CS111
by Liem Do
Lector 10: System Performance
BASIC IMPLEMENTATION OF LOCK/UNLOCK
We begin by examining a simple function to write to a pipe with blocking mutex. Recalling that the idea behind blocking mutex is to grab a lock if it is available or release the CPU.
void writec(struct pipe *p, char c) {
acquire(&p->v);
// write a byte
release(&p->b);
}
struct pipe {
bmutex_t b;
}
We have to tell the kernel we are not only waiting on an object O but we are also waiting for an event condition C, a condition variable. So below is a revised version:
void writec(struct pipe * p, char c) {
acquire(&p->v, p->nonfull);
// write a byte
release(&p->b);
}
struct pipe
{
bmutex_t b;
condvar_t nonfull, nonempty;
// The write pointer minus the read pointer less than the size of buffer
size_t r, w;
char buff [N];
}
we need a condition defining the variable, a blocking mutex protecting this condition, a condition variable standing for this. Consequently, we added the condition to our structure.
After we modified the structure, we need API:
- wait(conduct_t *c, bmutex_t *b); // bmutex waits for conduct_t to become true, gives up the block, wait and reacquire.
- notify(condvor_t *c) // Notify one process about a condition
- notifyAll(..) // Notify all the processes
void writec(struct pipe *p, char c)
{
acquire(&p->v, pipe->nonfull);
while(p->w - p-> == N)
wait(&p>nonfull, &p->b);
// not full, write to the pipe
notify(&p->;nonempty);
realease(&p->b);
}
CLASSIC SYNCHRONIZATION
Semaphore can be used to effectively avoid synchronization problem. In this technique, we block the mutex with int but not bool. By doing this, we can share with n (integer) people who are trying to access the resource. That means the object is locked when counter equals to 0 or unlocked when the counter is greater than 0.
DEAD LOCK
Dead lock itself is a race condition. In most cases, the dead lock occurs when processes lock each other. The interesting thing about dead lock is it is actually the cost to avoid race condition. Dead lock is hard to debug because it does not happen very often.
Four conditions needed for deadlock:
- Circular wait: a process that waits for something and eventually other processes in the chain waits for the first process.
- Mutual exclusion
- No preemption of locks: often happens when there is an important object that is not released
- Cannot hold and wait for others
We can decrease the deadlock by reengineer to eliminate as many as conditions above.
STRATEGIES TO AVOID DEADLOCK
- Write perfect code: not really a real strategy
- Each thread holds at most one lock
* Downside: no balance transfers because we have to lock both read and write end. - Lock preemption: gain the lock from other processes by forcing
* Downside: it is tricky - Acquire checks for circular wait
* Downside: If there is a loop, acquire fails. It slows down acquire and complicates the user code - Lock ordering
If you need to acquire more than one lock, you get the lock in numeric order (eg. Their address). The following code demonstrates this observation.
/* if fails, we release all the locks */
for (i = 0; i < 5; i++)
{
if (try_acquire(&l[i]) < 0)
for (j = 0; j < i; j++)
release(&l[j]);
i = -1;
}
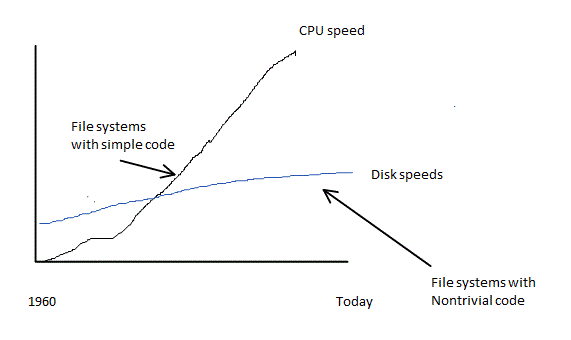
FILE SYSTEM PERFORMANCE
Barracuda XT 3TB |
Corsair Force SSD 120 GB |
Cost: $200 Sustained data transfer rate: 138 Mb/s
Average latency: 4,16ms
Random read seek time: 8.5ms
Random write seek time: 9.5ms
Unreadable read errors: 1 in 10^14 Average operating power: 9.23 W Average idle power: 6.29W |
Cost: $150
0.5 W |

Diagram labeling the major components of a computer hard disk drive
Barracuda XT 3TB ST 330000 5N1A5AS Capacity: 3TB = 3 * 10^12 bytes Cache: 64MB -> The cache/disk ratio is really small Sectors: 3, 907, 029, 168 Spin speed: 7200 rpm = 120Hz I/O data transfer rate: 600MB/s |
0.4 ms (off disk) 0.1 ms CPU overhead --------------------------------------------- 13.72ms = 70 bytes/sec |
Even though Corsair Force SSD is a lot faster than Barracuda XT, HDD is still a good choice now because of its price.
I/O PERFORMANCE ISSUES
With a hard drive that has I/O data transfer rate: 600 MB/s and interface speed: 6 Mb/s, how can we improve our read() function?
The answer is we can use a buffer read(fd, buf, 1024). But the question here is how large the buffer can be? If we increase the buffer size to 1GB, the seek time will grow as we read more sectors now. The CPU overhead time also grows. Furthermore, we're forcing the program to read more data than it needs.
User sees: read(fd, &c, 1)
OS sees: sys_read(disk, buf, 1024*1024*1024);
Another approach is to read more data than requested. By combining with some algorithms that can guess which data will be fetched next, we can significantly reduce the latency. But please keep in mind that when the throughput goes up, latency goes down.
Throughput |
Latency |
70 bytes/s |
1372 ms |
70 KB/s |
1372 ms |
130 MB/s |
7017 ms |
In most system, they don't go with too big block because it increases the latency.
Direct memory access - DMA
This is a feature that allows subsystems to access memory without sending the request to CPU, causing an interrupt so CPU causes next IO request. The interrupt = INT + RETI + etc… will take a lot of CPU. By using DMA with no interrupt, the CPU just pulls the device when needed.
DISK SCHEDULING
CPU is a limited resource and shared among different processes. We have a lot of accesses to the same disk from multiple processes. We need to figure out the correct order.
The following is a list of what we want out of disk scheduling:
- High throughput
- Low latency
- Fairness
- R1: fast, R2: slow
Spring 2012 UCLA - CS 111 - Professor Paul Eggert