CS 111: Operating Systems Principles
Scribe Notes for 11/16/2010
by Ravi Srinivas Ranganathan, Henrik Arnstorp
Some Problems - Motivations for Virtual Memory:
1. Performance:
We want to have very fast memory that's also very large - we would like to have multiple terabytes of memory that operates at the clock speed of modern processors, a few nanoseconds in latency.In practice we can only have a very small amount of memory at this speed, for example, only the registers can be operated at processor's clock speed. The larger memory we use tends to get slower. To cope with this, we cache like crazy - at multiple levels.
Registers Few KiB L1 Cache KiB Range L2 Cache MB Range L3 Cache Multiple MB RAM Few GiBs
(1 - 32GB normally)Non Volatile memory
Accelerators - Flash, NVRAMGiBs Disk (HDD) Multiple TBs Archival Storage
(Tape, Optical Storage)Many PBs Caches involved in a systemOne of the outcomes of having multiple levels of caches is the necessity for Cache Coherency, i.e. the local copies of data might not match the original as a result of not updating the changes from one part to the other. It is very similar to the idea that's seen in file systems where all the write operations to be performed on disk essentially change a copy in the RAM, following which the changes are committed atomically to the disk. Cache coherency is handled differently at different levels. The caches L1 to L3 are usually invisible to software (slightly idealistic though) while memory units such as RAM and the levels above it are highly software controlled.
2. Correctness Issues:
Programs are inherently unreliable. One of the most important problems is bad memory references - null pointers, subscript errors and dangling pointers. So how do we deal with these unreliable programs that can potentially crash the system?
- Ignore the problem - Seriously?
- Hire better programmers
- Get help from the Operating System
- N-version Programming - Have n teams develop n programs - the best one gets voted and selected as the best program. However, there's the recursive problem of using n version programming to build the best voting software, not to mention the increased cost for building all the software and testing them.
- Add runtime checking to the program in the software - i.e. to check every memory reference that the program handles. As expected this performs poorly; the compiler optimizes the code and reduces the overhead though (for eg. If a loop runs through an array iterating over indices 0 to n, it would suffice to check the validity of access at the bounds 0 and n to determine if all the subscripts are accessing valid memory locations).
- Perform the above procedure e. in the hardware. This has actually been implemented. But since Intel doesn't do this and the idea has not quite been perfected, it hasn't caught on many followers.
- Modify the programming language design. This method is quite popular - it's seen in the Garbage collector implemented in Java which checks that there are no dangling pointers.
Of all the above techniques discussed, method c. is the most significant. By making the Operating System responsible for managing the memory accessed by programs we obtain a fault isolation mechanism which ensures that faults in one part of the system do not infect and bring down each other.
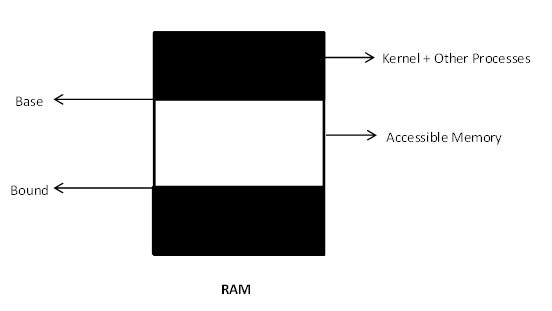
Base Bound Pair:
Use 2 Hardware registers to store the lower and upper bounds of memory that can be accessed by the current process.By imposing restrictions such as the base-bound limits we ensure that a process can only mess up its own memory and hence isolate faults.
One alternative is to implement load and store instructions as privileged so that we can solve the problem without using a base-bound pair. This too would give unacceptable performance as typically there would be a lot of loads and stores that would need to be verified to catch the bad references.
The base bound pair lives in the process descriptors of each process just like any other registers. To prevent processes from modifying their base and bound to obtain unrestricted access, we make them privileged registers. The base bound pair of the Kernel would encompass the entire RAM.
+ All bad references are caught.
- Contiguous allocation of RAM causes external fragmentation.
- You cannot easily grow processes.Consider the case where we run 2 instances of a program, say Python. By the above method, two copies of the program would be loaded into the memory. If there's any absolute memory location based jump in the Python program, the program would crash. Thus, we need re-locatable code. Memory references should be made with respect to the program counter. For example if a program wants to access the memory location n, this can be achieved by adding the base memory location to n. This method does not completely solve the problem though; we still need to have multiple local copies of libraries and the code that could be shared to save space.
One way would be to extend the idea into having multiple base bound pairs - 1 for program, 1 for data. This means we would need 4 registers - which would slow context switches. However, the problem is that even 2 base bound pairs would not suffice. In the above example, one instance of Python might want to include the math library while another might require databases. This solution can therefore be dropped as we would end up requiring a lot of base bound pairs to satisfy our requirements.
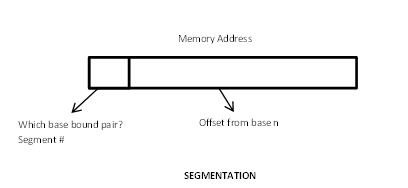
Assume there are 256 base bound pairs. For a memory reference,
The idea is to divide memory into logical regions - as Python's Code, DB Code, Math Library Code, Stack, Static Storage and Heap. We can have the growth of memory segment specific, by issuing commands such as "Please grow segment 6". It would also be easy to move segments around in the memory. Each segment would have a base bound pair, other information about the segment (such as rwx permissions to the given segment). Though fragmentation would still exist, the movable nature of the segments ensures that it can be fixed, albeit a costly defragmentation operation.
Consider a few permissions that a segment can have and situations where they are desirable: (Not all combinations of permissions are actually supported on Hardware).
--- Can only be operated on by the kernel
--x Digital Rights Management
-w- Not of much use. May be used in multi-program environment for message passing.
-wx Weird! Self-modifying invisible code?
A lot of processors didn't support the x bit - an r bit implied that the file was given executable permissions as well. This had to be changed to counteract buffer overflow attacks, which aimed at adding garbage in stack code and then run it. Thus, the x bit had to be disabled.
Return Oriented Programming:
An 'evil' workaround to overcome the x bit disable protection, with almost no defense against it. You can write to stack and you want to use it to execute arbitrary code. In the stack we make the pointer point to a specific instruction within the existing program code, occurring before a return statement. This is then used to jump to another location of similar conditions. Thus, the attacker builds a turing machine with the help of return instructions.Segmentation (in x86): One of the biggest problems with segmentation is the variable size of the segments. Changing the segment size is a big pain, not to mention the necessity to build re-locatable programs / data. It is simply a bureaucratic nightmare for the data structure in the segment.
Paging:
To solve the above problem, we can use fixed size of memory chunks. That way, we won't have to worry about external fragmentation and about moving stuff around.
Consider having 4096 byte pages.
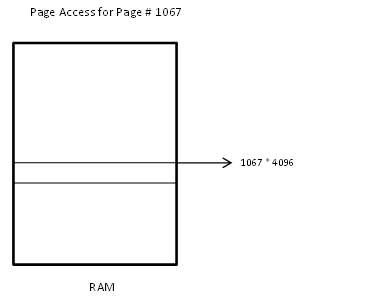
Virtual Memory Layout and Access
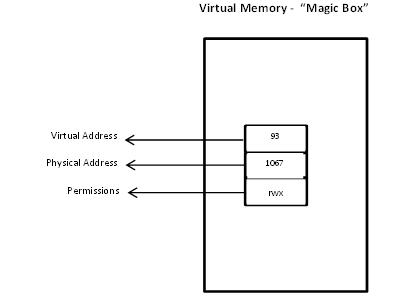
A page fault is an interrupt that occurs when a program tries to map a virtual address whose entry is not there in the page table. It also occurs when permissions are violated. It is a hardware trap - the process state is saved and the execution is shifted to the kernel which can choose to make the program dump core in case of unrecoverable issues or any other action dependent on the situation.
Actions of Kernel upon encountering Page Fault:
- Abort the process
- Ignore the page fault
- Raise a signal SEGV and let the handler take appropriate action (which returns back to the kernel)
- Can give the process a page to map the virtual address access causing the fault, i.e. fixing the "magic box".
The last point that it mentioned above is surprisingly very common. In fact, it helps to achieve one of the USP's of virtual memory - to implement physical RAM as a cache for virtual RAM.
Consider a case where an OS needs to run a process that uses 3 GiB of RAM in a machine with only 2 GiB. Practically, the OS can allocate no more than approximately 1.5GiB for the process as the remaining memory would be required for the OS itself and other processes. The kernel achieves this seemingly impossible goal by moving parts of the process' memory between the RAM and the disk dynamically. The process is allocated as many pages as possible and executed - when it asks for more, a page fault occurs and one of the existing pages is chosen as the victim and moved to the swap space on the disk.
This technique is a huge win if the application exhibits a large locality of reference - if almost all accesses at a given point of time are usually in the cache. Thus, not much penalty would be incurred as page faults. However, lots of random access results in a disaster - a situation known as thrashing. The access speed difference is nearly 1000 times slower in a thrashing program (us (microseconds) for RAM versus the ms access time for disk).
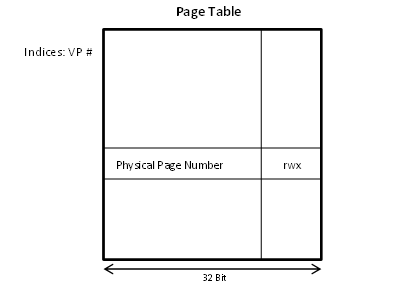
How is a page table built?
Using a simple, linear array, with its base pointer stored in a privileged register cr3 (%cr3).
Consider an x86 machine - you have 232 bits. The size of each page is 4096 bytes, which is 212 bits. Therefore the number of virtual pages is 220. Thus, the size of a page table, assuming 4 bytes per mapping, would work out to 220 * 22, which is roughly 4MB. This would mean a lot of wastage for small processes. To fix this, we use 2 level page tables.
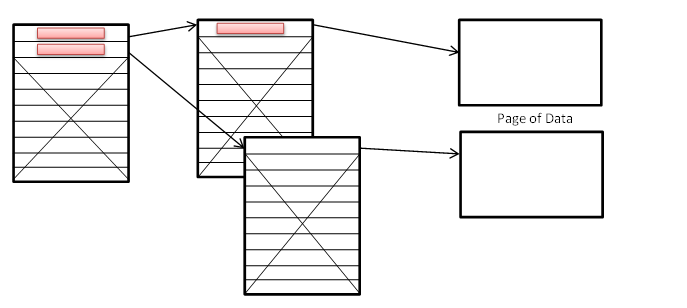 10 bits, each 4 bytes wide = 4 KiB for Hi, Lo and Page Data Size.
10 bits, each 4 bytes wide = 4 KiB for Hi, Lo and Page Data Size.1 size_t page_map(size_t vpn) { 2 size_t hi = vpn >> 10; 3 size_t lo = vpn & (1<<10) -1; 4 size_t *lopage = %cr3[hi]; 5 if(lopage == FAULT) 6 return FAULT; 7 return lopage[lo]; 8 }When you get a page fault:1 pfault(va, current, atype) { 2 // Catch the error case when va does not exist even on the disk! 3 if( swapmap(current,va) == FAULT) 4 kill(current, SEGV); 5 else { 6 (p,va') = removal_policy; 7 pa = p->pmap(va); 8 write pa to disk at swapmap(p,va'); 9 read pa from disk at swapmap(current, va); 10 current->pmap(va) = pa; 11 } 12 p->pmap(va) = FAULT; 13 }where, va - the virtual address that faulted current - a pointer to the current process atype - access type - rwx values va' - victim address p - process owning va'The entire process of swapping takes about 20ms, a huge price for a normal operating system. However in servers, virtual memory is much smoother as the 20ms duration for swapping can be used to make another process run in the background.