CS 111: Lecture 16 - RAID and Distributed Systems
Scribe Notes for Tuesday, November 23, 2010
By Andrew ReyesSome images used are from the RAID Wikipedia article
and the Failure Trends in a Large Disk Drive Population article by Google
On Failures
So far we have only covered the types of failures where our machine loses power. So now, we will assume that the disk drives go bad, but we still have power. This is called a Media Failure.
Recall the Lambston-Sturgis Assumptions:
- When a disk drive fails, it fails because we are reading to it, or writing from it.
- But either way, we assume the failures are detectable.
The idea is that will either detect the failure when we write, or when we read and see that the value is wrong. Media faults typically are found on reads, but sometimes on write.
Some people are paranoid about this. So what do they do?
Read-After-Write: They want to detect these failures as soon as possible, so they read after every write.
- + Improves checking
- - Really, really slow! Rotational latency: You have to wait for the disk sector to come all the way around again.
- Hardware trick to get around rotational latency: Have a read head and a write head and position them correctly one before the other.
But all of the techniques we've talked aobut so far are helpless in the presense of media faults! Media faults cannot be solved by logging, because the log goes bad. "You’re still hosed." You might have duplicate copies, but in general, you have data on the disk once and then you lose it.
RAID To The Rescue
Redundant Arrays of Inexpensive Disks
The original motivation was that this solution was inexpensive. Of course, if you wanted to make a lot of money selling RAID solutions, you'd want to charge more for them.
Now RAID stands for Redundant Arrays of Independent Disks
History of RAID
- David Patterson, a UCLA Graduate student who didn't like spending money
- He was a cheapskate (so RAID, of course, was an inevitability)
- When he moved to Berkeley, he and his group characterized the different ways of bolting different disks together into arrays
- Responsible for "Classification of Redundant Disk Strategies"
- Came up with 6 different ways to do RAID: RAID 0 through RAID 5
- Since then, people have been coming up with more RAID combinations
RAID 0: Striping Without Parity Or Mirroring
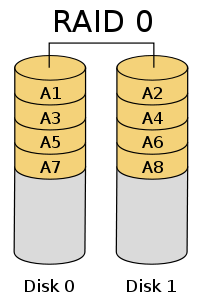
- Reliability is dependent on your weakest drive
- Must multiply failure rates
RAID 1: Mirroring Without Parity Or Striping
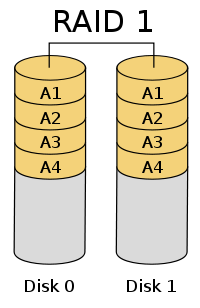
- Disk 0 and Disk 1 are mirrors of each other
- When writing, write to both
- When reading, read from just one
- When a read failure occurs, just read from the other disk
- Remember, our assumption says that we will catch read failures (using checksums, etc.)
- Win on performance for reads because you can read from two different disks at once. (Up to 2x!)
- Write performance is not so good; you must position both heads to the same spot.
Can We Combine Concatenation and Mirroring?
Yes, we can concatenate mirrored disks!
We can also mirror concatenated disks.
Which is better? This is apparently a controversy, but in a high-level analysis, they are the same.
RAID 4: Striping with Dedicated Parity
Mirroring is great because it gives you redundancy, but it comes at a cost.
If you want 1TB of space, you have to buy 2TB worth of drives.
The idea of RAID 4 is to bring down redundancy overhead from 100% (RAID 1) to (say) 25%.
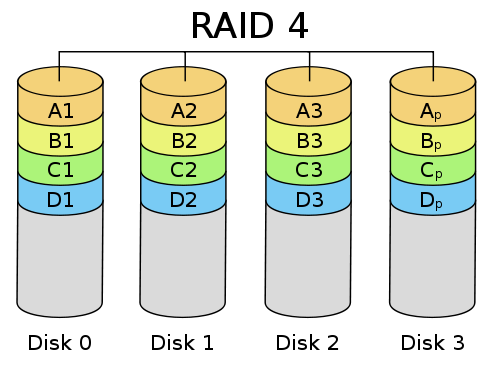
- Parity Disk: If a block goes bad in Disk 0, we can reconstruct it from the Parity Disk (Disk 3).
- Parity disk is the XOR of Disks 0 through 2.
- If a block in Disk 0 goes bad, XOR blocks in Disks 1, 2, and 3 to reconstruct the block in Disk 0.
- What's the catch?
- More CPU overhead, but CPUs are essentially free
- If I want to write to some block on disk 0, I have to write into two areas, so the XOR parity remains consistent.
- Parity disk becomes a hot spot. Parity disk's disk arm becomes the bottleneck.
RAID 5: Striping with Distributed Parity
How can we fix the hot spot/bottleneck problem of RAID 4?
Let's make every disk a parity disk! Parity is split between all disks.
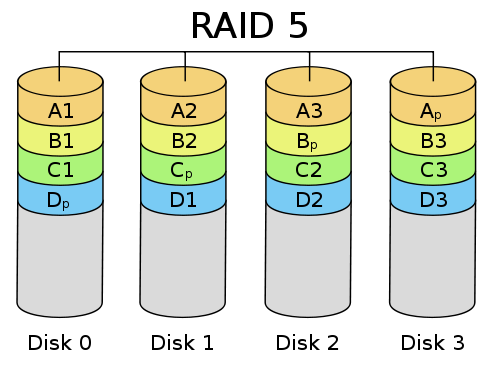
- Advantages over RAID 4:
- Hot spot is spread out for parity checking
- Disadvantages over RAID 4:
- More difficult to expand space once filled up
- More complicated to implement
- Similarities to RAID 4:
- Replacing a disk is equally bad as RAID 4
- If two disks go down, you're hosed!
Failure Terminology and Analysis
MTTF: Mean Time To Failure (How often does it break?)
MTBF: Mean Time Between Failure (How far apart from first fail to second fail?)
MTTR: Mean Time To Repair (How long does it take to fix it?)
Availability: MTTF/MTBF
Downtime: 1 - Availability
MTTF is a very misleading measure. Western Digital claims its disks' MTTF = 300,000 hours, which is about 34 years. Obviously, they didn't test a hard drive for 34 years. Instead, they ran a whole bunch of disks in parallel and calculate from there, most likely with the equation: MTTF = ([a short time period] * [number of items tested]) / [number of items tested which failed within time period]
Annualized Failure Rate (AFR) is a much better measure!
AFR = If you run a disk for a year what is the probability it will make it?
AFR is difficult for disk drive manufacurers to calculate.
It's much easier to calculate if you actually use your disks 24/7.
Google published a paper that calculated the AFR for real disks, published in 2007.
Below is the actual graph published by Google, with Eggert's expected curve added by me.
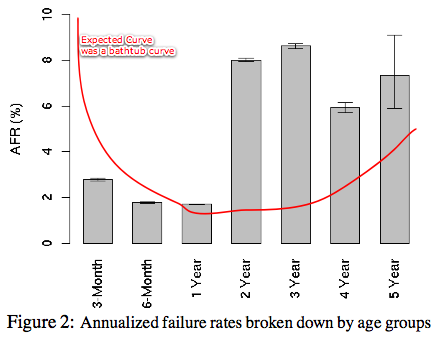
Eggert's expected curve suggests many drives should fail within the first year, but Google's data shows otherwise.
Eggert suspects that disk manufacturers catch many of the flakey hard drives and repair them or throw them away before they reach consumers, thus starting everyone off near the bottom of the bathtub curve.
What is the failure rate of a RAID 5 box?
Annual Failure Rate of a RAID 5 Box
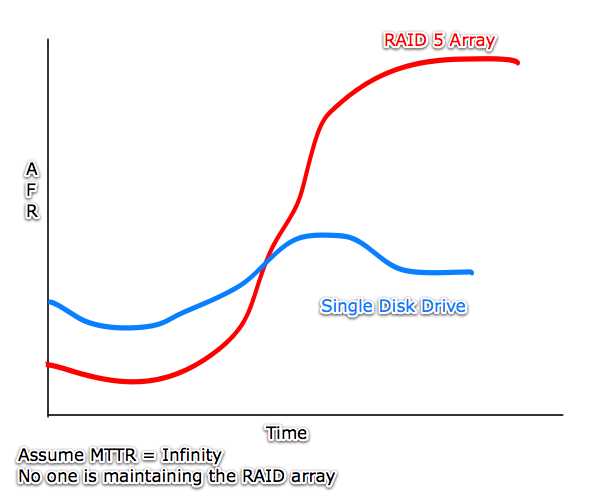
Initially, if one disk fails, we're still OK. If two drives fail, then we're hosed!
RAID 5 must have two near-simultaneous failures to fail.
The reliability of a RAID box is heavily dependent on the operator. In practice, the operator is unreliable.
A way to increase reliabilty is to have hot spares, a spare disk that is connected but not used until another disk fails.
The big assumption we make is that failures are independent. This is one of the motivations for Redundant Array of Independent Disks. If failures weren't independent, all of RAID would be pointless. RAID will not work that well during a power spike and all drives fail at once. People will distribute each drive geographically to avoid this problem. Banks do that. UCLA does that.
Distributed Systems
Distributed systems use message passing as means of communications. In order for Computer A to get work done, Computer A sends a request to Computer B. This is a request-response pair. This is all in contrast to function calls or system calls.
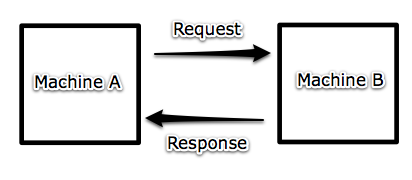
One of the most common ways of abstracting request/response is by using Remote Procedure Calls, or RPC. A message could look like: close(19), which looks like a function call, but underneath it's different:
Differences between RPC and traditional system/function calls:
- The caller and callee are in different machines.
- System calls give you hard modularity for free, function calls don’t. Computers don't share address space.
Disadvantages of RPC:
- Cannot do call by reference; caller does not have access to the callees memory, address space isn’t shared.
- Suppose we want to send a large buffer that we want to write out, then this whole buffer must be shipped from one machine to another.
- Limited by network bandwidth
- Security is a major issue (Will talk more about this next week)
- Messages can get lost, or duplicated
- Server can become a bottleneck; but this is true for RPC as much as anything else
- Caller might be x86 and callee might be x86-64, or even SPARC
- You might have disagreements on how data is represented.
- x86-64 is little endian. 0123 = big endian, 3210 = little endian
Ways to deal with architectural differences:
Most people choose option three from below.
- Standard interchange format: Use XML text
- Has consideable network and CPU overhead
- Have everybody know everybody else's architecture
- This is an N-squared problem, doesn't scale very well. N different kinds of machines with N^2 possible combinations.
- For every architectural difference, standardize on one and require everyone else to convert
- Example: Over the net, we standardize on big endian, but everyone else must convert
- This is why Intel (little endian) machines have a single byteswap instruction that converts from big to little endian.
- History Lesson: We standardize on big endian becuase when the Internet standards were first being written, IBM mainframes were big endian and people wanted their machines to run well on IBM mainframes.
When we do option one or option three, we need to perform Marshalling.
Marshalling (aka Serilization, Pickling)
Converting data to standard network order, then marshalling across in order, and reconverting it to the desired format.
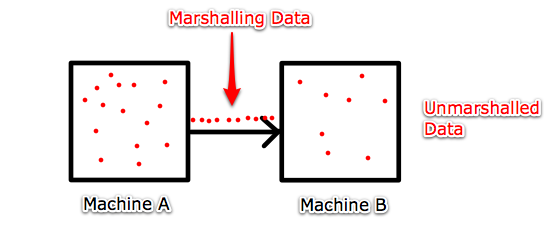
In the big endian/little endian example, a little endian machine would have to convert the data it wants to send over into big endian, marshall it along the network, then the machine at the other end converts it from big endian to whatever it needs.
It would be such a pain to marshall every time you wanted to do a function call. What actually happens in an RPC-based system is that the Application calls a simple function, like close or write. Underneath in the Network Code there are a bunch of sends and receives. And inbetween, there are some Stubs. These are automatically generated from a protocol description.
So in effect, you write a little program (written in a C-like language) that describes what the network protocol looks like and describes the stubs that you want. Then the compiler will automatically generate the code that does this network interface.
An example of RPC in action is the X Windowing System
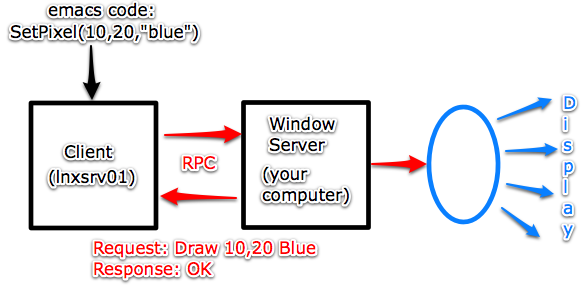
In this example, our emacs code wants to make a pixel on our monitor blue. It sends RPC request to do so, it gets a response back, and the pixel turns blue on our machine.
Can you think of an RPC that you use every day?
It turns out HTTP, the Hypertext Transfer Protocol, is an example of an RPC. You send a request, you get a response back.
How RPC Fails
A big advantage is that we get hard modularity, but we also get some disadvantages as well.
RPC Failure Modes:- Lost messages
- Duplicate messages
- Corrupted messages
- Network might be down or slow
- Server might be down or slow
Solutions:
- If no response, resend request
- Resending the request is not always the right approach.
- Suppose we try to transfer $1000, but no response. We would attempt transferring the $1000 again, which may result in $2000 getting transferred.
- If no response, report an error to the caller.
The above are the two major simple ways of handling errors in RPC.
AT-LEAST-ONCE-RPC:
- An example of this is resending the request if no response is heard.
- We would want this in cases like our draw pixels example.
- At-least-once-RPC doesn't work so well for the banking transfer situation.
AT-MOST-ONCE-RPC:
- An example of this is sending an error message if no response is heard.
- This would be a proper procedure for the bank transfer situation.
While all this is good, what we want is EXACLTY-ONCE-RPC. Unfortunately, it is very hard to implement. So hard that we've practically given it up. It is simply not done.
Performance Issues That Could Really Hurt RPC
Suppose with emacs, we're drawing a bunch of blue pixels on the screen. Machine A sends a request to draw a blue pixel. Machine B responds OK and the pixel is drawn. Now A sends another request to draw another blue pixel. Machine B responds OK and draws another pixel.
The performance is going to stink. You're spending most of your time waiting for the bytes to fly over the wire, you have some decoding overhead, and the actual amount of time you're doing any real work is practically zero!
One way to avoid this is to coalesce pattern calls. Instead of the the drawPixel command, use DrawRectangle((10,20,5),Blue).
However, this complicates the API unnecessarily.
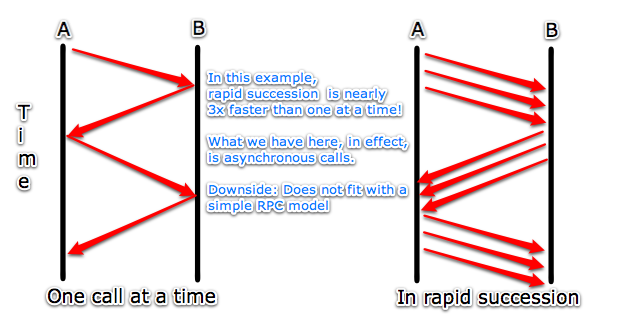
Instead, what we do is send requests in rapid succession as fast as you can and not wait for responses. The responses will also come back in rapid succession. If the amount of work necessary to satisfy the request is relatively small, this approach can be way faster. (The assumption is that there is a wire bewteen A and B, so you can't really send requests in parallel.)
What we have, in effect, is asynchronous calls.
What if an outstanding request fails?
We could either have all outstanding requests be independent,
Or be prepared for such asynchronous failures.
Next week, we will combine RAID and RPC in our next topic: Network File Systems.