0 | 5 | Δ | 5 + Δ | |
| B | 1 | 2 | 4 + 2Δ | 6 + 2Δ | |
| C | 2 | 9 | 5 + 3Δ | 14 + 3Δ | |
| D | 3 | 4 | 13 + 4Δ | 17 + 4Δ | |
| Average | 5.5 + 2.5Δ | 14.5 + 2.5Δ | |||
| 20/(20 + 4Δ) |
FCFS services A’s first, then B’s, then C’s, and then finally D’s. Between each job, context switching is required, which is denoted by delta (Δ).
Shortest Job First (SJF) – A policy that addresses arrived requests by the length of their run time
+ No convoy effect
- Starvation, not fair (short jobs will always cause long jobs to wait)
Example:
Arrival Order:
{AAAAA}
. {BB}
. . {CCCCCCCCC}
. . . {DDDD}
Run Order:
Δ {AAAAA} Δ {BB} Δ {DDDD} Δ {CCCCCCCCC}
| Job | Arrival | Run | Wait | Turnaround | Utilization |
| A | 0 | 5 | Δ | 5 + Δ | |
| B | 1 | 2 | 4 + 2Δ | 6 + 2Δ | |
| C | 2 | 9 | 9 + 4Δ | 18 + 4Δ | |
| D | 3 | 4 | 4 + 3Δ | 8 + 3Δ | |
| Average | 4.25 + 2.5Δ | 9.25 + 2.5Δ | |||
| 20/(20 + 4Δ) |
Although the request for B’s is the shortest, at time 0, B has not arrived yet, so the request for A’s is serviced first. Because D’s arrive before B’s finishes, SJF sees that D’s have a shorter runtime than C’s and chooses to service that first.
Notice that, for the average wait and turnaround time, SJF < FCFS. However, remember that with SJF, long jobs can be starved.