Scribe Notes
CS111: Fall 2010 - Week 2, Lecture 4
Alfonso Roman
Wei Liao
Modularity
How to get hard modularity - modules protected against each other - bugs, mistakes, each other - makes system unreliable
n = fact(5);
Client module:
send(fact,{"!",5});
receive (fact,response);
if(response.opcode == "ac")
print(response.val);
else
print("error");
Server:
while(1) {
receive(fact,request);
if(request.opcode == "!"){
n = request.val;
int p =1;
for(int i =1; i<=n; i++)
p*=i;
response={"ok",p}
} else {
response = {"ng"}
}
send(fact,response);
}
- slower in terms of latency between modules
- authentication issues on a network (i.e. the internet)
- need more machines
- transmission errors
factl, %eax, %ebx #giving more power to the hardware
Virtualization - we need to build a virtual machine (built on
top of another machine). We write an x86 emulator (in C, say), add to this emulator a factl instruction -- run designated program in emulator.
→ client is in emulated program (client is never in control)
→ server is in emulator
- slow (pay performance penalty) by factor of 10
Virtualizable hardware - This lets us emulate machine X on X (if X is virtualizable). The hardware has built in controls to make it easier to emulate itself. How would this work? What are some downsides to this approach?
→ This approach would let emulated programs run at full speed - so long as they're doing "normal" things that won't screw up the emulator.
→ Hardware passes control to emulator if the emulated program does anything privileged
› unprivileged - nice, i.e. mult, add, div
› for this we have to assume that the vast majority of instructions are unprivileged
→ A possible problem is a denial of service attack
while(1) halt();› we can have emulator check the number of instructions and boot out program if it detects this behavior
› assume processor has a timeout - once every 10 ms it lets emulator get control - no matter what emulated program is doing.
→ We're also going to need to partition memory (or we can have a violation with store command)

› while we can avoid this by making store a privileged instruction, we violate one of rules -- that majority of instructions are unprivileged!
→ Interrupts give control to emulator (assumption is that you don't spend much time here)
→ We don't want emulated program to talk to devices - these will become privileged instructions (assumption is that most programs don't need to talk to devices)
Using a virtualizable processor to extend our instruction set
addl ...
mull ...
halt ...
5 # we will make the assumption that when we see halt
# followed by a 5, our emulator will calculate 5!
leal 1(%eax), %ebx
The above code gives us a way to calculate factorial by following a set pattern that our emulator will recognize. When it reaches a halt instruction, it will calculate factorial of number immediately following in the code. This approach is limited in that it only let's us compute constant hard coded values. Let's change that assumption and make our program more dynamic:
movl $5, %eax halt # now we assume that 5! is passed in %eax leal 1(%eax), %ebx
Now we have a better way to get our factorial parameter. The important thing to note here is that we have a privileged instruction in order for the emulator to take control and compute factorial.
This is not the only way we can make this happen. Consider:
jmp * # this instruction keeps jumping to itself.
# after some timer, we check the instruction, and if our emulator
# detects a jmp *, we compute factorial
In the above example we set another pattern that the emulator will recognize in order to compute factorial. These approaches make it very important for our x86 emulator to be extremely reliable.
In Linux the convention is to use the int (interrupt) instruction
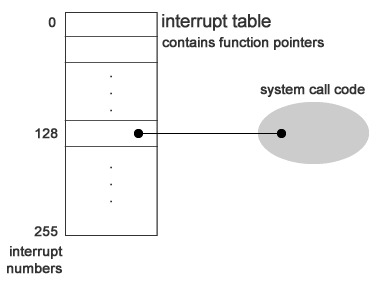
when a program wants to execute privileged instructionsint [byte] # byte = interrupt number # this is a privileged instruction!This calls a functions pointed to by interrupt address table. This table is in protected memory, so it can't be accessed by our emulated program. Here is how it works:
int 0x80 # 0x80 = 128 is the system call number in the interrupt table # this gives the emulator control and allows # it to execute privileged instructionsWe enter the interrupt table, which contains function pointers that will handle our system calls.
When this happens, the kernel pushes information into the kernel stack
ss # stack segment esp # stack pointer eflags es # code segment eip # instruction pointer error code # if a problem occursKernel/Emulator can do what it likes -- this includes executing privileged instructions.
reti # return from interrupt instruction
# this pops all the information from the kernel stack and restores
# the instruction pointer, then returns control to emulated program
What happens if the kernel want to execute privileged instructions? We obviously can't perform the above actions. Instead, we rely on a special register which holds a flag
› this is set to 1 at startup, but who sets this bit afterward? Do we need a privileged instruction to set the privileged bit?
› this bit is set when we call the interrupt instruction
› this gives us protected transfer of control, but we loose some speed
We need to set some conventions
p = open("xyz", ordwr, 0666); // This is nicely packaged in the C library so
// that we don't have to write any assembly code.
Syscall number is stored in the %eax register. Results are stored in the %eax register.
arg 1 : %ebx arg 2 : %ecx arg 3 : %edx arg 4 : %esi arg 5 : %edi arg 6 : %ebp
Can this nest? On x86, yes - up to 4 levels. %cpl tells you what level you are in.
How can we use this to build a system?
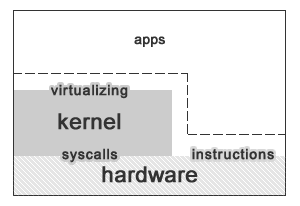
We want to be able to access instructions
› unprivileged - only unprivileged instructions
Access to registers
› we need to have privileged registers
—› these are rarely used
—› and usually needed to control access to system. i.e. %cpl - current process level
› we need to have access to normal registers
—› these need to accessible at full speed
› we also need to virtualize registers so that each program thinks it has its own set.
$ cat | dog
How does each process know which registers it owns? We introduce the concept of process descriptors. These structures describes
each process.

The idea here is that each process saves a copy of its registers in this structure. So in this example, cat and dog don't know (or care about) what registers the other was using.
Will this be a big performance hit? While it's true that the more registers you have to load/save will make it slower (think the x86-64 instruction set), the kernel has tricks up its sleeve to handle this. For example, it will only save/restore the registers it needs to use. It also doesn't need to save any of the floating point registers.
We now have a way to manage the registers, but how do we control access to primary memory?
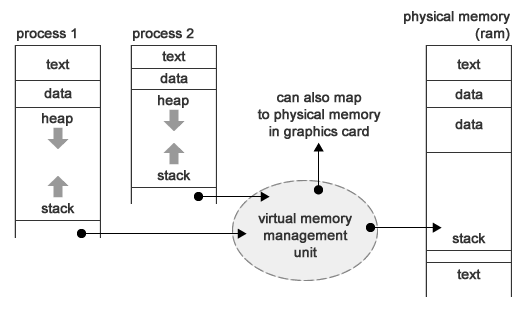
Access to Devices (we want a single way to abstract access to all devices)
→ No hardware support needed because it's rare
→ We typically use only syscalls
→ Common exception: graphics devices
→ Different kinds of devices:
› disk drive
› graphics output
› spontaneous data generation (keyboard or network card)
UNIX's big idea: single abstraction for all devices. (devices are modeled as files)
—› open
—› read
—› write
—› close
—› seek
› ioctl (leftover junk)
To see an example of just how this abstraction is used, consider this Linux command:
$ cat /proc/cpuinfo processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 23 model name : Intel(R) Core(TM)2 Duo CPU P8700 @ 2.53GHz stepping : 10 cpu MHz : 800.000 cache size : 3072 KB physical id : 0 siblings : 2 . . . bogomips : 5054.07 clflush size : 64 cache_alignment : 64 address sizes : 36 bits physical, 48 bits virtual power management: $Using the file abstraction we can treat devices like the CPU as files with useful information. In general, you will see that /proc contains all sorts of useful files that will give you information about processes.
QNX Aside
QNX is an operating system that is based on the idea of client-server message passing we discussed in part 1. QNX uses virtualizable processors to implement message passing whereas Linux uses virtualizable processes to implement extended instruction sets. To learn more about QNX visit this wiki page.