
Robustness of Filesystems
Stefan Wojciechowski
(and a discussion of performance)
( Sandwich, http://xkcd.com/149 )
Robustness - A robust hybrid data structure would live on RAM and DISK. In the event of a power outage, your RAM will data disappear, but your DISK data will endure.
We use RAM for the sake of performance, it is after all, faster than DISK, however Eggert assures that the Disk is what actually "counts".
I. Commit Records: "Simon Says" approach
- Write out new content of a file to blocks 1000-1999 (old content in 0-999)
- While writing, we write a commit record to block 2000 (or some other well known specified block) [ old | new |commit rec. | ] (0 for old, 1 for new)
- Now we copy the new file to the old
- Clear commit record
Assume atomicity for commit record block. By convention, this makes all of the previous steps "atomic".
Pattern for implementing all or nothing operations:
BEGIN
precommit phase: Can back out leaving no trace to caller
ABORT*/COMMIT ( atomic at lower level)
postcommit phase: Can't backout but can do housekeeping or tuning for performance
END
The idea behind this pattern is that it looks atomic at a higher level. You can use this for rename operations for example
II. Journaling: "don't copy the whole file, just record change you intend to make to the file system"
Ex. Change block 498 to read -> [498|ABC 98 ---]]
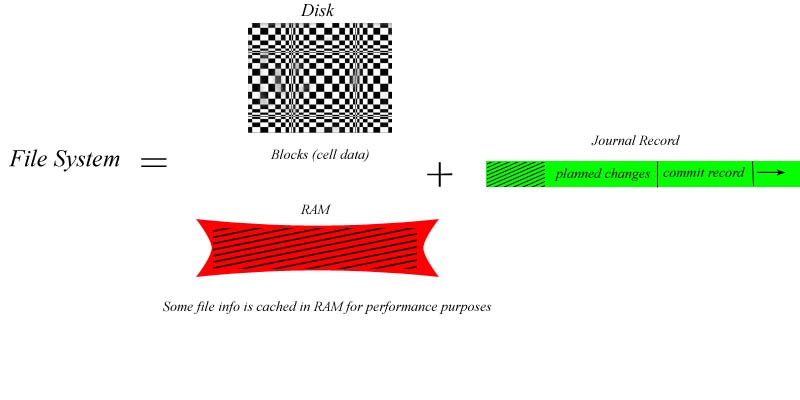
The journal is relatively small part of file system.
How does Journalling work in the event of a power failure? When you reboot, scan the journal & replay commit records that haven't been enacted.PROBLEM: Won't this take a long time on reboot?
Method of Attack:
1. You can update journal to signal that a commited action has been completed/ended. Then on reboot, scan through the journal backwards searching for unended actions, then replay those unended actions forward (think rewind and play forward like a video).This will allow you to find all those unfinished actions quickly and only enter them.
PROBLEM: What if we lose power during reboot?
Not a problem if recovery is idempotent*.
Methods of Attack
1. ABORT (must treat differently than commit on power failure so as to not replay the commit record)
Performance Issues of Journaling: 2 writes + a seek instead of one write
Methods of Attack:
1. cache like crazy, keep disk arm over journal, and
only write in cell data when system becomes idle.This will minimize the amount of writes and the time it takes for the arm to move to the correct position relative to the disk. Also allows work to be done as writes will only be complete when they system is idle.
2. Put the journal on a different device.
Now each device is written to once, as opposed to twice. Elegant, but that means you need two devices not one.
3. Don't store cell data on disk, store journal only.
Write to journal, writes become fast no seeks involved. Professor's whimsical idea, maybe if you suggest it as a solution on a final question you'll get more points for your audacity.
Professor's Tangent - disks are slow, so we can use main memory databases... that are networked ....they are lightning fast because of RAM, safe because of the redundancy of hosts in network.
PROBLEM: Journal Overflow
Methods of Attack:
1. Handle with circular buffer / JournalCan't overflow if we are just overwriting old data at the beginning of the buffer, now can we?
2. Make it plenty bigJournals take up small space on disk, so it can't hurt to allocate an overly large Journal. Remember that whatever size you allocate, it will always be 'wrong', at least in the optimizational sense.
3. Writes stall until journal's empty.Simple solution.
WRITE-AHEAD LOGS
- log all planned new values
- commit
- install new values into cell data
WRITE BEHIND LOGS
- log old values
- install new values
- commit
Roll Forward Recovery (for write ahead logs)
Roll Recovery (for write behind only)
More on Performance:
general ideas (read, want them to go fast )
app says:pread(fd,buf,size,location,in file);
//Suppose we use RT-11 filesystem. Thus contiguous files -pread (fd,buf,size,L1),
pread (fd,buf,size,L2);
pread (fd,buf,size,L3);
//The O.S. could do this ( on the low level)lseek(disk, L1 + file_start); //8.9ms rotation of disk
read(disk->buf,buf_size); //8.33ms latency
lseek(disk, L2 + file_start);
read(...) // 0ms read
//Total 17.23ms
PROBLEM: How do you make this faster?Methods of Attack
1. Rewrite all your apps to know about disk geometry. We could read the whole track on a disk.
Horrific idea to expect programmers to write apps to do this themselves. We're too lazy.
2. Cache a track at a time, this is called prefetching. Grab data ahead of time in expectation that the application/user will need it later.
A better idea
SPECULATION: Guess on what the next reads will read and then read the data before being asked (done in background).
BATCHING: Ask for big things at the low level, despite the application asking for little things ( this minimizes low level overhead). Batching works for writes, often done at many levels of abstraction.
API Level SYSCALL level Comments putchar(x) write(1,&x,1) this is not actually done 512 putchars write(1,&x,512) this is what it actually does (very fast) fflush(stdout) fsync(1) ensure a fd of 1, ensures everything was written to disk. This is slow getchar() read(0,buf,8192) speculation and prefetching getchar() would be called 8192 times read would be called 1 time.
Suppose you're doing a read getchar() -> read( ......... )
( wait for disk )
( schedule something )
( else...)MULTITASKING: ( You always should have one thing to do )
Seagate Terabyte Disc
1.296 Gb/s max internal transfer rate for read
.93 Gb/s max sustained transfer rate for read
----------
3.0 Gb/s max external transfer rate1.2 million hours mean MTBF
0.73 % Annualize Failure rate ( 24x7 )
10^-15 non recoverable sector read failure rateHow many sectors are in this Harddrive?
*abort
Airline website precommits that you will buy a ticket and then when abort occurs, returns and deletes the account
of the airline ticket purchase
* idempotent
1. A function f : D -> D is idempotent if
f (f x) = f x for all x in D.
I.e. repeated applications have the same effect as one. This can be extended to functions of more than one argument, e.g. Boolean & has x & x = x. Any value in the image of an idempotent function is a fixed point of the function.
2. This term can be used to describe C header files, which contain common definitions and declarations to be included by several source files. If a header file is ever included twice during the same compilation (perhaps due to nested #include files), compilation errors can result unless the header file has protected itself against multiple inclusion; a header file so protected is said to be idempotent.
3. The term can also be used to describe an initialisation subroutine that is arranged to perform some critical action exactly once, even if the routine is called several times.
[ Jargon File]
(1995-01-11)