
Lecture 14: Virtual memory
5/18/2010
By Karlson Yuen
Ext4: Linux File System
Where ext4 departs from traditional linux file allocation?
Ordinary UNIX/BSD/ext1-3/
1) allocates blocks one at a time
2) allocates when write() requires it
ext4 breaks that tradition
We try to:
1) allocate blocks several at a time
extent: contiguous sections (128MiB) of blocks, each of size 4KiB
Advantages:
+batching
+contiguous data
2) introduce delayed allocation
look at all processes that requests read
or write. Extents are not created may be until later, when it is time to flush to disk from RAM
Advantages:
+layout
data more intelligently, more information is collected before layout
Disadvantages:
-more race conditions can occur, resulting
in higher chance to lose data
-more RAM is needed
-extents are too large that will cause
more external fragmentation
-searching for free space can take
more CPU time for big contiguous blocks
ext4 basically has the same bitmap as ext3
Example on race condition:
fd = open("f.new", O_WRONLY);
Then do a bunch of writes
write(fd,...);
rename("f.new", "f");
But there is a problem here. Disk data area of "f" might not be allocated yet due to delay allocation
Fix to the above problem: inserting fdatasync(fd);
between write(fd,...); and
rename("f.new", "f");
Note:
fdatasync(fd) forces all currently I/O operations associated with the file
indicated by file descriptor fd to the synchronised I/O completion state. (source:
The Open Group)
People developed a system to recognize this pattern and automatically call fdatasync(fd);
New sys calls:
fallocate(fd, 128*1024*1024);
Note: fallocate(int
fd, int mode, off_t offset, off_t len) allows the caller to directly manipulate
the allocated disk space for the file referred to by fd
for the byte range starting at offset and continuing
for len bytes. (source: Kernel.org)
Dumd question: Installing ext4 filesystem
in a flash drive? Good idea? Why not?
Assume that we always unmount the drive before pulling it out.
In that case, OS makes sure all delay writes have been written to the flash drive
Answer: Extents no longer work well for flash disk!
Atomicity
Atomic Actions: an alternative approach
let users (or other operations) see inside pending result of this action.
Scenrio:
action 1: written data but no yet committed
action
2: wants to read data
Idea: go ahead and read data (not committed yet). If action 1 fails, action 2 fails as well
We can have cascading aborts. That means abort on one operation
can cause abort on another operation. Hope: the chain of operations is not too long
or compensation actions that attempt to fix up after cascaded abort.
Pros and cons:
+performance->maximum parallelism
-complicated!
Virtual Memory
What is the problem?
Introduced as a sales pitch. You have a program that wants
more memory than the RAM has. You can buy this feature and save money on RAM!
In reality, this does not work!
Performance is too bad.
If application has random access to RAM and its ratio of virtual
to physical is V/P
then probability of access requiring a disk
read is (V-P)/V.
thrashing app = dead app
cost to access disk page: ~5ms
cost to access RAM: ~100ns
ratio between these two costs is 50,000:1!
If V/P = 2, you are dead!
One may be tempted to conclude that Virtual Memory is a total crock!
Why do we still need it?
1) Some programs may want more memory that the RAM has
2) Protection-unreliable programs may crash a lot
one solution: Fire your programmers, hire
better ones! But the better ones are expensive+rare+busy!
we want programs to not crash into another
program, not crash into the kernel and not stomp into others' memory
3) Portability/Flexibilty
run several programs at the same time without
having to rebuild them
4) Fix fragmentation
problems
Physical
memory are freed, but may not be contiguous
Solutions to the problems (except 4):
Add two registers to the CPU: base register and bound register
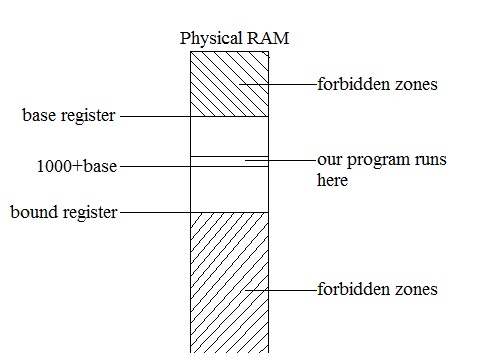
load (%ebx), %eax //%ebx = 1000
Base register is added to every address
Every process has it own base and bound registers, that are stored in its process table
Assumptions:
0) CPU support-CPU may not support these registers!
generalization: >1 pairs of base-bound registers
1) each process has its own region
2) regions do not overlap
3) sharing memory does not work (downside)
4) process size has to be known in advance. Growing is
expensive even though doable (downside)
5) base and
bound registers are privileged!
If not, a process can cheat by changing its base and bound registers. Then it can
access the forbidden zones or other process's data!
Process table is in the forbidden zones
Trackling flexibility problem:
Generalization: segments
physical address pa = base register[b] + O; //O for offset
+allows sharing between processes!
+hardware-supported subscript checking!
-limited number
of segments
one
segment each for read only data, program, stack and heap
-fragmentation

page = segment always 4KiB large
+no fragmentation
+no bound registers needed
-need 2020 registers!
solution: use RAM instead
page table is located in physical memory, unwritable to process
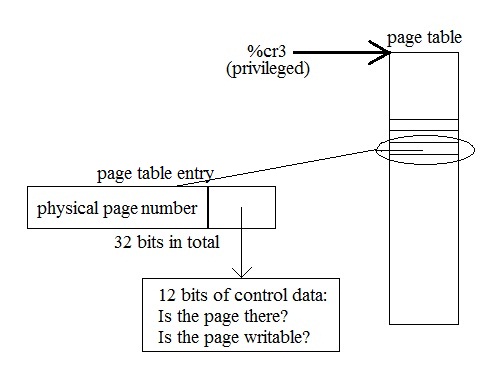
page faulting: occurs
when a process uses a virtual address that does not work
traps==>kernel stack gets pushed with process registers
kernel can: -abort process
-send signal to process
-find a free page, load from disk to RAM
-RTI (return interrupt)
Suppose we have a process that uses 2GiB VM
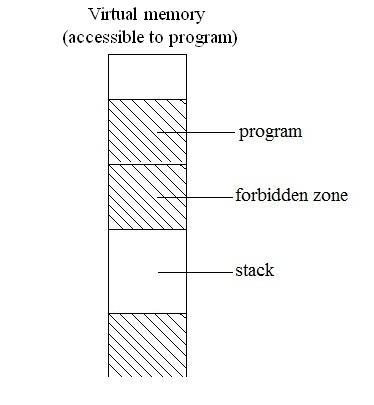
Assume: 32-bit page table entry
How much page table do we need?
2 MiB page table per process
Solution:

%cr3 [p1][p2][O]
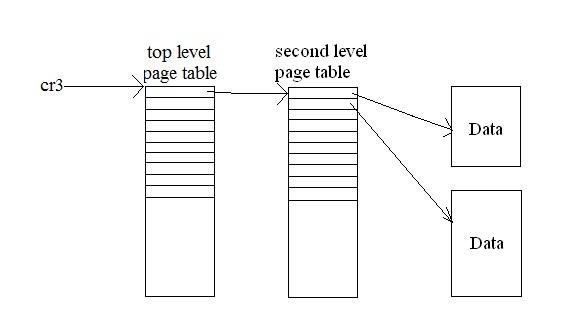
p1 is the displacement of cr3 along top level page
table
p2 is the displacement of
pointer along the second level page table
O is the offset along the data
now 4KiB page table
advantage to partially populated two-level page tables
Suppose va

C-code: map va to physical address offset
unsigned int v2p (unsigned int va){
unsigned int hi
= va >> (12 + 10);
unsigned int lo = (va >> 12) & ((1 << 10) - 1);
unsigned int o
= va & ((1 << 12) - 1);
pte* p = cr3[hi]; //p = page register
pte* q = (p & ~((1
<< 12) - 1))[lo];
return (q & ~((1 << 12) - 1)) + o;
}
Note: cr3 is a register that points to the physical address
One more problem: find a free page?
There is no such thing as "free" page as the system runs
Solution: replace "find a free page" to "find a victim page"
1) save the "victim's" data (if necessary) typically to
disk (swap space)
2) then the victim
page is FREE

Notes on swap space:
Swap space in Linux is used when RAM is full. If the system
needs more memory resources and the physical memory is full, inactive pages in memory
are moved to the swap space. While swap space can help machines with a small amount
of RAM, it should not be considered as a replacement for more RAM. Swap space is
located on hard drives, which have a slower access time than physical memory
Rule of thumb: swap space should be equal to twice physical
memory, or 32MiB, but no more than 2048MiB (or 2GiB)
(source: redhat documentation)
so RAM is a cache for swap space
How do you pick the victim?
FIFO: Whenever which page goes into the memory first, which
gets out first
use page reference
string
Suppose 3 physical pages (A-C), 5 virtual pages (0-4)
| Reference string | ||||||||||||
| 0 | 1 | 2 | 3 | 0 | 1 | 4 | 0 | 1 | 2 | 3 | 4 | |
| A | D0 | 0 | 0 | D3 | 3 | 3 | D4 | 4 | 4 | 4 | 4 | 4 |
| B | D1 | 1 | 1 | D0 | 0 | 0 | 0 | 0 | D2 | 2 | 2 | |
| C | D2 | 2 | 2 | D1 | 1 | 1 | 1 | 1 | D3 | 3 | ||
9 page faults
Suppose 4 physical pages (A-D), 5 virtual pages (0-4)
| 0 | 1 | 2 | 3 | 0 | 1 | 4 | 0 | 1 | 2 | 3 | 4 | |
| A | D0 | 0 | 0 | 0 | 0 | 0 | D4 | 4 | 4 | 4 | 3 | 3 |
| B | D1 | 1 | 1 | 1 | 1 | 1 | D0 | 0 | 0 | D0 | 4 | |
| C | D2 | 2 | 2 | 2 | 2 | 2 | D1 | 1 | 1 | D2 | ||
| D | D3 | 3 | 3 | 3 | 3 | 3 | D2 | 2 | 3 |
10 page faults!
Adding one extra physical page actually increases the number
of page faults = Belady's anomaly