CS 111 Lecture 13: File System Robustness
scribed by Eric Sun and Daniel Kwasnick
Table of Contents:
How do we ensure our system is reliable?
We can expect that things will go wrong in our system; it is up to us to handle these cases accordingly. All systems are built out of components, and each of these components is a system of its own.
Depending on the assumptions we make about the components of our system, there are two ways to accomplish reliability:
- Pick/build super reliable components and combine them.
Reliability is solved at the interfacing level. We do not have to worry about the system inside of each component. We can design our file system assuming each one of our components runs perfectly. -
Assume the components are unreliable.
Reliability is solved within each component. We deal with the problems of each component on a case by case basis.
Example:
Let's say we get an error with our disk controller cache (spontaneous errors). We read the block into the cache and the read operation completes perfectly. However, the cache breaks when we try to retrieve it later.
Method 1) Put error checking inside the cache
- The cache itself can maintain checksums on each block inside of the disk to verify data integrity.
Method 2) Assume the disk controller will go bad
- Write error checking code in the file system, maintain a checksum for each file on the disk. We store the checksums on disk, load them into memory and then perform the check on our data.
Which method should we use?
Reliability applies to anything that you're building. Google succeeded early on by choosing method 2. They bought the cheapest file servers possible with zero reliability checking, and then wrote software that would perform error checking. They saved a lot of money this way.
The method depends on what resources you have available and what your end goal is.
What can go wrong when the user accesses data?
Problems that occur in our system can be categorized into external and internal events:
-
External events consist of events that occur outside of our server:
- Bad user request: buffer overflow, bad packets
- Unintentional removes/updates (rm * .o vs rm *.o)
- Power failure: system shuts down unexpectedly.
- Server overload: many many requests, overwhelming the system
-
Internal events consist of events that occur inside the server:
- Disk error range overwhelms internal checksums. In this case, the file system isn't sure what to do with a bad block.
- Bit flip in the controller cache.
-
Bit flips in RAM due to gamma rays
Gamma rays can pass through our components and set or unset arbitrary bits within our system.
Servers typically have ECC (error correction bits) since they need to run for extended periods of time. Adding ECC adds around $5 to the cost of RAM, and nobody wants to pay that much more for laptop or desktop RAM.
- Disk head crash. Physical scraping of disks destroys your data. This is really bad.
Enforcing reliability: dealing with power failures
Assuming a power failure occurs, we can deal with it using our reliability methods.
Method 1)
We can get a better power supply, or use an uninterruptible power supply (UPS). In reality, there is no such thing as a UPS. It is just a back up battery that can also fail as well.
Method 2)
We can build a system that is reliable in overall behavior even if individual components fail
in the presence of power failure.
We can implement our file system such that a power loss does not result in data loss.
(after-reboot data = just before crash data).
Implementation of the Reliable File System
We have a simple text file containing the grades of all CS111 students: cs111grad.txt.
Assumptions:
The file is of fixed size: 20000 bytes.
We always read the entire file or write the entire file using the following functions:
read(fd, buf, 20000); //Loads data into grading application. Like LD operation.
write(fd, buf, 20000); //Writes data into the grading application. Like SAVE operation.
The implementation for read is straightforward; the implementation for write is not. Here is the inode structure of a file in Linux:
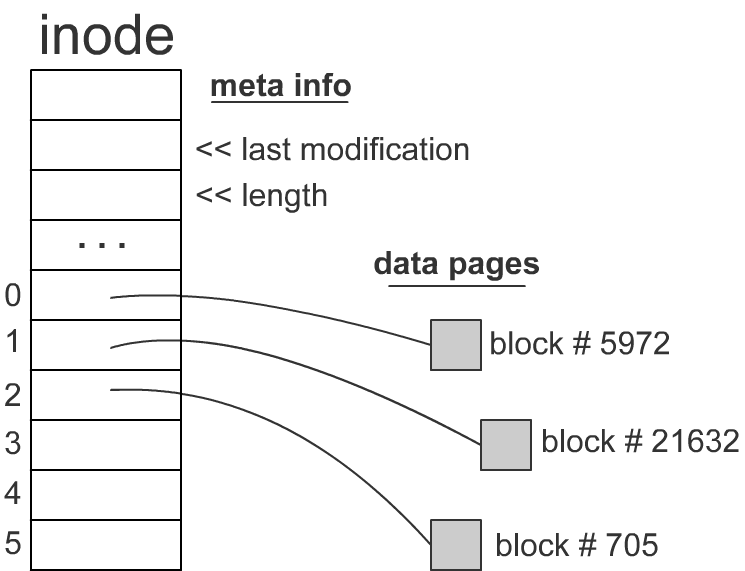
We cannot assume that writes are atomic. When we issue a write request, that request may be split up into write chunks of 512B, 1024B, etc depending on the behavior of the disk controller.
We have some consistency issues: 1) data vs metadata, and 2) data vs data (different parts).
1) If our power goes out after we have finished writing to our data blocks, but before we finish writing to our meta data, the file will look like it was not modified even though it was.
2) If the power goes out in the middle of writing to a data block, we might not allocate the necessary indirect or doubly indirect block.
Golden Rule of Atomicity
Never overwrite your only copy unless your underlying write operation is known to be atomic.
So how do we update something when the underlying system is not atomic?
Attempt 1: One temporary copy
We can change our application so it maintains two copies of the file: a main copy and a temp copy.
We will overwrite the temporary copy first, and then we will overwrite the main copy.

If A and B disagree, we could say that MAIN.txt is the correct version. However, this is incorrect as there is no way to guarantee if MAIN.txt is correct after it begins to get overwritten.
Attempt 2: Two temporary copies
If two didn't work...
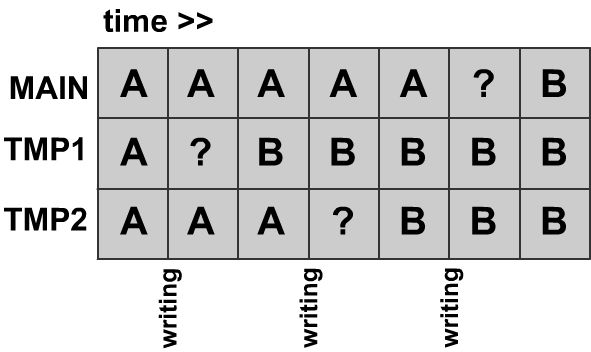
Using three files will work. We look at all three copies and select the file where the majority rules (two out of three match). If all three disagree, then we pick TMP1.txt. This works because we know TMP1.txt will not be written to after that particular case. We can then pick up where we left off on the next read.
But this is too slow and it eats up too much space!
Attempt 3: COMMIT record
Instead of using a third copy of the original file, we will use a COMMIT block which will keep track of which one of your copies is correct copy to reference.
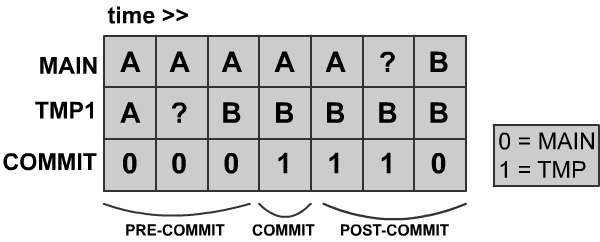
If the commit record is 0: look at MAIN.txt.
If it is 1: look at TMP.txt.
When we want to preserve atomicity in a system, we make several assumptions about our system.
Lampson-Sturgis Assumptions:
- Storage writes may fail and may corrupt other blocks
- Later reads can detect bad writes
- Storage can spontaneously decay, but a later read scan still detect it
- Errors are rare
- Individual sector writes are atomic
Based on these principles, we have a generic algorithm for solving atomicity for high-level operations:
BEGIN -Do pre-commit actions: These are low level operations that may or may not be atomic. At this stage, the high level operation has not yet happened. We can prepare for the higher level operation, OR back out of these operations and leave no trace of the higher level operation. ex) When COMM is 0. -COMMIT: An atomic operation at the lower level. It tell us to begin ovewriting main. (higher level operation). ex) first two 1s -POST COMMIT phase: high level operation has already occurred. Cannot change our minds. But we can improve performance for the next time around. ex) COMM's last 1. DONE
Journaling
Journaling is originally taken from double entry book keeping in accounting. The idea is that we never erase any data (append-only) and that we log all of our operations.
The purpose of the journal is to emulate the effect of atomic writes even if the underlying system does not support atomic writes. We can accomplish this by combining the journal with the cell storage.
Our journal will hold the following information:
- Commit
- Pre-commit
- Post-commit
Implementation: Write-ahead log
One way to accomplish this is through a simple logging protocol, called a write-ahead log:
Suppose we are trying to change an A in the cell to B:

- Log into journal our intent to change block #27 to B.
- Write a COMMIT to the journal.
- Write changed blocks to cell storage.
- Clear the commit record (DONE)
Note: If you look at the most recent entry in the journal it talks about values that aren't there yet.
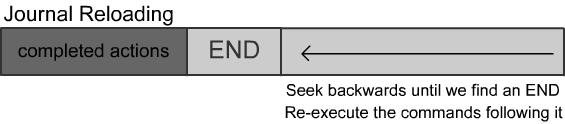
Recovering from a power failure
In the case of a power failure, we scan the journal left to right looking for COMMITs that aren't DONE.
We then apply the necessary changes one by one for unfinished writes.
Advantages
- We can have journal on one drive and cell storage on another drive. Drive 1 has no seek time. (append only)
- Drive 2 is not strictly necessary; we can keep our storage in RAM.
For larger file systems, RAM is a cache of actual cell storage. This approach is used more often in databases; main memory databases don't live on disk so as to not incur a large amount of disk I/O operations.
Implementation: write-behind log
The write-behind log reverses the order:
- Log into journal the old value of block 27, 'A'.
- Install B into the cell storage.
- Do a COMMIT.
Recovering from a power failure
We scan backwards through the log, looking for uncommitted operations, undoing as we go.
Advantages/Disadvantages:
Pros:
- Can be faster because you can undo immediately.
Cons:
- We must have old values in the journal, which might actually have to be grabbed from the disk.
Atomic Rename
We will implement the algorithm for a rename as follows:
1) Get d's inode into RAM (assume D's inode pointers directly to the data) 2) Get d's data 3) Get e's inode (make sure it's a directory) 4) Get e's data because there are other directory entries that we have to write out 5) Update d's data in memory 6) Do the same for e 7) Write out d's data 8) Write out e's data
Assuming we crash in between steps 7 and 8, we run into a problem:
We've deleted d/f, but we haven't created e/g: we've lost our original file.
This is easily solved if we write out E's data first and then D's data afterwards.
But what if we have two directory entries to a file whose link count is 1?
This may result in a dangling hard link because two hard links link to the same file. If
we remove one of them, the link count will drop to zero.
We can fix this by adjusting our previous algorithm:
1)Load f's inode into RAM 1) Get d's inode into RAM (assume D's inode pointers directly to the data) 2) Get d's data 3) Get e's inode (make sure it's a directory) 4) Get e's data because there are other directory entries that we have to write out 5) Update d's data in memory 6) Do the same for e 7) Write out d's data 8) Write f's inode with link count after last update 9) Write f's inode again to fix link count 10) Write out e's data
Now we won't have consistencies in a file system that will cause crashes later. We can still have the link count at 2 while we have 1 hard link. However, this is still a problem because when we remove this file, its space will not be reclaimed. This will cause a space leak. Our system now will not crash due to such an error. To accoun for it, we can always run a file system checker later on our disk.