Multiple problems in file system
1) We want every large, very fast
memory
(in terms of TBs) and low latency.Ideally we want the file system to perform as fast as a processor can do. A large memory can be slow when we have multiple TBs space. What we have in practice is a small memory that is fast (0.5 ns latency) with a few KiB.
One standard solution is to cache like crazy.
On a typical CPU, we have
| Device |
Capacity |
Visible to Hardware |
Visible to Software |
| Registers |
few KiB |
x |
|
| L1 Cache |
MiB |
x |
|
| L2 Cache |
MiB |
x |
|
| L3 Cache |
~16 MiB |
x |
|
| RAM |
32 GiB |
x |
x |
| Disk |
Lots of TB |
x |
|
| Flash/NVRAM |
~TB range |
x |
|
| Archival
(network, server, etc) |
Lots of PB |
x |
Note: KiB = Kilobytes, MiB = Megabytes, TB = Terabytes, and PB =
Petabytes
The big idea here is use as much cache as you can.
2) Unreliable Problems: Bad Memory References
Examples include null pointers, subscript errors, dangling pointers. Dangling pointers can step on each other, and can modify other memory. This can crash other programs as well as the rest of the system.
How to solve this problem of bad memory references?
a) Ignore the problem. (This might work for economic reason.)
b) Hire better programmers! (This however does not work for economic reason.)
c) Get help from the OS. (This turns out to be the sweet spot on design space. We will focus on this.)
d) N-version Programming (Have a problem you want to solve. Have n teams try to solve one problem, and we run their solution. If they agree then we use their solution, if they do not then we let them vote. But how are we going to vote? Make a voting program? Do we need N-versions of that program too? This is not optimal for economic reason.)
e) Add run-time checking in software to every memory reference (Slow, but can be optimized, some optimization can be done. However, programs will still crash in runtime).
f) do e) in hardware (Nobody buys it because you cannot beat Intel)
g) design and use better programming languages (i.e. Java cannot have dangling pointer because it assumes garbage collection).
So now, we need help from the OS such that the processes can screw up only themselves and do not let them infect the entire system. This is called fault isolation.
Cache Coherency
RAM disagrees with disk (and we say that RAM is right)This is because we modify RAM (file system is partly in RAM and partly on disk)
RAM is under software cache control.
Caches L1, L2, L3 are invisible to software.
NOTE: In the case of bad references, all cache can determine is how fast you can follow bad pointers.
What about multiple programs running in the memory at the same time?
We can add register so we can have the computer get help from the OS.
They are base-bounds pairs (2 hardware registers that will live in process descriptor)
We set the base bound pairs as the section of RAM that we can access.
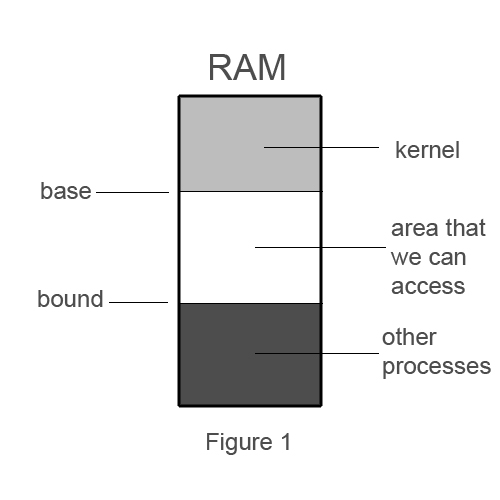
What about virtual memory? Does that work?
No, virtual memory is basically the disk on steroids!
The solution proposed was to get rid of load and store, every time we do a load we need to ask the kernel through system calls, will not need the registers.
But this gives very bad performance
We would give permission for program to access
THIS SOLUTION SLOWS US DOWN!
We need to ask the hardware for help! We call this hardware acceleration.
We can cheat by manually setting base and bound, these registers have to be privileged
They can only be modified by privileged instructions, or by the kernel.
We must make a system call in order to ask for more RAM everytime we want to grow.
However, if you ask to grow and there is someone next to you, you will have a problem.
Base Bound Pairs (bounds need privileges to be modified by issuing system calls)
+ we are catching bad reference
- require contiguous allocation of RAM, which suffers external fragmentation
- works only if total RAM used is known, cannot easily grow processes (it is hard to find out the sizes of processes in advance)
- code must be relocatable, meaning it must not have absolute address, must be relative to process only);
to fix this problem, we can add the base to each access
- can't easily share library, no sharing of code, nicer if we have 1 copy for 2 identical processes
Suppose we run 2 copies of python:
If we try to access the code at the memory address 0x1000 and we realize that 0x1000 is above our base, then we will crash
To fix this we add the base address to each of the address
This fixes the need for code to be relocatable (relative to top and no absolute address) and the inability to share libraries and code:
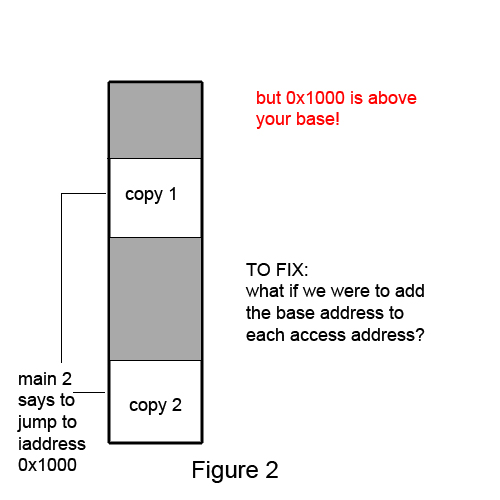
Let's extend the idea: Multiple base-bounds pairs
(e.g. one for the program, another for data (have 4 registers): then we can share the same code)
We find that 2 base bound pairs are usually not enough so we need lots of them
Let's say we have 256 pairs of registers (how do we decide which base bounds pair to associate?)
To fix, we can do the following:
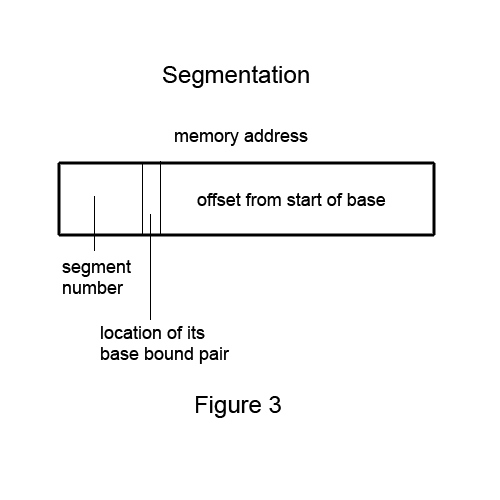
This is called segmentation.
Usually in a program we have: (each of them identified by a segment number)
1) Python code
2) Math library code
3) Data code
4) Stack
5) Stack variables
6) Heap
What's the advantage of segmentation?
We ask the operating system: Please grow segment 6 (heaps)!
We can move the segment somewhere else and we don't need to leave them where they are.
Segments also have permissions
r = load
w = store
x = execute
What if we have the following?
--- : can't do anything (maybe as a placeholder)
--x : don't want the application code to be read, execute only (protected code)
-w- : kind of useless, can be useful if you write when someone has to read (message passage)
-wx : let you do self modify code but do not let you see your work (weird)
However, not all hardware support all these combinations, some hardware doesn't have support for the x bit at all!
INTEL: it used to be that if you can read something, you can also execute them!
But later on Intel was forced to add the execute bit due to security reasons (buffer overrun).
In the case of a buffer overrun, if we have the x-bit and we turn off the x-bit then we cannot run code that they overran.
Therefore, we need to support x-bit because of buffer overwrite attack. Our defense = turn off the x bit.
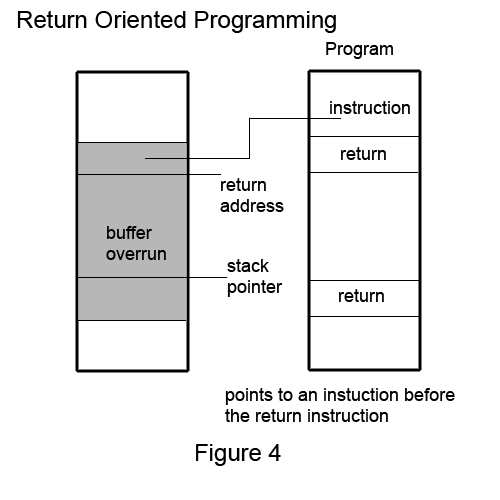
ROP (Return Oriented Programming)
Assume: you can't execute the stack, but you can overwrite the stack, and you want to execute whatever instructions you like... can you do this! YES!
You will still be able to execute any code despite x-bit being off!
This is done overrunning the stack and then leveraging the control of the stack to run instructions that are located before a return instruction.
We will be just powerful enough to build a Turing Machine!
Segmentation (in x86)
- change segment sizes is a pain (big problems)
- relocatable programs/data needed
The above two are bureaucratic nightmare
For each object, we need to agree on which segment it lives in
Our solution is paging.
Paging
+ fixed size pages! This means no more external fragmentation!
+ allocation address/offsets now looks just like segmentation
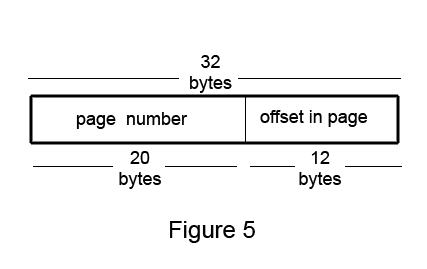
Now let's say we have a magic box that keeps track of virtual and physical pages
We will have a page fault if the page we are trying to access is not in the table or if it is violating permissions (almost like a trap)
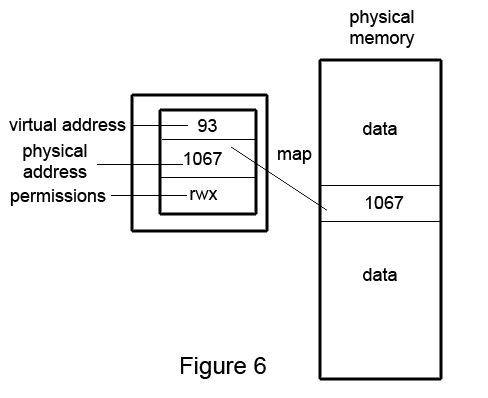
What if we have a virtual page number 95 and some offset and the physical page doesn't exist? We get a page fault!
In response to a page fault a kernel can:
1) abort the process
2) raise a signal (SEGV) which will call a handler
3) kernel gets to decide on what to do when signal handler returns
when the handler returns, kernel can either retry segment or abort
4) kernel can give you a new page (basically fix magic box to allow access)
this happens because we may be using virtual memory as cache
in this case, we see the physical RAM as a bigger cache for the virtual memory
This is why we can run a process that is bigger than our RAM!
(e.g. physical ram as a cache for virtual RAM)
We can run a 3GB process with ONLY 2 GB RAM
This is a big selling point!
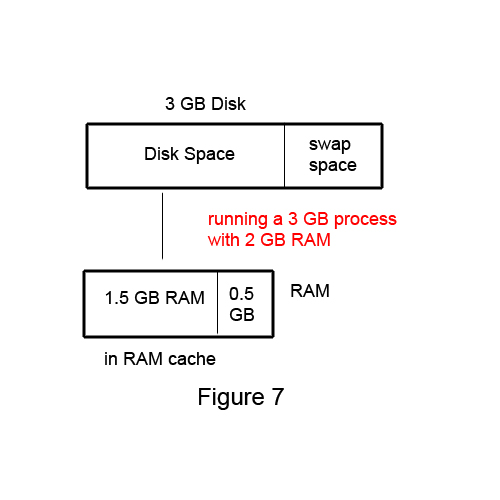
We get more than we paid for!
We bring it into RAM and run the program.
If the set of pages is small then there is almost no penalty.
It works with LOCALITY OF REFERENCE.
However, it fails when we have a lot of random access pages and we begin going to disk.
This process is called thrashing.
When we thrash we do random access to the hard drive instead of RAM
This slows down our performance by a factor of 1000!
Note: the swap space is totally junk on boot.
How to Implement MAGIC BOX
The simplest approach is to use a linear array:
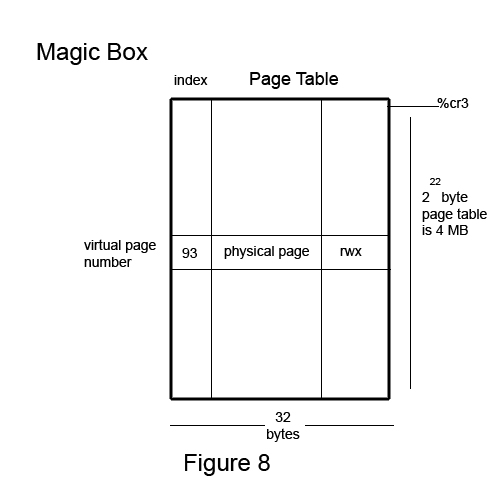
We have a register reserved for the array called cr3
%cr3 is a privilege register (every process has its own cr3)
In principle, hardware consults table for permission
In actuality, hardware really "caches it like crazy"
The cr3 register points to the base of the address
In the x86:
We have 232 addresses, 4096 byte sized pages
Meaning, we will have 220 virtual pages
This approach do not work well for small processes, because most of them will be empty or 0.
Perhaps a better way is the 2-Level Pages Table:
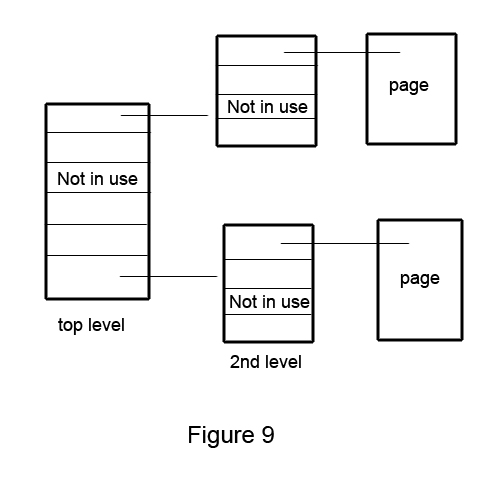
We implement it by:
size_t pmap (size_t vpn) {size_t hi = vpn >> 10;size_t lo = vpn & (1 << 10) - 1;size_t *lopage = cr3[hi]; //points to 2nd level pageif (lopage == FAULT) return FAULT;return lopage[lo]}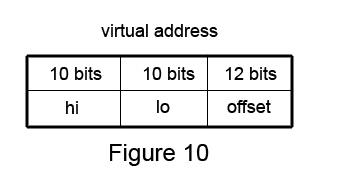
How do we take care of it?
pfault(vs, cal, atype) {
if (swapmap(current, va) == FAIL) // where does va map to an
disk for the
current process
kill(current, SEGU);
else { //look into RAM to put page
//walk through
RAM and look for victim
(p, va') = removal_policy(); // looks at all RAM and
removes the victim
page
pa = p->pmap(va);
write pa to disk at swapmap(p, va');
read pa from disk at swapmap(current, va');
current->pmap(va); // update physical map to mark
that we now own
this page
p->pmap(va) = FAULT:
current->pmap(va) = pa;
}
1. It takes about 20ms for read + write. We can let some other processes runs while waiting.
2. pa = physical address