File System ImplementationCS111 scribe notes for lecture 12 (05/11/2009)by Nanxi Chen and Zhenkai Zhu |
||||||||||||||||
Dr. Eggert's Implementation |
||||||||||||||||
Simple File SyetemIn the summer of 1974, Dr. Eggert (an undergraduate at UCLA then) was hired by a professor to implement a file system. As all the computer scientists would do, he decided to implement it from scratch. Here is how he did it. The disk is treated as a big array. At the beginning of the disk is the Table of Content (TOC) field, followed by data field. Files are stored in data field contigously, but there can be unused space between files. In the TOC field, there are limited chunks of file discription entries, with each entry discribing the name, start location and size of a file as shown in the following figure. 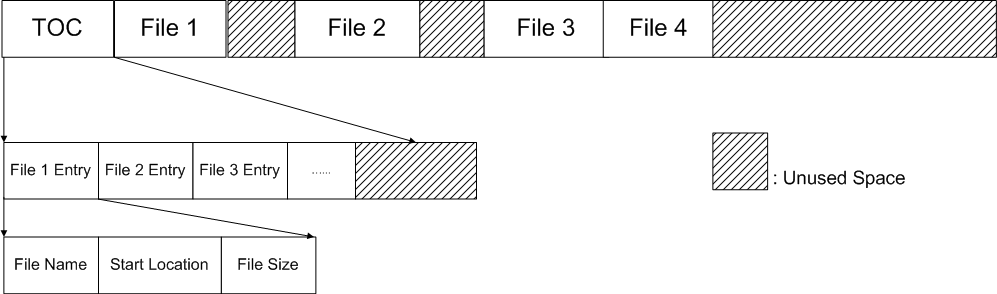
Figure 1. Dr. Eggert's File System |
||||||||||||||||
Pros and ConsThe main advantage of this implementation is simplicity. Whenever there is a new file created, a continuous disk space is allocated for that file, which makes I/O (read and write) operations much faster. However, it suffers from several aspects. First of all, it has external fragmentation problem. Because only continuous space can be utilized, it may come to the situation that there is enough free space in sum, but none of the continuous space is large enough to hold the whole file. Second, once a file is created, it cannot be easily extended because the space after this file may already be occupied by another file. Third, there is no hierarchy of directories and no notion of file type. External and Internal FragmentationExternal fragmentation is the phenomenon in which free storage becomes divided into many small pieces over time. It occurs when an application allocates and deallocates regions of storage of varying sizes, and the allocation algorithm responds by leaving the allocated and deallocated regions interspersed. The result is that although free storage is available, it is effectively unusable because it is divided into pieces that are too small to satisfy the demands of the application. Internal fragmentation is the space wasted inside of allocated memory blocks because of restriction on the allowed sizes of allocated blocks. 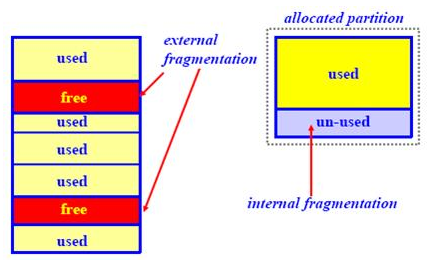
Figure 2. External and Internal Fragmentation |
||||||||||||||||
|
||||||||||||||||
|
|
||||||||||||||||
File Allocation Table System |
||||||||||||||||
OS/360The major problems with the above simple version of file system are "external fragmentation" and "inability to grow file". There is a way to partially address these problems, as IBM OS/360 did. When you create a file, you manually specify the space to allocate. You can grow the file by incremental space allocation. However, the number of increments is limited. FATA better way to solve these problems is FAT, which stands for File Allocation Table. In FAT, the disk space is still viewed as an array (which steals Dr. Eggert's idea). The very first field of the disk is the boot sector, which contains essential information to boot the computer. A super block, which is fixed sized and contains the metadata of the file system, sits just after the boot sector. It is immediatedly followed by a file allocation table. The last section of the disk space is the data section, consisting of small blocks with size of 4 KiB. 
Figure 3. FAT File System In FAT, a file is viewed as a linked list of data blocks. Usually, one would expect that there should be a small field called "next block pointer" in each data block to make up a linked list. However, this is considered a hassle and is eliminated by introducing the FAT field. FAT field stores data block index, with each entry having a number N.
Thus, a file can be stored in a non-continuous pattern in FAT. The maximum internal fragmentation equals to 4095 bytes (4k bytes - 1 byte). Directory in the FAT is a file that contains directory entries. The format of directory entries look as follows:
Sample of Directory
Pros and ConsNow we have a review of the pros and cons about FAT. Readers will find most of the following features have been already talked about above. So we only give a very simple list of these features.
|
||||||||||||||||
|
||||||||||||||||
|
||||||||||||||||
|
||||||||||||||||
|
|
||||||||||||||||
Unix-like File System |
||||||||||||||||
Overview of Unix-like File SystemUnix-like File System is a file system used by many Unix and Unix-like operating systems, although there may be some minor changes over different operating systems. The one we will talk about is from BSD variant, developed at 1980. 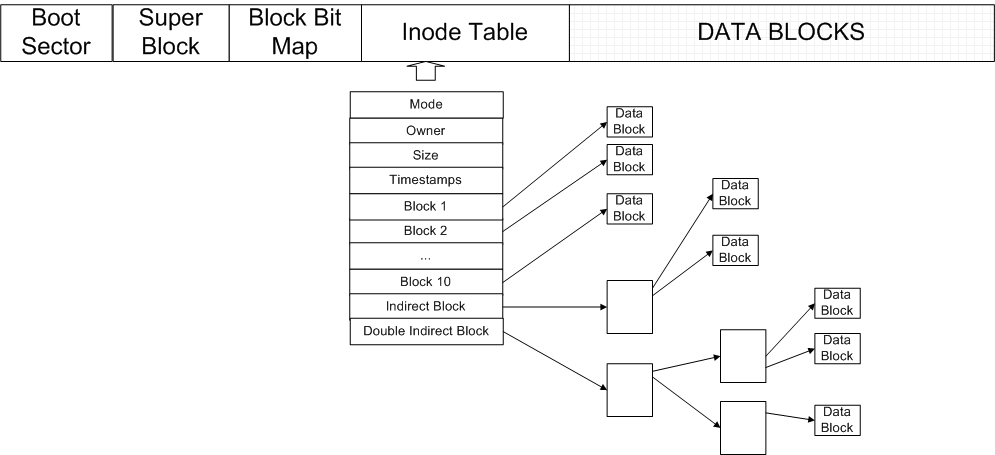
Figure 4. FAT file system Basically, disk space is divided into five parts as shown in Figure 4:
|
||||||||||||||||
InodeInode is the data structure that describes the meta data of files (regular files and directories). One inode represents one file or one directory. A typical structure of an inode can be seen in Figure 4. Inode is composed of several fields such as Ownership, Size, Last Modify Time, Mode, Link Count and Data Block pointers (which point to the data blocks that store the content of the file). Note that inode does not include file/directory's name. We will talk about nameless in detail later. In shell, a file's inode number can be found using the Each inode has 10 direct block pointers (different file system may have different number of direct block pointers). Every direct block pointer directly points to a data block. The maximun size of a file using only direct block pointerscan be as big as 80 KiB. To extend file size, inode introduces the concept of indirect block pointer. Indirect block pointer does not point to file content; instead, it points to the data blocks which store direct block pointers. In other word, to access file content through indirect block pointer, one has to do at least 3 I/O operations. Assume each block pointer costs 4 bytes, a data block can store 2048 block pointers. So the file size can be up to (10 + 8192/4) x 8192 = 16 MiB. To accomodate even larger file, we need double indirect block pointer, which adds another level of indirection. As shown in Figure 4, there are 4 I/O operations to access file content stored with double indirect block pointer. Now file size can be as big as (10 + 8192/4 + (8192/4)^2) x 8192 = 32 GiB, which is big enough for most of files used nowadays. Remember, this filesystem is designed in 1980s; most files at that time wouldn't reach that size. Some inode has triple indirect block pointer field, and certainly is able to handle even larger files. |
||||||||||||||||
|
||||||||||||||||
Holes in the FileThe file in the unix-like file system can have holes inside. A hole does not actually occupy the disk space; instead, the file system just remembers the location and size of the hole. When you read from these holes, you get zeros; when you write into the holes, the file system allocates new data blocks. Therefore, even a file which has holes inside seems to be very large (e.g. 100 GiB), it may only take very little disk space indeed (e.g. 1 MB). Now let's try an interesting test. You can easily create holes with following shell command: $dd if=/etc/passwd of=file seek=BIG NUMBER
To have a look at the size of the file, type $ls -l file
File size may be as big as 1239852395812489000000000000 bytes. Then you type $ls -ls file
You may find actually a small number of blocks is used. But if you use copy command, things may become totally different $cp file file1
file1 actually uses BIG NUMBER data blocks. In other word, all the zeros in the holes are copied. Don't do this in SEASnet! Who would create a file that has holes (other than for fun)? Here are two examples in real world: Berkeley DB uses hashing and creates a lot of holes in the file. Another popular application, Bittorrent, also creates holes. Inode is namelessInodes don't know the file name, and they don't know the containing directory either. Directory stores the file names. Each directory entry is consisted of a pair of file name and inode number. It's ok to have two or more names for the same file. E.g.
Hard Link
The above phenomenon is so called hard link. The system keeps a file as long as a) at least 1 hard link on that file, or b) at least 1 process has it opened. Hard link is a controversial feature of Unix-like file system. It was initially designed to support rename operation "robustly". To rename a file, you first a) create a new directory entry for the file; then b) remove the old directory entry. If both creating and removing are atomic operations, the renaming operation is considered robust. It is also cheap to clone read only directory structures. To realize this, we only need to perform the step a) without step b). If you are interested, check git-clone out. |
||||||||||||||||
|
||||||||||||||||
|
|
||||||||||||||||
System Call |
||||||||||||||||
Unlinkunlink("f")
This system call decrements the link count in the inode by 1. File is removed when link count equals to 0. Openopen("a/b/c", ...)
System starts to resolute the path "a/b/c" from current working directory. The resolution procedure is shown in Figure 5 (to be simple, we allow inode to contain the directory entry). 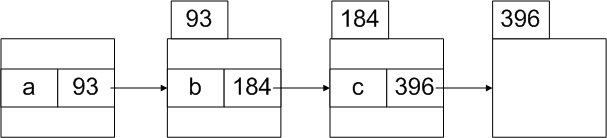
Figure 5. Path Resolution Procedure We can obtain working directory from process descriptor. Actually, root directory is also stored in the process descriptor. Command "chroot" can be used to change root directory. However, executing |