Media Fault
Assumptions:
drives can fail even if power doesn't
assume the failures are detectable. (the failures are on read typically, but can also be on write.)
Approach 1 read-after-write
+ no error
+ improves checking
- really slow because the sector has to come around for disk (rotational latency)
- errors are not discovered until it is read again later.
Approach 2 RAID - redundant array of inexpensive (or independent) disks
Incentives:
Ten 1-TB drivers are cheaper than one 10-TB drive.
The drives will fail independently (If one drive fails, the other ones will still be okay.)
Cascading multiple drives to look like one big drive. (Big capacity, cheaper)
RAID is a technology that provides increased storage reliability through redundancy, combining multiple relatively low-cost, less-reliable disk drives components into a logical unit where all drives in the array are interdependent.
The concept was first defined by David Patterson.
Striping- In computers that use multiple hard disk systems, disk striping is the process of dividing a body of data into blocks and spreding the data blocks across several partitions
In the figure for RAID 0, disk 1 is partitioned to A1, A3, A5 and so on.
Raid 0
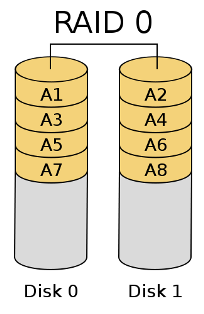
- RAID 0 can use concatenation and striping. Each disk store a contingous amount of data. This allows a user to grow the size of RAID 0 easily by adding more disks.
- It can also use striping to spread out the data neighboring blocks across mutliple disks, allowing performance boost on sequential read and writes.
- Reliability depends on its weakest drive, because RAID0 has no redundancy and no way of recovering a drive when it fails.
- If there were a probability of 5% that the disk would fail within three years, in a two disk array, that probability would be upped to
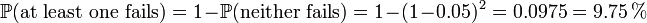
Raid 1 Mirroring
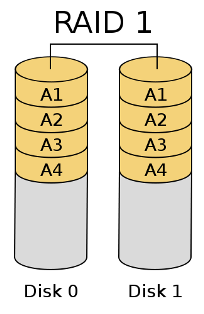
- Do a write to both disk
- Only need to read from one, because the assumption was that read fails are detectable.
- Mirror write hurts performance. (have to write twice)
- Reliability-data is only lost if multiple failure happens simultaneously.
- As an example, consider a RAID 1 with two identical models of a disk drive with a 5% probability that the disk would fail within three years.
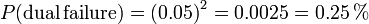
Raid 10 and RAID 0+1
Concantenate Mirror Disks
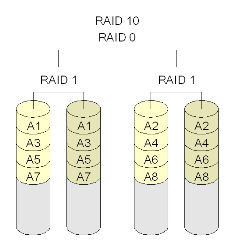
Mirror Concantenate Disks
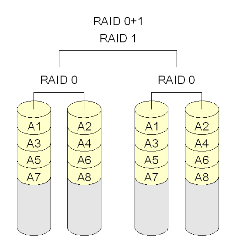
- Here the two approaches combines the methods of RAID 0 and RAID 1.
- In reality, real systems are often implemented as combination of more than one RAID level.
- In high level, the two approaches make little differences and have the same performance.
Raid 2 and RAID 4
In RAID 2 (bit-level striping with dedicated Hamming-code parity), all disk spindle rotation is synchronized, and data is striped such that each sequential bit is on a different disk. Hamming-code parity is calculated across corresponding bits on disks and stored on one or more parity disks.
-Basically, there is almost one entire disk used for bit parity for every data disk. This RAID level has twice the cost and same capacity and is not used today.
RAID 4
- similar to RAID 2 but bring down the overhead from 100% to 25%.
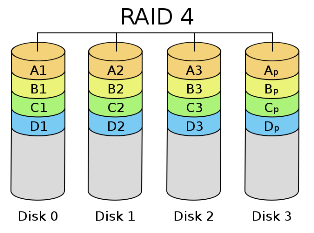
Disk 3 contains the XOR bit parity of Disk 0 -2
-The dedicated parity disk contains the XOR of the corresponding section of the remaining disks.
-If any one disk fails, you can perform an XOR to recover the disk that is lost.
-Reading from disk should be relatively fast.
- RAID 4 is best used in a monitored environment where someone can replace the disk right away when it fails, because multiple disk failure will make data unrecoverable.
Disadvantages
- CPU overhead to perform XOR
- Write is more expensive(2 writes(write to data disk and write to parity disk) and 1 read (read the old bit to perform XOR))
- Parity disk becomes a hot spot(bottleneck), you can't write in parallel because the disk arm has to move in disk 3.
RAID 5
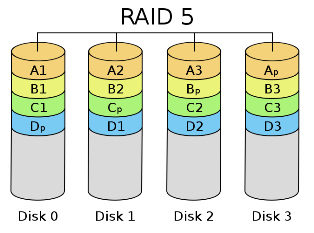
Raid 5 distributes the parity data across all the disks to disfuses the hot spot.
Disadvantages
- more complicated
- harder to grow (adding new drive to raid4 just needs to perform an XOR, adding new drive to raid 5 requires a new partition)
Failure Rates Terminology
Mean Time to Failure (MTTF) - estimated time until a component's first failure or disruption
Mean Time Between Failures (MTBF) - estimated time between inherent failures of a system during operation
Mean Time To Repair (MTTR) - estimated time required to repair a failed component or device
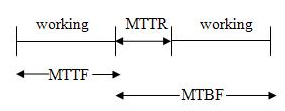
Availability = MTTF / MTBF
Downtime = 1 - Availability
MTTF of disk = 300,000 hours
Annualized Failure Rate (AFR) - relation between the MTBF and the hours that a number of devices are run per year, expressed in percent
AFR for real disks at Google
- In 2007, Google researchers released a paper entitled "Failure Trends in a Large Disk Drive Population" that examined the hard drive failures in Google's infrastructure
- More than 100,00 disks were used; combination of serial and parallel ATA drives varying in speed and size
- AFR was much higher than expected
- Little correlation between failure rates and either elevated temperature or activity levels
- SMART parameters (scan errors, reallocation counts, offline reallocation counts, and probational counts) significantly impact failure probability
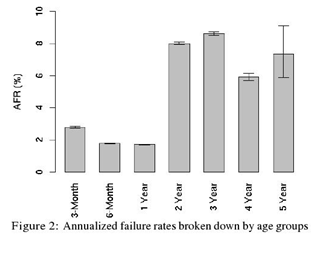 The google AFR doesn't show the initial shakeout, which is the disk that fails because of manufacturing defects. After the shakeout, the drives wears out from age over time.
The google AFR doesn't show the initial shakeout, which is the disk that fails because of manufacturing defects. After the shakeout, the drives wears out from age over time.
Distributed Systems
Application that executes a collection of protocols to coordinate the actions of multiple processes on a network, such that all components cooperatively perform tasks
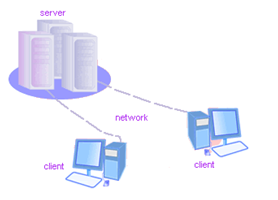 The server provides some service and the client uses that service. (Request - response)
Advantages
- Hard modularity is free because the caller and callee are on different machines
- Ability to connect remote users with remote resources
The server provides some service and the client uses that service. (Request - response)
Advantages
- Hard modularity is free because the caller and callee are on different machines
- Ability to connect remote users with remote resources
Disadavantages
- No call by reference because the address space isn't shared
- Limited by network bandwidth
- Security
- Messages can get lost or duplicated
- Service can become a bottleneck
- Caller might be x86 while the callee is x86-64
Dealing with Architectural Differences
- Standard interchange format: XML text (considerable network CPU overhead)
- Have everybody know everybody else's architecture (N2 problems)
- Standardize on big endian (use machine instructions to swap)
Marshalling / Serialization / Pickling
Serialization is defined as converting a data structure or object into a sequence of bits so that it can be stored or transmitted. These sequences of bits are chosen at the user's discretion but usually formed as XML or binary. Similarly, marshalling converts managed data types into unmanaged data types. However, to marshal, you change its type name not its contents. When you serialize, you convert it to another form so it's completely changed. Essentially, serialization copies the entire object, not just "referencing" it.
Remote Procedure Calls
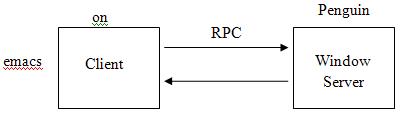
X window system
System and network protocol that provides a GUI for networked computers. It allows software written to use a set of commands to control the hardware. The X server communications with display client program using RPC.
 HTTP
Hypertext Transfer Protocol is an application-level protocol used by the World Wide Web. RPC clients connect across the Internet to RPC server programs and execute remote procedure calls.
An example request and response:
HTTP
Hypertext Transfer Protocol is an application-level protocol used by the World Wide Web. RPC clients connect across the Internet to RPC server programs and execute remote procedure calls.
An example request and response:
 Remote Procedure Calls Failures
Remote Procedure Calls Failures
- Messages sent may be:
- Lost
- Duplicated
- Corrupted
- Network may be down
- Server may be down
- Solution:
- If there is no response from the server, resend the request. This is not always right so there exists workarounds. Otherwise, report an error to the caller (return -1)
- Different semantics have been proposed for the number of remote invocations:
- At-least-once: call executes at least once as long as the server does not fail. This method requires little overhead and thus is easy to implement
- At-most-once: call executes at most once, in some cases not at all depending on the status of the server.
- Exactly-once: calls executes exactly once. This is the most useful but is the hardest to implement. If the client transmits a request and the server crashes, the client has no way of knowing whether the server had received the request.
RPC Performance
Using asynchronous calls may improve the throughput of RPC requests (3x faster). The client sends several requests immediately without the delay of waiting for the responses from the server.
writePixel(10, 20, BLUE);
writeRectangle(10,3,5,7, BLUE);
Writing the rectangle is like batching compared to writing the pixel.
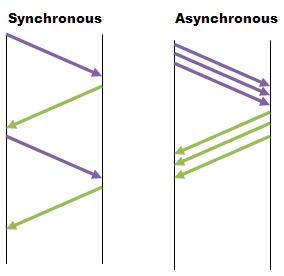 Synchronous RPC
Synchronous RPC - The client sends a single message to the server and waits for a response from the server before sending the next message. As demonstrated in the figure it requires a lot more time.
Asynchronous RPC - The client sends several messages at once without waiting for the response from the server. It is assumed that this client can accept out of order requests.
If an outstanding request fails?
Outstanding requests are independent
Must be prepared for asynchronous failures