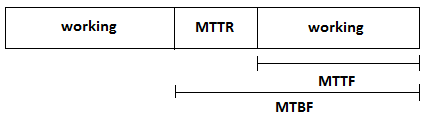
CS 111: Lecture 16Scribe Notes for 11/23/2010by Sun Moo Lee, Terry Huang, Ming-Chun HuangContents 1. Robustness 1.1 Media Faults 1.2 Failure Rate Terminology 2. RAID 2.1 RAID 0 2.2 RAID 1 2.3 RAID 10 2.4 RAID 4 2.5 RAID 5 3. Distributed System 3.1 Remote Procedure Calls 3.2 Problems with RPC 3.3 Marshalling 1. Robustness 1.1 Media FaultsSometimes our disk drives can still fail even though we have power. We are also assuming that the failures are detectable (typically on read, but sometimes on write too). One approach to deal with this is to: read, check for errors, then write. But this is terrible for performance! This is because of rotational latency. But before we talk about a solution, let's discuss some terminology... MTTF = mean time to failure
availability = MTTF / MTBF MTTF of some disk = 300,000 hours = 34 years. But this measure is misleading because it's an estimate... annualized failure rate (AFR) = if you run the disk for a year, what is the probability that it will fail To deal with this failures and ensure robustness...we introduce RAIDs. Back to Top Used to stand for: (Redundant Arrays of Inexpensive Disks)Now stands for: (Redundant Arrays of Independent Disks) RAID 0 is basically a bunch of big disk drives added together...
So the failure rate = failure rate(disks0) x failure rate(disk1) x .... But when there is an error in one of the disks, your just plain out of luck!
RAID 1 introduces mirroring. What it means is that there are two disks, but they both write the same information. Because they have the same content, we gain reliability, and a 2x performance increase for reading. Writing performance, however, hurts because we now have to write twice for one write(). This is a combiniation of RAID 1 and RAID 0, meaning we concatenate mirrored disks.
(disk0 mirrors disk1) concat with (disk2 mirrors disk3), (disk4 mirrors disk5) and (disk6 mirrors disk7)
You can also mirror concatenated disks
(disk0 concat with disk1, disk2, disk3 and disk4) mirrors (disk5 concat with disk6, disk7, disk8 and disk9) There is an assumption that the failures are independent, which is not hold if power supply is spiked. You can also plug in a "hot spare" -- a spare hard disk that kicks in should one of the disks fail.
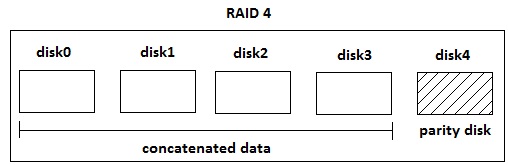
In RAID 4, we will have one of the disks that keeps track of the XOR of the other disks (this disk is called the parity disk). The reason for XOR is because we can use the info on the parity disk to recover contents of the other disks, should someone go down. In this situation we need at least two disks to go down at the same time, otherwise we can use the other disks to recalculate/restore. Sounds good, but there's always a catch: 1. There is CPU overhead in calculating the XOR everytime you write.
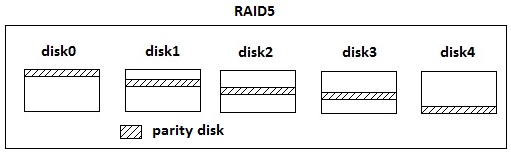
Similar to the concept of RAID 4, except now instead of having a parity disk, the original contents of the parity disk is seperated out into all 5 disks. This is good because we avoid that hotspot, but bad because things are more complicated and it is more inflexible to add another disk (RAID 4 isn't great in the latter, but certainly better than RAID 5). Back to Top
The idea here is to have the caller and callee be on different systems and be able to communicate by passing messages to each other. There are several good reasons for this, such as enforcing hard modularity and security (well...depending on how you do it). 3.1 Remote Procedure Calls (RPC) Like syscalls, but this is used to communicate between machines. Let's look at the advantages (+) and disadvantages (-) + hard modularity for free because caller + callee are on different machines
For the last problem, there are several solutions. One way is to standardize the exchange format (e.g. XML), but this is unnecessary bandwidth and CPU overhead. A better alternative is to just standardize on big endian (this is the current solution). Big endian because IBM was big back in the days, so it was standardized. For Intel architectures theres actually a machine instruction to swap little endian to big endian (byteswap). There may be issues with RPC, for example, the packets could get lost, duplicated or become corrupted. In these circumstances it is best to report an error to the user, better to let the user deal with it than do something to mess things up, or just resend the request.
3.3 Marshaling(Serialization or Pickling) Marshaling is the process of converting data to standard network order (or in other words, something that lets us send over the network). The way it works is that every time you want to do a function call (e.g. read/write), stubs are automatically generated (from a protocol description) and sent/recieved over the network. Back to Top
|