CS 111, FALL 2010
Lecture 14: Virtual Memory
Presented: Tuesday, November 16, 2010 by Paul Eggert
Prepared by Olga Galchenko, Edvin Zohrabyan, Eduard Sedakov.
Memory Problems
Large and Slow vs. Little and Fast
Ideally, we want very large, very fast memory (want like 0.5 ns latency).
Nowadays, memory improvement trend is directed towards increase in capacity, yet, access time of the new storages often stays the same, and in some cases even slows down. What should we do, if it is in our interest to have a fast and large memory? Of course, terms such as "fast" and "large" are often found to be quite ambiguous. However, nowadays it seems already common to consider the storage size on the order of few terabytes, while the speed of an access to be no longer than a few processor cycles.
On a typical server CPU's these days we have:
|
Storage Type |
Approximate Memory Range |
|
Registers (top of the hierarchy) |
32 to 64 bits |
|
L1 cache |
Few kilobytes (16-32 Kb) |
|
L2 cache |
1 Megabyte |
|
L3 cache |
Few Megabytes (2-3 Mb) |
|
RAM |
32 Gigabytes |
|
Flash |
Roughly 1 Terabyte |
|
Disk |
Few Terabytes |
|
Archival Storage |
On the order of few Petabytes |
Correctness Problem
There is a large probability that among all the programs running on the operating system, there will be number of unreliable programs (processes). These programs are unreliable in many ways. One of the ways that is really a killer, is that they have bad memory references. These bad memory references are null pointers, script errors, dangling pointers, etc. Such processes have real potential to corrupt memory of the other running programs, and can even crash the system. Suppose, you tell your manager at work that your company has some unreliable programs. What are some possible reactions that you might get?
Ignore the problem! - which sometimes is the most economical thing to do (the cheapest and simplest of all the solutions, and could be technically used on the small embedded systems, where most of the software is written by one programmer).
Hire better programmers. Fire people who write bad programs.
Ask Operating System for help…
N-version programming.
It is possible to implement run-time checking of every memory reference. (done in the software) Obviously, this approach will slow down PC performance.
Then we can try to make run-time checking at the hardware level. Unfortunately, the following idea would be too costly to implement.
Perhaps by using a better language, such as Java or a Python, most memory issues can be solved.
Fault isolation. By providing process isolation, we can most of the times prevent one process from corrupting another. That is we permit problems occur in part of a system, but do not let these troubles kill the integrity of all the system.
Cache Coherence Problem
Since disk accesses tend to be on the order of 1000 times slower than the processor's cycle, operating system tries not to update information that is placed on the disk, unless it is absolutely required. Therefore, changes made to the blocks of data are often getting stored in the caches and RAM. This, however, means that different memory levels may happen to store the same block, stored with different contents, with none matching the original, placed on the actual disk. Each level of memory hierarchy, ideally, should be invisible to the software, yet in practice this idea rarely gets achieved. (возможнонужноразвитьтемудальше)
How can we solve some of these problems?
2.1) Memory Segmentation
The first problem strikes directly at the hardware limitations, so there is not much that can be done at the software level to fix it. Perhaps, the only suggestion would be "to cache like crazy," to lesser an impact of the slow disk. Let's Instead try to address problem # 2 - the correctness issue. Assuming that multiple programs are running at the same time, what should we do to isolate them?
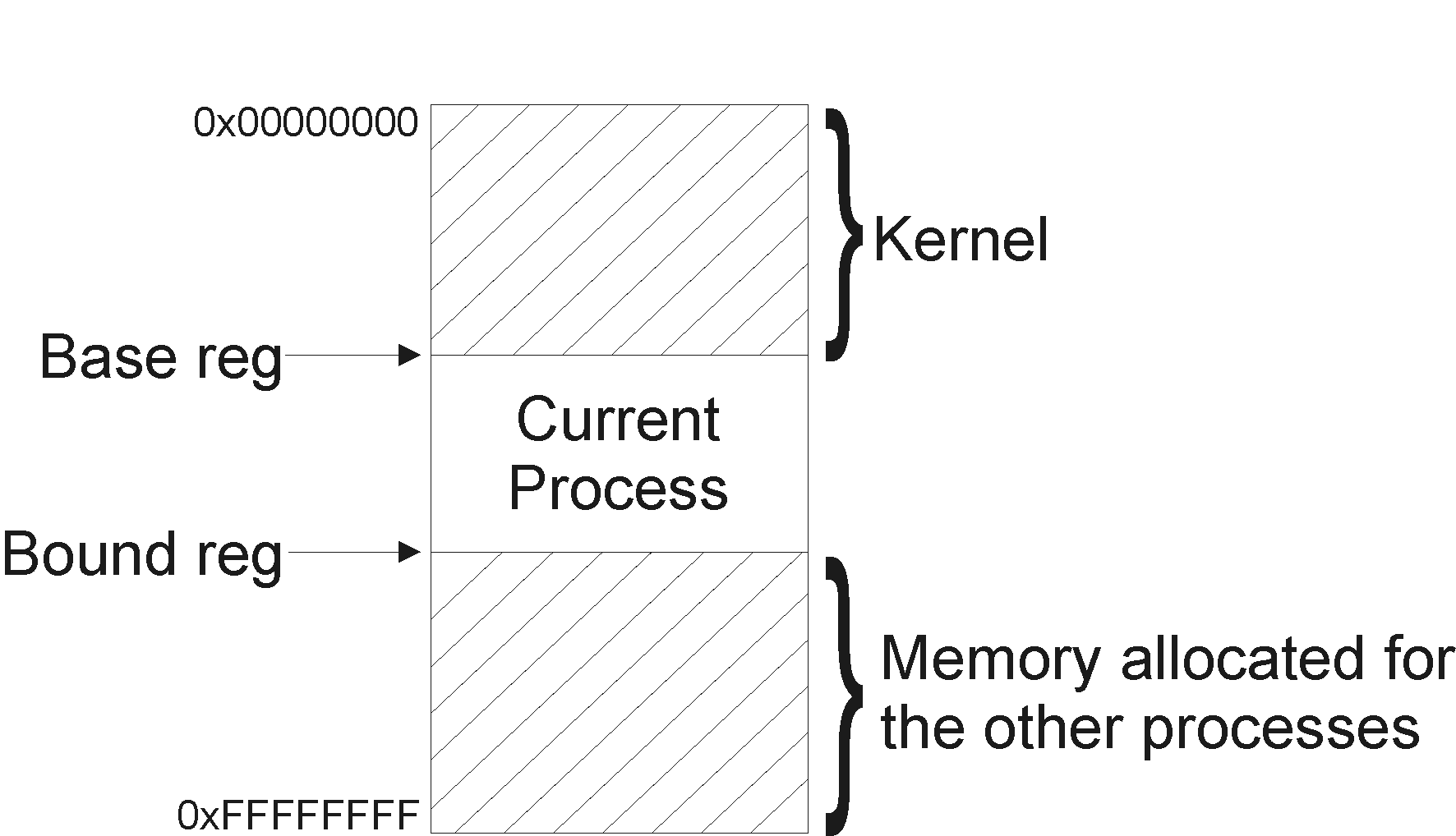
Figure 1. Base and bound registers
We will have to add two hardware registers: base and bound. Base will point at the start of memory segment, allocated for the process, while bound will point at its end.
Technically, isolation is achievable without actually updating the set of registers and making other changes to the hardware implementation. However, to ensure the process isolation in that case, it will be required to change load and store instructions to the system call like functions. Under such circumstances, the kernel will be entirely managing memory allocation and memory mapping. Obvious downside of this approach is its slow performance.
With the use of base - bound pair, we will be able to resolve some of the memory reference problems, but the bad pointers still will remain an issue. In addition, few extra difficulties will arise.
2.2) Problems with the Memory Segments
Base and bound registers can be changed only by privileged instructions. So the kernel can access it, and maybe we can have a system call which can ask kernel to give more RAM. Base - bound pair will maintain isolation, but it will still provide users with an absolute physical addresses. Therefore, programs will have to be placed at specific locations in the memory. Not only such allocation technique will be inconvenient, it will lead to errors when two or more instances of the same program are running. So, if we want this approach to work, the programs have to be relocatable; that is the code should not have any absolute memory references. All the addresses have to be relative to program counter. Can we fix this issue so that we can have absolute memory references? Yes, we can add base to the requested location. This will at least address the absolute memory reference problem.
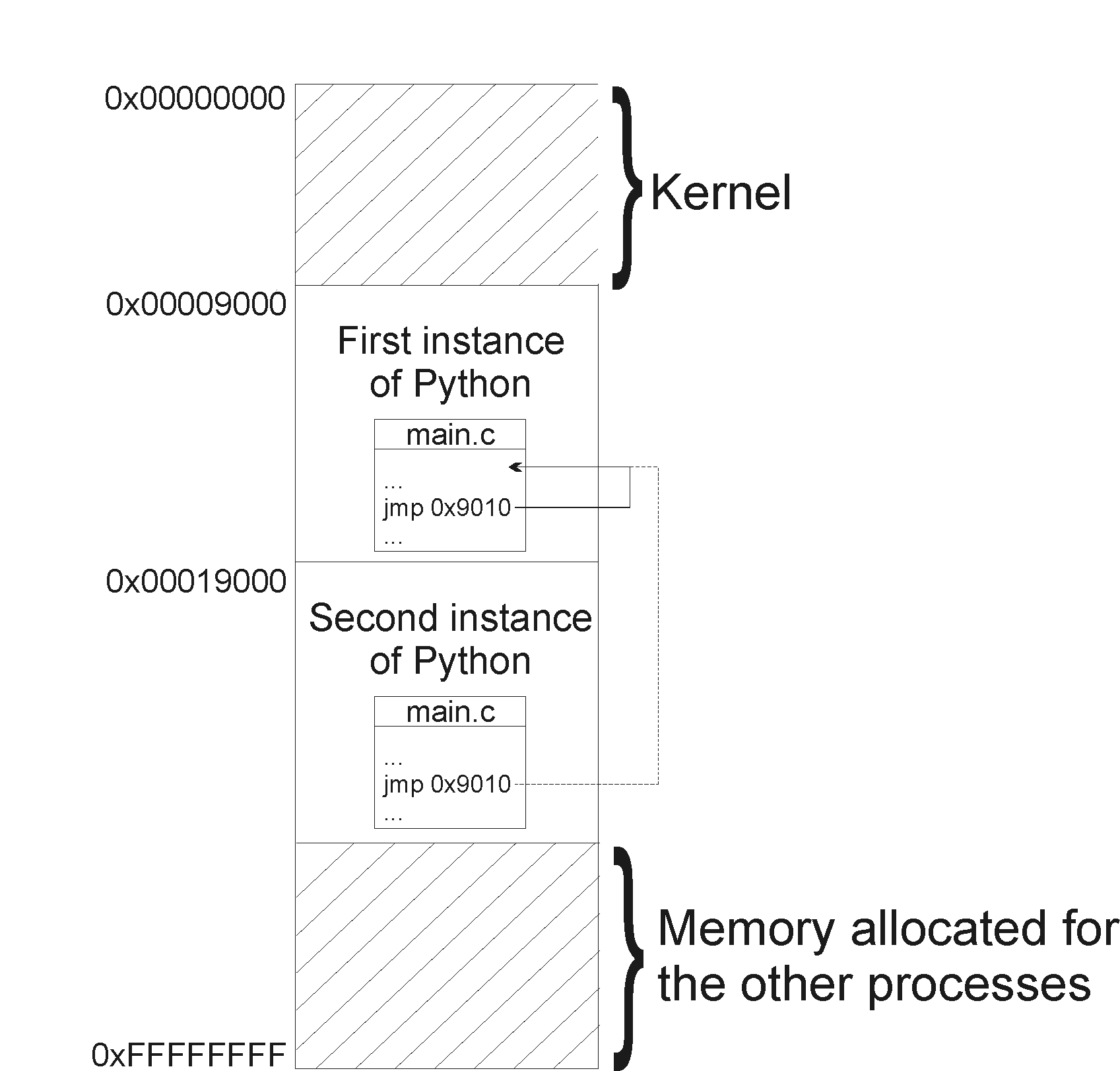
Figure 2. Two Python processes running concurrently. Each tries to use the jump instruction, but due to utilization of the absolute addresses, attempt to jump will not be allowed.
Another downside of this approach: no chasing of code.The approach will require use of contiguous memory allocation for every process, which means we will run into problem with external fragmentation. Disk might have multiple free chunks of memory, but they will be smaller than the demanded size for a single process. In addition, we cannot easily grow processes and no sharing of code here.It will be hard to grow a processes' memory, since again our model requires memory segments to be contiguous.
To fix the problem, we will need to add a base - bound pairs to every process running. Specifically, each process will require 2 pairs: one for the code and the other for the data segment. In addition, processes will not be able to easily share code or use shared libraries. Under this approach, shared piece of code will have to be copied for as many times, as there are processes that want to use it.
Segmented Memory and the Structure
Let's extend the idea of base - bound pairs, and allow ourselves to have multiple base-bound pairs: one for each process. For example, we can have on pair for our program and one pair for the data. Now, we can have multiple programs sharing the same python instance, each with their own set of data. Usually we need to have multiple pairs.
What usually people do, they split the memory address into two pieces. The higher order piece is used to tell the system which base-bound pair is being used, and the lower order piece is the offset from that base. This approach is called segmentation. Also, a segment can have some other information that is relevant to OS. For example, some segments might include permission information of that segment ( load, store, execute ). Not all permission combinations (rwx) are supported in all hardware. Quite a few tend not to implement execution flag; as a matter of fact, Intel has been following such tendency, and only recently added support for the X bit. The reason why Intel went through trouble of changing its implementation was a serious security hole. Because of the missing executable bit, it was actually possible to run any assembly code, placed inside the data segment of the program, or in the stack. The latter case was particularly known for its use in the buffer overflow attacks.
2.4) Return Oriented Programming
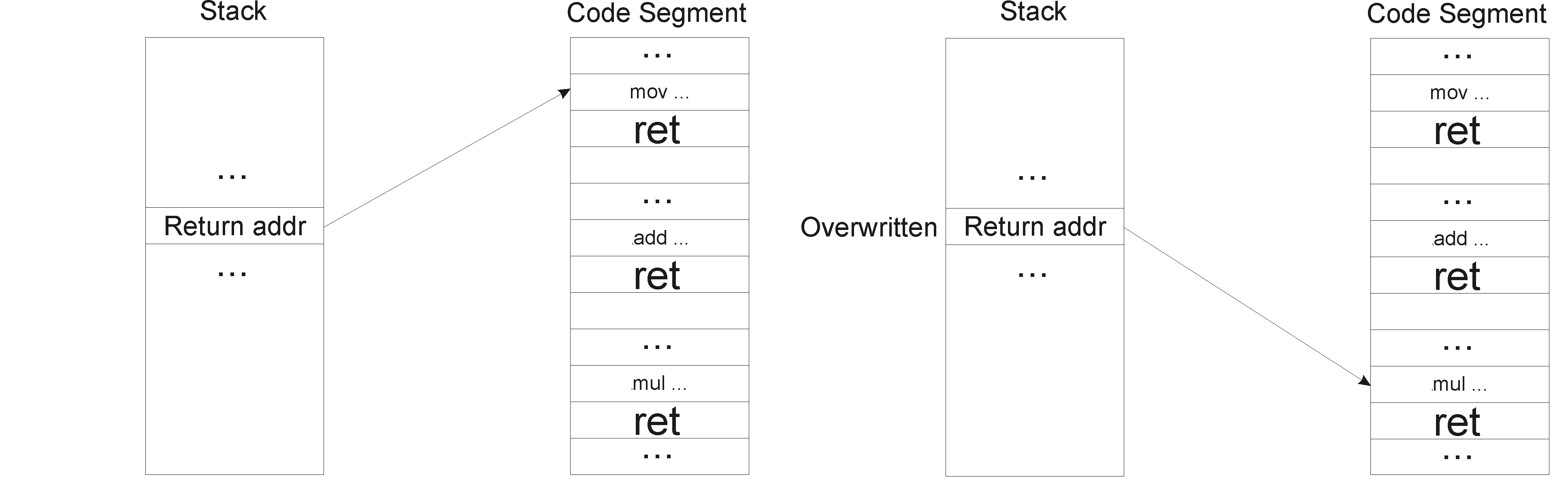
Figure 3. Return Oriented Programming
With the introduction of an X-bit support by the hardware, all the stacks now are declared as non-executable, which pretty much blocks buffer overflow attack. However, that fact alone does not imply that the system is not vulnerable. X-bit does not allow executing the code inside the stack, but no one has prevented us from overwriting the content of the stack, specifically the return address of the currently executing function. With the new overwritten address, we have real ability to jump to any part of the code segment and continue execution from there. The difficulty of this attack is that you really cannot run your own code, but instead have to comprise it from a little fragments of the original victim's code, which are few instructions long and are placed before return instruction. So, we can take control over return addresses and force the program to do whatever we want, assuming that we can't execute the stack, but can overwrite the stack.
Virtual Memory
3.1) Segmentation and Paging
It is very hard to deal with memory segmentation. Changing segment sizes is a big pain. The segments have variable length, it is also hard to relocate them. They have to be comprised of contiguous chunks of memory, which is often difficult to find. Therefore, it is far more common to use pages. They are fixed-size (e.g. 4096 bytes), which makes it easier to reallocate and avoid external fragmentation.
A virtual address is composed of page number and offset. On 32-bit machines, typically, higher 20 bits are used for page number (virtual) and the leftmost 12 bits are used to specify the offset within that page.

Figure 4. Virtual Address Representation
For now, let's assume that the actual translation from virtual addresses into physical addresses is performed by the "magic box". This conversion remained hidden from the perspective of the application.
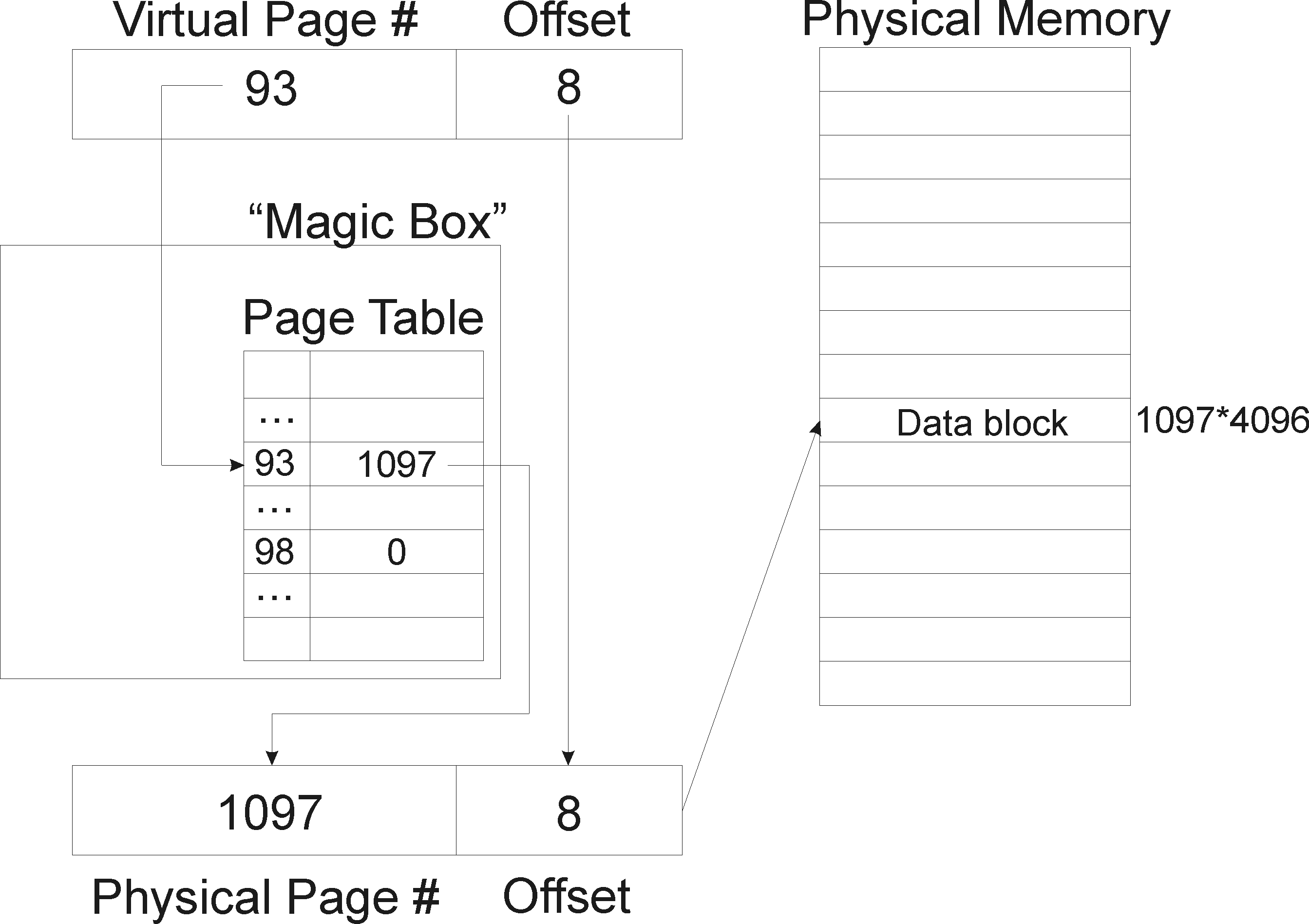
Figure 5. Virtual to Physical Address Translation
3.2) Page Fault
So far, we have been assuming that magic box provides a mapping for every requested virtual page number. What if some of the translations are invalid ? Suppose a user application attempts to access virtual page 98 (see Figure 5), what should the physical page number be? In cases like this, translation mechanism fails, and we have a page fault. Violating permissions by trying to access a page that is not readable or writable would cause a page fault, as well. Therefore, a page fault is one way for a certain memory unit to notify the kernel of the event that could not be locally handled. In other words, page fault can be thought of as a trap. It returns control to the kernel, and it is up to the kernel to decide what to do. The kernel can chose to kill troubling process, ignore the error or can raise SEGV signal. Kernel can fix the "magic box" to allow access by issuing request to the disk for the missing page.
Physical RAM most often works like a cache for the virtual memory. Suppose that a certain process requires 3 Gigabytes of RAM, while operating on a machine that only can provide 2 in the RAM. Under this scenario, roughly half of required memory will be stored in the RAM, while other will be periodically cached from the disk. In the virtual memory table (magic box), if we try to access a page that is on disk but is not cached, will get a page fault. But the kernel can remember which pages are on disk and which are not. Whenever there is a page fault, the kernel can look at the failed address, realize that the reason that this address is not in RAM is that it run out of RAM. Then, it can bring the page from disk to RAM and start executing that part of the program all over again. So, we can run 3GB program on 2GB RAM! This works for locality of reference,
However, it fails when the application really needs to do random access memory. A lot of performance problems in real machines because of the thrashing. Thrashing is when you constantly have to go to the disk because the pages are not in the RAM.
3.3) Magic Box
Up to now, we were mostly concerned with functionality of the magic box. Lets see how it is actually implemented. Magic box can be modeled as a simple linear arrayof virtual page numbers (index), physical page numbers(entry) along with few additional extra bits( e.g. rwx flags - page permissions). Every process has its own page table and a %cr3 register (privileged reg.) that points at page table when the process is running.
Assuming x86 processor architecture, we have
232 virtual addresses.
4096 Bytes page size (212 bytes, so 12 bits are required to specify a specific byte in a page).
232-12 = 220 virtual pages (20 bits for virtual page number).
Every element of the page table will be 4 Bytes wide, and the table itself will include 220 different entries. Therefore, 222 Bytes or 4 Megabytes will be used just to store a single page table. The page table will be allocated per process, even in those cases when processes will need just a small amount of memory. Because of this problem, most file system will end up using multi-level(commonly 2 levels) page tables to reduce wasted space.
The 32-bit virtual address is divided into 3 pieces.
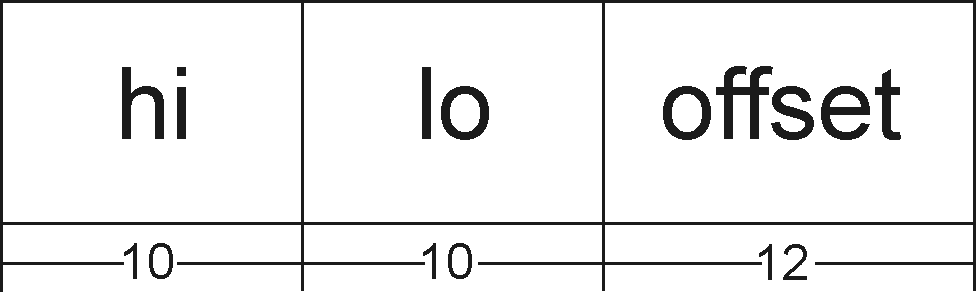
We get the address of the top level page (Page Directory Table) in hi region of the virtual address. We get the address of the 2nd level page (Page table Entries) in the lo region, and the offset in the physical page in the offset region of virtual address.
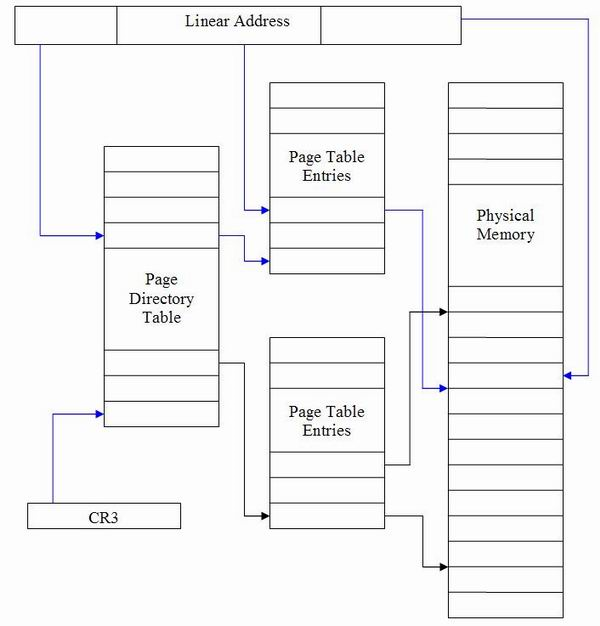
The advantage of this approach is that if you have a small process with not many pages, most of these entries will be zero. Each page has 210 entries with 4 bytes each, so a page is 4096 bytes. If most of the entries of the top-level page are zeros, then the process will not be using a lot of memory.
size_t pmap( size_t vpn )
{
size_t hi = vpn >> 10;
size_t lo = vpn & (1 << 10) - 1;
size_t * low_order_page = %cr3[hi];
if( low_order_page == FAULT )
return -E_FAULT;
return low_order_page[lo];
}
Now, let's take a look at the mechanism for what happens when you get a page fault. The code looks something like this.
void pfault( va, current, atype )
{
if( swapmap( current, va ) == FAULT )
kill( current, SEGU );
else {
(p, va_prime) = removal_policy();
pa = p->map(va_prime);
search for the victim page
write pa to the disk at swapmap( p, va_prime);
read pa from the disk at swapmap( current, va);
// this will take like 20 ms
current->pmap(va) = pa;
p->map(va_prime) =FAULT;
}
}
End lecture notes.