
CS 111 Scribe Notes: Tuesday, Week 8
By Preston Chan, Tai-Lin Chu, and Jay Chen
File system's miscellaneous invariants
Consequences of violating invariants
Fixing violations of invariant 4: storage leak
Cascading Aborts versus Compensating Actions
A C-ish explanation of physical memory lookup
In order to make sure our file system works, there are certain conditions that must be met.
All must be true at all times. If invariants hold before an operation, they will still hold after an operation is performed.
Violating invariant 1: Someone wrote over the bitmap
You could lose data because used block might be marked as free. If someone writes a new file, the file system may allocate new data to the used blocking, thinking it was free to use.
Violating invariant 2: Inode points to garbage indirect block
Files will be overwritten by two different programs because the filesystem will believe that the blocks are still valid.
Violating invariant 3: Used block marked as free
If a new file is allocated, this block might be used, so the data which is originally in this block is overwritten.
Violating invariant 4: Some unreferenced blocks are marked as used
This is a storage leak, but there is no data loss. This problem is not disastrous, and can be corrected
Violating invariant 4 is not a disaster. It will cause storage leak, as usable space will not be reallocated, but no data will be lost.
The storage leak could occur during the changing of the link count on a data block. For example, when we rename a file, we follow the following steps:
1. Create a new directory entry in the destination directory and point it to the inode of the file.
2. Increment the link count of the inode.
3. Delete the old directory entry in the source directory that pointed to the inode.
4. Decrement the link count of the inode.
Now, if this process was cut short between stages 3 and 4, a storage leak may occur. Even though we already deleted the original inode, we did not decrement the link count. Later, when inodes references that data block is deleted and the link counts is decremented accordingly, the link count will still be 1, and so the file system will think that this data block is being used by someone else. Because of this, it will never reallocate this data block, when in reality, it should be.
This leak can be fixed by a file system check (fsck). Fsck looks for inconsistent states in the file system, and will fix errors such as incorrect link counts.
An fsck must be idempotent, meaning it can be applied multiple times without changing the result beyond the initial application. It cannot assume that all of its actions will be executed - it could lose power while running. It cannot use ordinary system calls because fsck is operating system independent - it uses only the file system. Modifies file systems directly without the use of operating system. Looks at super block, bitmap, inodes, directory data blocks, indirect data blocks. To improve performance, we skip data blocks of regular files because those data blocks have nothing to do with filesystem structure.
When fsck places lost or possibly corrupted files into a special directory called lost and found. Files in the lost and found include inodes that were supposed to be removed earlier but still exist, or files that were possibly corrupted
Possible sequence of writes that might result in violating invariants:
This corresponds to our previous example for renaming a file: we first remove an entry in directory block 1, and update the file's inode entry (increase the link count). The second step is to write a new entry in directory block 2, and decrement the inode link count. It is essential to let this happen in sequence to preserve invariants. But what if we use the elevator algorithm for writes? Let's see what will happen if we would try to improve performance by reordering writes. For example, we first remove inode entry by writing to directory block 1. Then we increment the link count. But because the writes happen in the same inode block, the elevator algorithm could decrement the link count immediately. The last step is to write the new entry to directory block 2. This can mess up the careful ordering of writes required for preserving file system invariants
Solutions:
At high level, it looks like the following diagram, but this makes a sequence of high level writes really slow.

Cascading Aborts: Low level aborts cause a higher level operation to fail. It is safer because high level operations must wait for the lower level operations to finish, and so every operation will know precisely whether or not it succeeded or not. Because the higher level operations must wait for the lower level operations, the system becomes much slower
Compensating Actions: Assume all lower level operations succeed and get a notification later that a lower level operation failed. The low level failed is assumed to be rare. Because all operations usually succeed, we gain a boost in performance. Unusually, applications need to be able to repair failures.
Code example:
Because no one can write perfect code, it is better to have an extra level of protection towards unreliable processes that may access bad memory. Multiple processes can each now access a private "memory location 1000", whose value differs from process to process. Processes can now exceeds physical memory by using part of disk space as virtual memory. Multiple processes can now control the sharing of memory (very slow if you thrash)
What are the alternatives to virtual memory?
Here is our initial attempt:
Each access to memory must be between base and bound. Attempting to access out of this range results in a trap. This check is fast in hardware, as it can be performed in parallel.
Pros
Cons

To solve the first two cons above, we try...
We divide an ordinary base and bound chunk into multiple base-bounds pairs.
Pros
Cons
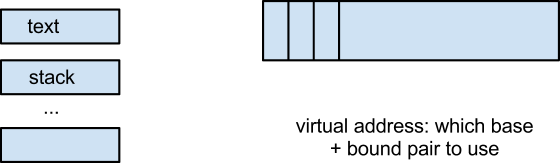
This is called "segmentation". The idea is to split into segments, where each segment varies in size. Segments can have extra settings (read only, which only costs one bit). But evil people might change base-bounds register values. This can be fixed by making them privileged, and we should make all segment registers privileged.
Growing a segment can be hard because segment needs to be contiguous. To improve this, we can use the same technique for disks like the RT-11 file system. We can break segments into pages (say 8kb) like disk blocks.
With this strategy, growing is easy because all data is divided into smaller partitions, and os can point virtual address to page. We can add a page or remove a page with appropriate size. There is no external fragmentation because now the process has data scattered with several small fixed-size chunks in ram. Each process has its own virtual address space. Operating system prepares physical memory or disk space and divides them into pages. The OS assigns pages to the process in background.
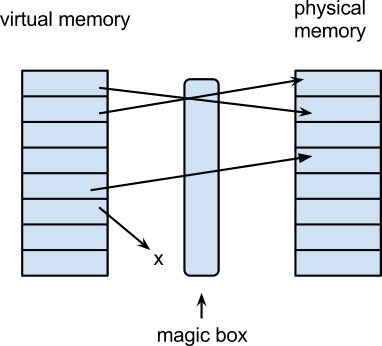
Each process uses virtual address to access the data. The lookup happens by using the page number and offset to look up entries of page table. The entry of page table points to data in the physical memory. The memory appears to be contiguous to the application, but in reality there are pages scattered in physical memory and disk.

Our function here is an example of the magic box from the previous diagram. To obtain the physical page number from a virtual page number, the user would just use the pmap function, which looks into the page table to find the physical page number.
END OF NOTE