CS 111Scribe Notes for 5/25/10by Insoo Jeon, Rita Liu, Kevin Delavega
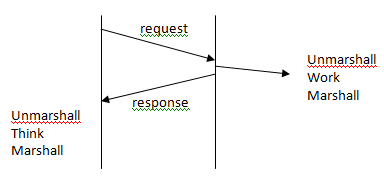
RPC Performance Issues (again) There is a performance problem due to high transmission delay Possible solutions: 1. batching: ask for more data per request
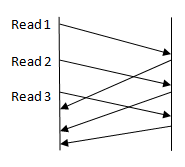
Client Server 2. asynchronous requests (HTTP pipelining) * What if requests depend on each other? * What if one request fails? (this can be tricky)
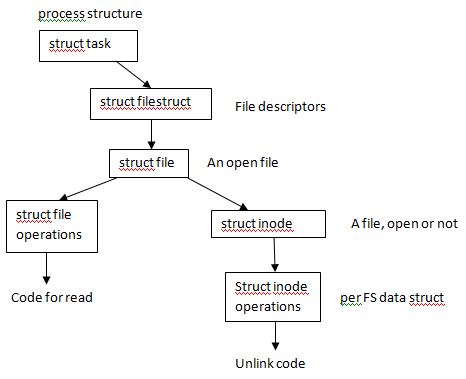
Linux Virtual File System
Can we support multiple kinds of file systems? * Yes - FAT, ext4, ext3 - all on the same machine.
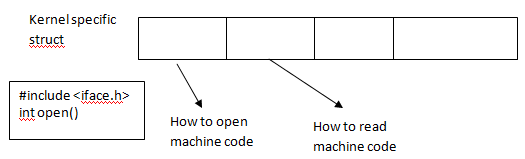
Use object oriented programming: * Kernel specifies an interface * Each file system implements that interface * Drawback: C isn't object-oriented!
Kernel: iface.h
* Kernel.org : Best Reference so far!.
kernel specifies a struct * Code contains how to open the FS and how to read the FS
NFS (Network File System)
Client process
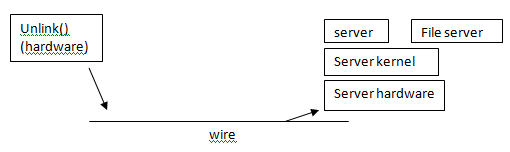
NFS problems and design issues * Lost packets -> resend request (no harm done if idempotent) * We can lose transactions implemented via link
* Suppose, there is no B Server caches a limited number of resent requests * reports "OK" if it gets a duplicate from the same client. * Note: NFS is not POSIX-Compliant
"Stateless" Server Contents of server RAM doesn't matter. If server reboots, then clients wait.
+ Advantages: simple, reliable - Disadvantages: removing a file can take a while. * Notice that we might want to use control-C to stop the removing process, but we cannot -- we would need complicated mechanism in our file system to deal with interrupts and signals. Now by default it's not interruptible.
NFS file handle (which is used by NFS protocol) * uniquely identifies a file on a server * persists if server reboots
unix: dev_t + ino_t + serial number, where dev_t = file system ID (on server) ino_t = inode number (on server) serial number (nth time you've created this inode #)
NFS protocol (Unix filesystem on wheels) LOOKUP(dirfh, "name") -> fh + attributes CREATE(dirfh, "name", attrs) -> fh + attributes MKDIR(dirfh, "name", attrs) -> fh + attributes REMOVE(dirfh, "name") -> status READ(fh) -> data + status WRITE(fh, data) -> status (where dirfh = file handle of dir, fh=file handle for file in that dir)
CIFS(Windows filesystem on wheels) Samba server supports CIFS atop Unix filesystem.
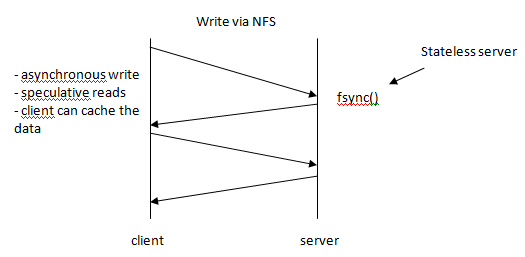
Write Via NFS
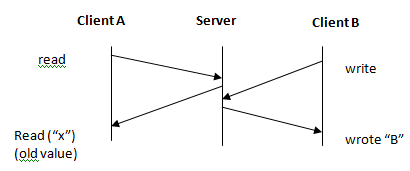
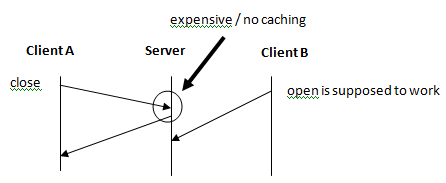
* inconsistent view of data * cannot assume file contents are synchronized writes + reads
* NFS does attempt to have those to open consistency
What else can go wrong? * Power failures: careful writes or a log * Network failures: hardway cache + replay * Media failures: (assume: single point of failure) Like 1 drive fails, use RAID
RAID: redundant array of independent disks
Types of RAID * RAID 0: concatenation Interleaved (striping) Faster I/O reliability
(easy to add disks)
* RAID 1: mirroring (prevent single point failure) Write to both, read from either + faster, read
(write to both, read from either one)
* RAID 4: Easy to add disk (All 0's for new disk; no need to recalculate parity drive)
F= A^B^C^D^E (XOR) <- It's hot! common I/O bottleneck Suppose B is lost, we can recomputed the data of B using the other sector B= A^C^D^E^(A^B^C^D^E^) <-> F(from parity disk) B= A^A^C^C^D^D^E^E(B^) B= B <- got B back
* RAID 5 = RAID 4 (without parity disk) + striping Note: parity disk implemented in physical disk + No I/O bottleneck - Hard to add disk + less fault
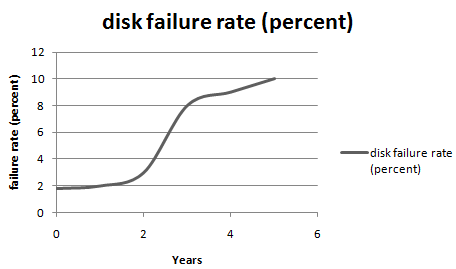
What's the disk failure rate?
* annualized failure rate
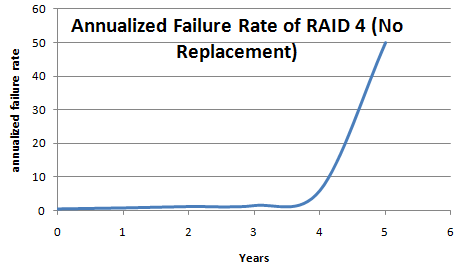
* 50% AFR of RAID 4
MTTR on RAID 4 (mean Time to Repair) 1. Hear alert 2. Walk to machine room 3. Find a good drive bad drive 4. Take bad drive out 5. Put in new drive near 6. Rebuild on good drive <- can take hours!
* Note: solid-state disk is good but expensive
|


CS111 Operating Systems Principles, UCLA. Prof. Paul Eggert. May 25, 2010.