CS 111 Scribe Notes November 23rd, 2010
Lecture 16: Media Faults, RAID, and Distributed Systems
Kevin Hutchins
Media Faults
Assumptions:
1. Assume drive can fail, but power remains.
2. Assume failures are dectable. Failures are typically detected on read, but can be detected on write. To catch problems as quickly as possible, use read-after-write (read after every write to ensure correctness). This improves checking quality, but is much slower on disks, because we have to wait for the disk to rotate to the correct sector again.
- Media faults cannot be solved by logging.
- We might, however, be somewhat better off, because we will have a duplicate of the data.
- We would be better off using RAID.
RAID
- RAID used to mean redundant array of inexpensive disks.
- It's now more accurate to view it as redundant array of independent disks.
RAID 0 - Concatenation
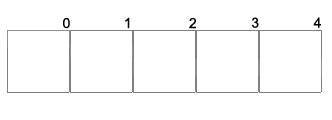
- To the user it looks like one big drive.
- It offers larger capacity for a smaller amount of money.
- Reliability is that of all the drives multiplied together.
- For instance, if all 4 drives have reliability 0.9, the total reliability is 0.9^4, or 0.6561.
- If done correctly, it reads up to 4x as fast.
RAID 1 - Mirroring
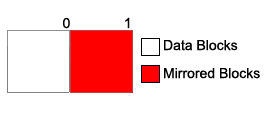
- When writing, both drives must be written to.
- Reads from one drive initially.
- If there's an error, it reads from the other drive.
- Reads are 2x as fast, due to having two read heads.
- Writes are slower because you have to wait for both drives to be written to.
- You need 100% more space than if you were to operate without using RAID.
RAID 0+1 and 1+0
- You can concatenate mirrored disks.
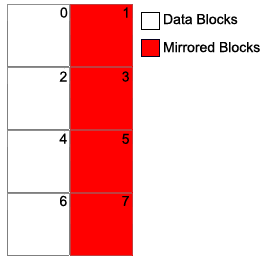
The odd drives are mirrors of the even drives. Each drive pair is concatenated together.
- Can mirror concatenated disks
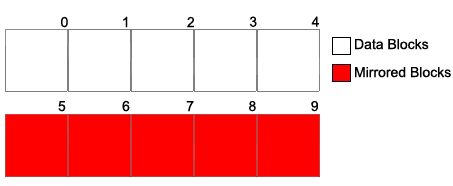
Drives 0-4 and drives 5-9 are concatenated together. Drives 5-9 are a mirror of drives 0-4.
- At a high level, these have similar performance.
David Patterson
- Responsible for acronym and classification of redundant disk strategies RAID 0 - RAID 5
RAID 4 - Block-level striping with dedicated parity
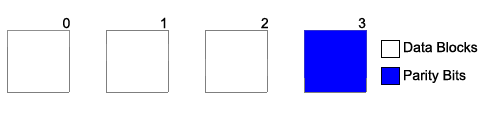
- Drives 0-3 are concatenated together.
- The parity disk is an XOR of disks 0-3.
- A write requires a write to both the disk the data is on and the parity disk as well as a read from the disk the data is on before writing (unless cached) for the purpose of determining the new value for the parity disk.
- The parity disk is a bottleneck, as we always have to write to the parity disk.
- If a drive is lost, performance is very slow until the drive is reconstructed.
- However, drives still can be reconstructed (even the parity disk)
- Adding a drive is trivial.
- Just initialize with all zeros.
RAID 5 - Block-level striping with distributed parity
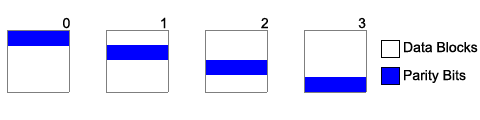
- The hotspot for parity is spread out.
- This is the most complex of the drives covered in this course.
- If a drive is lost, performance is very slow until the drive is reconstructed.
- However, drives still can be reconstructed (even the parity disk)
- Adding or removing a drive is difficult.
- All the parity portions need to be resized and recalculated, and the data must be moved around to accomodate it.
Failure Rates
Terminology:
- MTTF - Mean time to failure
- MTBF - Mean time between failures
- MTTR - Mean time to repair
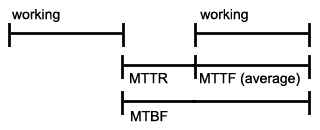
- Availability = MTTF/MTBF
- Downtime = 1 - Availability
- MTTF of disk = 300,000 ~= 34 years
- This is a misleading measure, no one really knows, but it's probably lower.
- AFR (Annualized Failure Rate) is a more meaningful measurement
- A normal bathtub curve would be expected, but the data doesn't represent that.
- In reality, it starts low (due to factory testing), then trends sharply upwards and levels off at about 10%.
- The RAID 5 failure rate increases more sharply and to a higher percentage. This is due to the fact that if two drives fail, all the drives are toast.
- Many RAID boxes have a hot space they switch to in case of a failure.
- ASSUMPTION: Failures are independent.
Distributed Systems
- Distributed systems cannot drop into kernel mode.
- They use message passing.
- Specifically, they use remote procedure calls (RPC)
- Abstracted to look like a normal function, like close(19).
- Underneath the hood, it's very different
- Hard modularity is obtained for free due to its nature.
- On the other hand, we lose call by reference, because there is no shared address space.
- It is limited by network bandwidth.
- It is far less secure.
- Messages can get lost or duplicated.
- The server can become a bottleneck (however, this can happen to anything)
- Machines may have different architecture.
- This can lead to issues in interpretation.
- For example, big-endian vs. little-endian
Dealing with architectural differences
- Standard interchange format: XML text (this has a considerable network + CPU overhead)
- Have everybody know everybody else's architecture (this doesn't scare, O(N^2))
- Standardize on big-endian (this is how it is done on the net)
- This is what is normally done.
- It's the same for every other difference.
- In the case of big-endian vs. little-endian, there's a machine instruction in x86 that swaps back and forth between the two.
- Marshalling: Converting data in memory to a data format suitable for storage or transmission.
- This is also known as serialization, or pickling.
- It's a pain to do this every time you do a function call.
- Stubs (automatically derived from a protocol description)
Example of RPC
Scenario: A client talking to a window server.
Request: Draw 10 20 blue
Response: OK
Result: The pixel at coordinates (10,20) is turned blue.
- In order to optiomize, commands could be combined into more complicated commands.
- For example, there could be a rectangle command to draw a rectangle, instead of just a point.
- This complicates the API further though.
RPC Failure Modes
- Lost messages
- Duplicated messages
- Corrupted messages
- Network may be down or slow
- Server may be down or slow
Solutions for Lost Messages:
AT-LEAST-ONCE RPC: If no response, resend the request (this isn't always the correct action to take).
AT-MOST-ONCE RPC: If no response, report an error.
EXACTLY-ONCE RPC: This is the ideal. It is also very hard.
Performance Issues
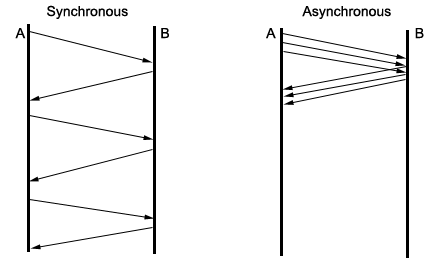
- Travel time between computers if often the source of the most delay.
- In order to alleviate this, we can use asynchronous calls.
- However, this can cause other problems, as if calls depend on each other, a earlier call failing can corrupt the state of the program.
- Another solution is to coalesce calls.
- For example, there could be a rectangle command to draw a rectangle, instead of just a point.
- This complicates the API further.