CS111: Lecture 7 - Scheduling Algorithms
Scribe Notes for October 14, 2010
By Masaki MoritaniScheduling
The OS must manage resources while it is running. For this purpose, the scheduler is a part of OS that manages time and its relation to other resources. In designing schedulers, there are two main issues:
- Resources can't be accumulated/saved/cached.
- There is a tradeoff between high quality scheduling and fast scheduling.
There are many resources that need scheduling, but for now, let's look at the CPU (as a unit). Also assume that there is only 1 CPU on our machine (though CPU resource scheduling problem occurs regardless of the number of CPUs), and that the machine uses Unix processes. The scheduler would decide which process runs when.
Threads
Threads ("lightweight processes") are like the stripped-down version of processes; they have a virtual CPU, but they don't have file descriptors, signal handling, parent processes, etc... Also, threads share memory, so they are not very isolated. This leads to abundant opportunities for race conditions, but threads perform better due to its lightness (if done right). In designing threads, one can either make them unsafer and faster, or safer and slower.
Cooperative Threading
Cooperative threading is an unsafer but faster approach to implementing threads. In it, we trust each thread to help out the scheduler by, for example, issuing system calls or calling yield() now and then. This style of coding is often natural; programs like cat and emacs work by doing system calls. Uncooperative operations include bugs and loops.
Some advantages and disadvantages:
- There can be uncooperative processes that chew up resources and don't give up control.
- Race condition bugs are less likely.
- You automatically get locking for free (you just need to avoid executing a system call in the middle of a critical section).
Preemptive Threading
Preemptive threading comes in between the two extremes of the tradeoff. In preemptive threading, the OS arranges for a timer interrupt and acts like an INT instruction every 10 ms or so. The kernel thus saves and restores contexts, and these contexts can be different threads. This approach saves the OS from uncooperative processes not willing to yield, but it doesn't solve the infinite loop problem; preemptive threading just puts them off, so these uncooperative processes still consume resources (a manual "kill" is still needed). To kill these automatically, there is a time limit approach, but it often does not work as expected because the time limit counted by the system is often not what we design it to be.
Event-Driven Programming
An outlier approach is event-driven programming. This divides your programs into small chunks of cde called "callbacks," which are triggered by events. Callbacks never block; they run and exit (there are no waits in event-driven programming). Instead, callbacks schedule requests and terminate.
Some advantages and disadvantages:
- It is much simpler than cooperative threading; locking is not needed either.
- It puts a constraint on your program.
- It assumes that the computer that it runs on is single-core.
Event-driven programming can be seen more often in simpler, smaller OSs. Twisted (a networking engine for Python) is a recent example of event-driven programming.
Notice that event-driven programming and cooperative threading (the simpler, faster approaches) are more suited for single-core computers. On the other hand, preemptive threading and safer/slower approaches are suited for multicore due to their parallelism and their need to lock.
Scheduling Issues
If a machine has n CPUs, then there are less than n runnable threads at one time. (Threads can have other states: zombie, blocked, timer wait, and waiting.) To keep track of these threads, we need policies and mechanisms. Scheduler policies choose which threads to run; scheduler mechanisms are low level implementations to make the scheduler actually work.
Scheduling Policies
There are several scales of scheduling to be done:
- Long term (hours/days): e.g. admission to a system
- Medium term (seconds): e.g. which process resides in RAM?
- Short term (ms): e.g. which threads have the CPU?
Schedulers must maintain a variety of resources, and these different types of resource require different scales of scheduling. Suppose an OS is running on a single-core CPU. The scheduler for the CPU must decide which thread should be running on the CPU. At the same time, the scheduler should switch among parallelly running threads; these switches must be done very frequently and very fast. Memory, on the other hand, has space for multiple processes. This is why the scheduling for which process resides in RAM is in medium scheduling scale; the scheduler switches in and out process in RAM less frequently. The example for long term scheduling scale refers to real life problems when users request admission to a system. A system may take hours or days until it grants user admission (or, the system never does).
Scheduling Metrics
Schedulers are heuristic, and if they have problems, they're hard to fix. This is why creating "good" schedulers is very difficult. To measure how bad a scheduler is, one needs metrics to measure it.
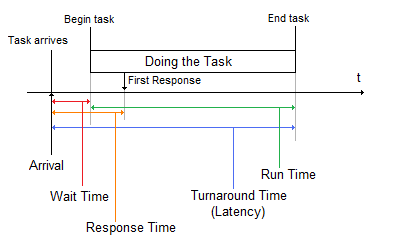
Take note that scheduling metrics exist before computing; for example, a car manufacturer may have measured its scheduling of building cars.
- Arrival time is when a task arrives into the system. In car manufacturing, perhaps an order is made to manufacture 50 cars. In Linux, this may refer to when a user types a command, say for example, "echo foo bar baz".
- Wait time is the time it takes from arrival time to when the system actually starts working on the task. In car manufacturing, it is the time between when an order is places and when car-building begins. In the Linux example, it is the time it takes between the user command and when execvp is called by the shell.
- During the task, system often gives a response of some type to indicate that the system is working on the task. In the Linux example, the user may witness "foo" on the output screen. The time it takes from arrival time to this first response is called response time.
- Finally, the task is done. In the Linux example, an exit function is called by the "echo" program. The total time the system used working on the task is called run time. The time between the initial arrival and the end of task is called turnaround time or latency.
Systems must do numerous tasks; right after a task is completed, another task arrives. In between those tasks, there is a small context-switching time. In computing, this may refer to the time it takes for a system to switch its context from thread 1 to thread 2.
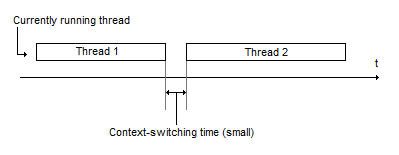
When a system goes through multiple tasks, you can calculate the average and variance of the measurements (e.g. average wait time, average run time, variance in wait time, variance in run time..). In particular, average wait time is a good measurement of throughput or utilization, which refers to keeping the CPU busy. Variance in wait time, on the other hand, is a good metric of fairness. Good schedulers are fair; this means that every thread that wants to run should eventually get a chance to run.
Some Simple Scheduling Algorithms
First-Come-First-Served (FCFS) Scheduler
In this simple scheduler, the tasks are executed in queue; tasks will be done in order of arrival time.
Below is an example that illustrates performance of a FCFS scheduler.
| Job | Arrival time | Run time | Wait time |
| A | 0 | 3 | 0 |
| B | 1 | 1 | 2+k |
| C | 2 | 7 | 2+2k |
| D | 3 | 4 | 8+3k |
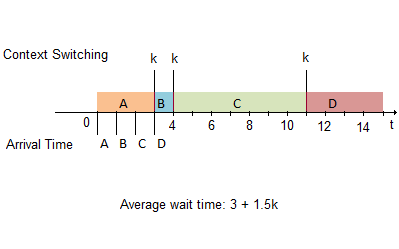
The FCFS scheduler usually has a long average wait time.
Shortest-Job-First (SJF) Scheduler
In a SJF scheduler, whenever the scheduler stops to switch context, it switches to the shortest job available. Jobs that take longer time will be postponed.
Below is an example that illustrates performance of a SJF scheduler.
| Job | Arrival time | Run time | Wait time |
| A | 0 | 3 | 0 |
| B | 1 | 1 | 2+k |
| C | 2 | 7 | 6+3k |
| D | 3 | 4 | 1+2k |
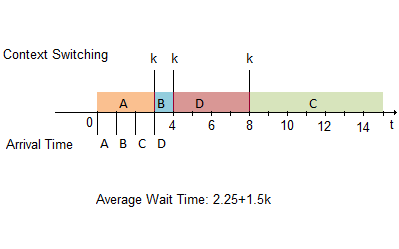
The SJF scheduler always has an advantage over FCFS in average wait time, since only a few long jobs will have long wait time. However, at the same time, the SJF scheduler is very unfair; long jobs may have an infinitely long wait time, when shorter jobs keep entering the queue. Since fairness is important to schedulers, this algorithm is seldom implemented for scheduling.