CS 111Scribe Notes for Lecture 14 - 5.18.10by Ashley Jin, Joseph Tsai
Ext4: The Fourth Extended Filesystem for LinuxIn ordinary UNIX/BSD/ext1-3 and other traditional operating systems, you will allocate memory by allocating blocks one at a time or when a write() requests it. Ext4 breaks this tradition because allocating memory the previous way becomes a bottleneck. Instead, ext4 allocates memory by:
Atomic Actions: An Alternative ApproachLet users or other operations see inside the pending results of this action. Suppose we had a scenario where we had written data but not committed it yet and another user/action wants to read the data. With what we know so far, we would use locks but with this alternative, we tell the read to go ahead and read the data that isn't committed yet. However, if the writer aborts, the reader automatically aborts as well or compensates. These sequential aborts are called cascading aborts and can be followed by a compensating action which will attempt to repair after a cascaded abort. This increases performance by allowing reads on not yet committed data but increases complexity. Virtual MemoryThe original problem virtual memory tried to fix was the problem of not having enough RAM. For example, if you need 1GB but only have .5GB free, you could use virtual memory to use disk space instead of buying more RAM thereby saving money. Problem 1: If an application has random access to RAM and the ratio of virtual memory to physical memory is V/P, then probability of access requiring a disk read is 1 -P/V = (V-P)/V.
In general, a thrashing application, an application page faults frequently because it needs too much memory, is a dead application. Basically, if the probability of running into a disk access is high, then the application will be too SLOW! (If you only need a little more memory, then it will be slower but still ok. This is not a strong argument because for some applications this works nicely but for most practical application it doesn't.) Problem 2: If you have an unreliable program that crashes a lot but don't want the unreliable program to mess with the memory for other applications, what do you do? You could fire your programmers and hire better ones but more practically, you could use virtual memory to implement memory isolation and protection. Problem 3: You want to run several programs with specific memory storage addresses at the same time without having to rebuild them. Virtual memory allows you to have portability and flexibility by getting rid of the need to specify physical memory addresses. Problem 4: If you do not want memory fragmentation, you can use virtual memory because it can be implemented in a contiguous way. If we ignore problem 4 and focus on problems 2 and 3, we can achieve a simple solution. We will add two additional registers to the process table: the base register and the bounds register. The base register will point to the beginning of RAM that this process uses. The bounds register will point to the end of RAM that this process uses. Every time we ask to do a load, we will add the base register to every address so that it will point to the correct place in memory. However, if the process is trying to access a forbidden zone (a.k.a. outside of the base and bounds register), we will trap instead of accessing. Some characteristics of this solution are:
The problem with this simple solution is that flexibility is low. To increase flexibility, we can have more than one pair of base-bounds registers. Of course this increases fragmentation but we are not worrying about problem 4 right now. Registers are cheap but the more we have, the more expensive context switching will become because we will have more registers to save. We can also generalize into segments. Virtual addresses consist of 2 parts: high order bits that denote segment number and the rest becomes the offset of the segment. 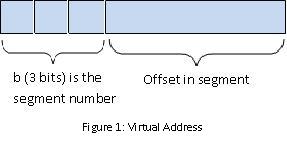 The physical address, pa, can be calculated by adding the offset to the base register (pa = base_register[b] + offset). By implementing segments, we can allow sharing between processes and have the additional benefit of hardware-supported subscript checking. However, we only have a limited number of segments (usually one for each read- only data, program, stack, and heap) and increased fragmentation with segments of all different sizes. We want to be able to solve the problems, keeping the benefits, without having fragmentation. By fixing the size of pages to a segment that is always 4KiB, we will no longer have fragmentation because the memory is now broken up into fixed size portions. 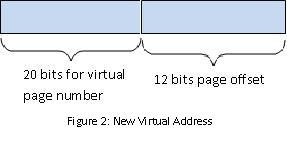 Now we no longer need the bounds register because all pages are the same size. If we know the base address, we know the bounds as well. But we would need 2^20 registers so use RAM instead. 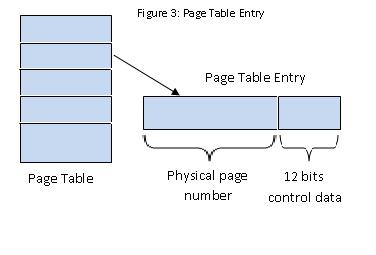 The control data can tell us if the page exists, if it's writable, and who owns the page. The root of the page is stored in cr3% which is a privileged register and the page table itself is stored in physical memory and is unwritable to the process. It is best not to have overlapping page table entries. Page FaultingPage faulting occurs when a process tries to access a virtual address that doesn't work. The hardware will trap and the kernel stack gets pushed with process' registers. In response, the kernel could:
Problem: Suppose you have a process with 2GiB of virtual memory where the program and stack take up little space. Assume 32-bit page table entries. How much space does the page table take up? Each process will have a 2MiB page table. This is because of and the problem with 1-level page tables. 2-level page tables 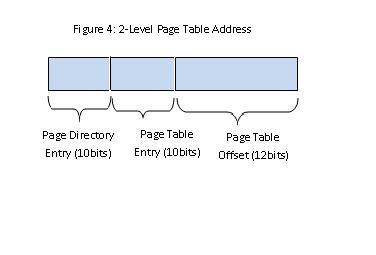 2-level page tables result in page tables of only 12KiB! 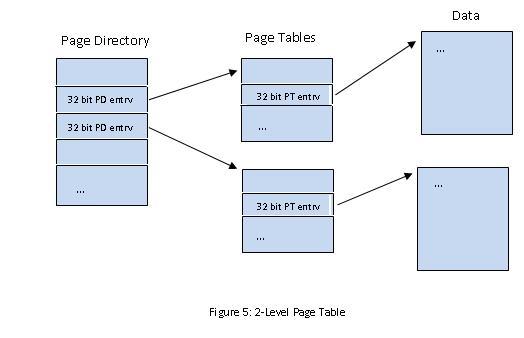 How can we get a physical address with a virtual address input? Problem: If a system runs long enough, there will be no "free" pages because all the pages will be holding useful data. Instead of finding and actual free page, we will find a victim page, save its data if necessary, and then it is "free". Typically, data is saved to the disk in the swap space. The swap space is divvied up by virtual page numbers and is generally twice the size of virtual memory. RAM is a cache for swap space. So how do we pick a victim page? We can use FIFO (First In, First Out) but how do can we tell how good a method is? Use page reference strings. FIFO Example: We have 3 physical pages: A, B, and C and 4 virtual pages. The processes are 0, 1, 2, 3, and 4 where 1, 2, 3, 4 are associated with virtual pages. ('*' denotes a page fault)  Interestingly, adding more physical memory to our system actually makes our system slower because it causes more page faults. This is known as Belady's anomaly. |