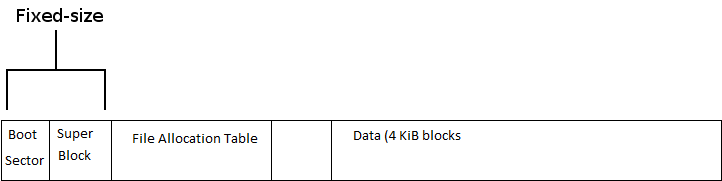
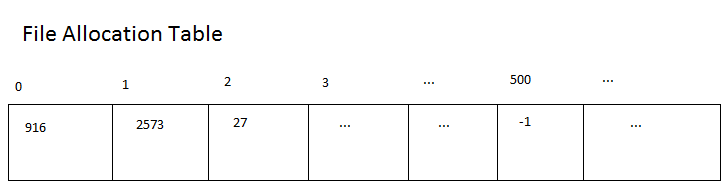
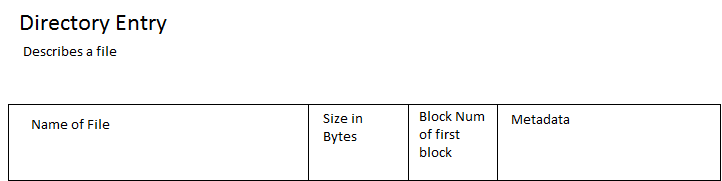
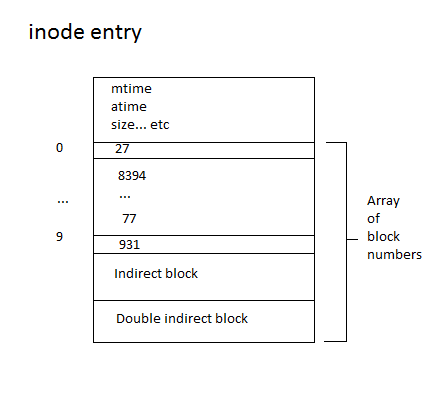
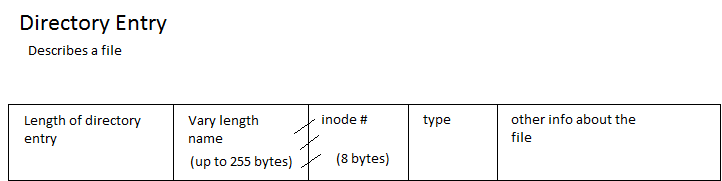
Disk Scheduling Algorithms
Let us assume a simple disk model:

The cost of a reading the data at track b is |b - h|,
ignoring latency, waiting for the disk to rotate to the data,
and acceleration of the disk head.
1) First-Come, First-Serve
Handles requests in a simple queue.
Assuming that the data is uniformly distributed, the average cost of random access for each h can be graphed as such:
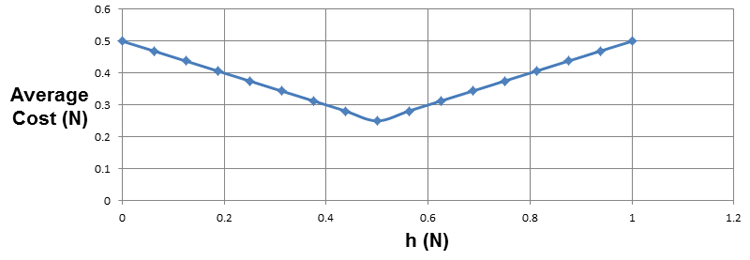
Integrating the graph gives us the average cost of random access:
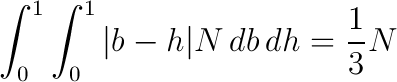
This is pretty expensive!
2) Shortest Seek Time First
Always schedules closest request to disk head.
- +Better thoroughput by minimal seeks.
- –May cause starvation of farther jobs if close requests keep getting scheduled.
Now we seek inspiration from elevators. After all, elevator operators have handled the same problem long before OS programmers...
3) Elevator Algorithm
Tries to keep going in the same direction until we run out of jobs in that direction.
- +More fair...
- –...However, requests for data on the ends may have to wait for the disk head to go to the other end then come back.
4) Circular Elevator Algorithm
Like the Elevator Algorithm, but it keeps going in the positive direction and immediately goes back to the lowest job when it reaches the end.
- +Completely fair and consistent — good for real-time applications.
- –Overhead of going to highest job, then back to lowest job.
Example
Assume that the disk head is currently at cylinder 100, and cylinders 101, 98, 200, 96 requested in that order.
Here's what the algorithms above will do, and why:
| Step | FCFS | SSTF | Elevator | Circular Elevator |
|---|---|---|---|---|
| 1 | 101 1st job |
101 closest job |
101 closest job |
101 closest job |
| 2 | 98 2nd job |
98 closest job |
200 same direction |
200 positive direction |
| 3 | 200 3rd job |
96 closest job |
98 closest job in other direction |
96 lowest job |
| 4 | 96 4th job |
200 closest job |
96 same direction |
98 positive direction |
| Total Cost | 210 | 110 | 204 | 206 |
Problem With The Above Algorithms
They can't see the future! Suppose we have two processes that read files starting at cylinders 100 and 200, respectively:
| OS | Process 1 | Process 2 |
|---|---|---|
| Waiting for request | Request cylinder 100 | Request cylinder 200 |
| Go to cylinder 100, queued request for cylinder 200 | Request cylinder 101 | Waiting for OS |
| Go to cylinder 200, queued request for cylinder 101 | Waiting for OS | Request cylinder 201 |
| Go to cylinder 101, queued request for cylinder 201 | Request cylinder 102 | Waiting for OS |
| Go to cylinder 201, queued request for cylinder 102 | Waiting for OS | Request cylinder 202 |
And so on...All of the algorithms above will go back and forth because they don't know that the processes will request more cylinders close by.
5) Anticipatory Scheduling
After fulfulling a request, wait (for ~0.1 ms) in case the process wants to request more accesses close by.
- +Solves the problem described above.
- –Like SSTF, this may cause starvation if one process keeps requesting accesses close by. For example, a media player continuously reads music/movie data.