CS111 Scribe Notes Lecture 12
Jinah Jung, Yoo Jin Lim, Shuyin Lu
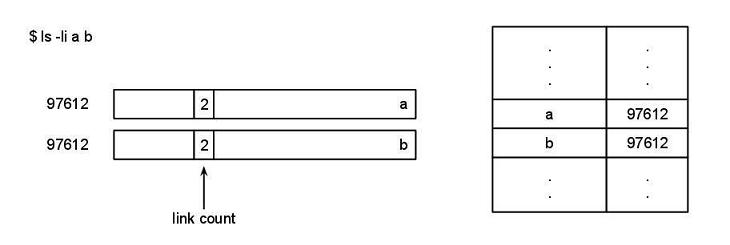
link(“a”, “b”);
unlink(“a”); // Now, a and b are two directories pointing to the same file
File System:
What can go wrong with this nice little idea? How can you get into trouble with pointers and data structures in general?
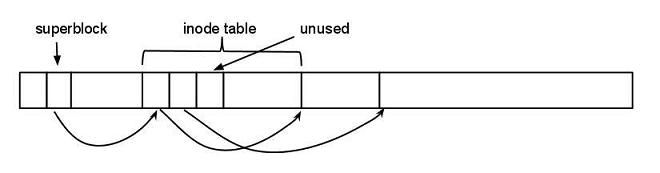
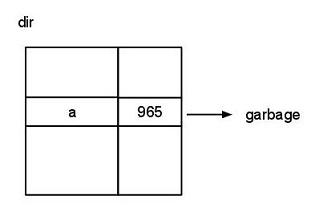
Problem: Dangling pointers exist. If you had a directory and a name, you look in the directory with an inode number, but there is no file with that inode number. Then it’s going to read garbage. What does it mean by “garbage”? There’s the partition of memory blocks, and somewhere in here is the inode table, in which each entry indicates a file. Some of these entries are free and unused, which are marked with a special value, “Hey, I’m not used.” Therefore, garbage means pointing to 1) an unused entry, OR 2) a value out of range (a negative inode number)
Solution: All the operations that we give to the user for things like link, unlink, open(“a”, O_CREAT|…) should not be able to create a directory entry with garbage. If the system call was supplied to let the user specify the inode number, we’d be toast; garbage can be created. We have system calls, and it is the only way to manipulate these objects. System calls don’t let you specify garbage and get into trouble.
Conclusion: Dangling pointers to garbage are a disaster. When the inode number is used later on, its behavior is unpredictable. This problem may be solved in another way, if you modify the on-disk structure to be a linked list of inodes. However, this problem is not important enough to complicate the design structure. The designers of the UNIX OS decided to let users deal with that, since it’s too complicated.
Suppose we want to create a new system call called destroy(97612), destroying the file with that inode number.
Problem: It’s ambiguous which directory entry to destroy, since you can have multiple directory entries with the same inode number.
Possible solution: Remove all the files with the same inode number
Motivation: Suppose that we have a huge file that’s taking up all the disk space. We’re going to remove this file, so we call unlink. But the disk is still full, because there are other links to that file. Wouldn’t it be nice to have a system call that destroys all? Destroy will trash the file, remove it, remove all directory entries that point to the file, unlink everything.
Problem: There is no practical way for the operating system to keep track of where all the links are. The only way to find out is to start from root directory and traverse all until the link count is zero.
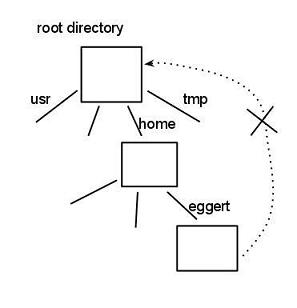
In addition to dangling pointers, what else can go wrong with data structures and pointers? What causes no end of trouble with pointers and complicated data structures? A correctness issue arises from the fact that the file system structure is a tree. Unrestricted pointers can create a cycle or a DAG (direct acyclic graph). Example diagram:
mkdir a
touch a/b
ln a c // this is the trouble! Not allowed to have hard links to directories.
// Create a directory: two names with the same dir.
ln . a/d // same reason. Not allowed. We do not want a complicated graph.
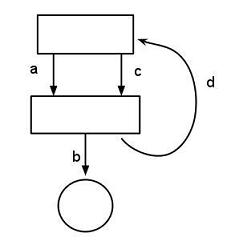
Cat a/d/a/d/a/d/b
With a cycle, when you do a backup, it will never finish.
find –name b // This will never terminate.
// “find” will traverse through the paths in a loop
// a/b
// a/d/a/b
// a/d/a/d/a/b
SYMBOLIC LINK
Motivation: Creating hard link to directory is not allowed in Linux. Linux model tries to keep simple. Of course, the restriction of having a directory hierarchy to be a tree is an issue. To deal with the issue, we have symbolic links.
What are Symbolic links? How do they work?
We have talked about two types of files so far: 1) Regular files are blocks of data on disk. 2) Directories are protected sorts of files that can be retrieved only with links.
And now we have symbolic links: Symbolic links are like regular files with content, but their contents are simply the name of another file. Implementation of symbolic links can be like that of a regular file, a data block, but it has a special marker so the OS can treat them differently. The OS pretends that symbolic links are not there and instead substitute another file’s name.
Most system calls follow the links.
Ln -s /usr/bin /bin // (creating a symlink from /bin to /usr/bin.
// Contents of the link are then the location of link itself.
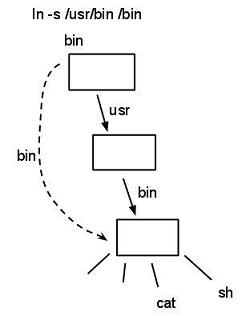
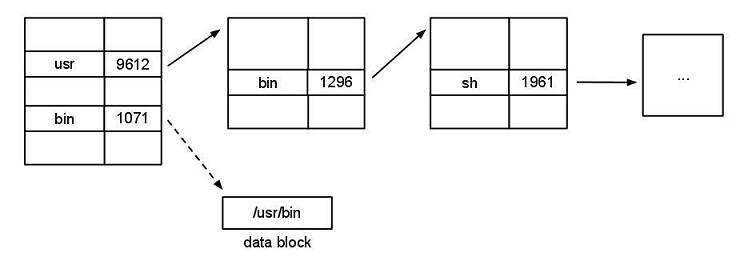
Symbolic link is created at root level with a link to bin down the tree. How symbolic link works: At the root, usr inode #9612 is pointing to bin and inode #1296 is pointing at sh. Bin inode #1071 is pointing at the data block /usr/bin. The OS sees the value of the symbolic link and keeps going. The os will mentally substitutes /usr/bin/sh and interpret that file instead of the original “/bin/sh”. This is a textual substitution, rather than having two pointers point to the same file.
Dangling symbolic link is not a disaster. Suppose you get rid of /usr/bin (don’t do it, you will lose all commands): the disk is still consistent and everything still works. It will simply generate error message “file not found.” The idea of rewriting names can occur multiple times. Resolving a name means performing symbolic link substitution until getting a name that doesn’t involve symbolic link. Multiple symbolic link resolutions slow things down. To eliminate this efficiency issue, don’t use too many symbolic links. Convenience is important.
Can we create a loop with symbolic link? Yes
Ln -s .. parent (parent to parent directory)
Parent has been programmed not to follow symbolic link.
Try this:
Ln -s a b
Ln -s b a
Cat a // open(a fails) with ELOOP
This will cause the kernel to go into infinite loop. For this problem, the designers of the UNIX OS put in an arbitrary limit of 20, number of times this can happen. This will catch all infinite loops. 20 is a random but good enough number. Note that loops do not happen with hard links.
What’s the problem with symbolic link?
Problem 1: Symbolic link was involved in the tar exploit problem mentioned in lecture 2. While traversing deep enough to structures to follow symbolic links, you may be opening files that you don’t intend to.
Example problem: Think about “find”
Find / -print
// While this is running, we do sort of mv /usr /usr.back
// Rename usr so it gets a different name
ln -s /victim /usr
// While this is running, it will look at names like /usr and /usr/bin and /usr/bin/sh. This will be /victim/bin/sh when things happen while looking at /usr/bin and /usr/bin/sh.
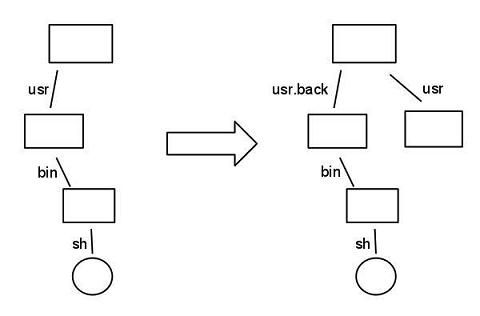
This problem can be solved by using permission, but this sort of attack can happen at any level.
Solution 1: One way is to add more system calls. System calls we have so far are not enough. Take all system calls that involve file names and modify them to let us specify directories that files point to:
open(filename, O_RDONLY, …) -> openat( fd, filename, O_RDONLY, ..)
unlink -> unlinkat(fd, “a”)
link -> linkat(…)
Rather than just opening, openat will traverse the file system hierarchy, to find and open the directory and use that directory’s file descriptor. Even if the directory is renamed, you’ll still be talking to the directory that you found originally.
Problem 2.1: Race condition.
While looking in “.” for directory entries X, Y, Z, use system call stat(X) to see if X is a subdirectory. And then stat(Y) and stat(Z). If it is a subdirectory, it recourses. stat follows symbolic link.
Solution 2.1: In order to avoid that problem, we use lstat. It doesn’t follow symbolic link.
Problem 2.2: Between lstat(Y) and then we open “Y”, they sneak in symbolic link.
Solution 2.2: To avoid that problem: open has another flag called O_DIRECTORY, which opens the file only if it’s a directory. Another useful flag is O_NOFOLLOW, which opens the file while ensuring that it does not follow any symbolic link. find has been rewritten to contain those two flags to prevent race conditions there.
Other Questions about Symbolic Links:
-Would it have been better to not have symbolic link at all?
An ideal solution to eliminating race conditions in symbolic link would be a system call that takes a snapshot of the file at each moment. We would want files work on snapshots of data and determine when we don’t want to deal with any change since a certain snapshot of data. The problem is that taking a snapshot of the file would be an expensive operation.
-Can you have hard links to symbolic link?
Yes, it’s allowed.
ln -s a b // symlink b -> a
ln b c //976 inode says I’m a symbolic link and my value is “a”
ls –li
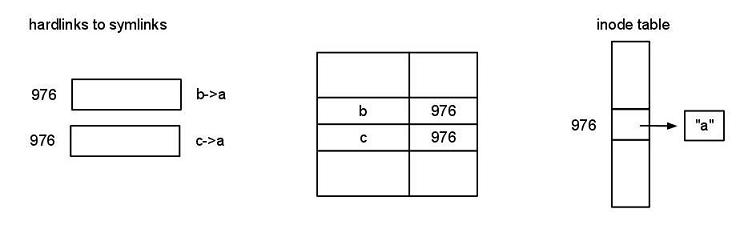
-Should symbolic links have owners?
Yes, a symbolic link is an inode entry, which means it has information on the owner, timestamp, and etc. We must consider if there is any value to having an owner for symbolic links. Permission for write to the symbolic link does not matter because you are not allowed write to symbolic link in the first place. Permissions for read and execute, on the other hand, make sense. Permission will allow seeing what the symbolic link contents are. Overall, these properties of ownership for symbolic link are still considered marginal.
However, disk quota and ownership of symbolic link matter, because symbolic links take up disk space. If everyone used symbolic link to get access to different files, it will chew up the disk space.
-Can you put any character in a symbolic link?
You cannot put a NULL byte in a symbolic link, because the system call symlink(“a” “b”) that creates symbolic link gets passed as string, which are null-terminated.
FILE NAME RESOLUTION
Every time you call open, file name resolution occurs. Look at the first byte: if it is the character ‘/’, start at the root directory. Otherwise, start at the working directory. Then walk through left to right, looking for file name components, and resolve each component by consulting directories. If the result of looking up the directory entry gives you a symbolic link, you splice the contents of that symbolic link into the name, then recurse. Resolve it relevant to the working directory, or the directory symbolic link is in?? Answer = resolve it relative to the directory symbolic link is in, otherwise you’ll go nuts!
There are two system calls that will affect how this works:
chdir (“foo”) – change working directory
chroot(“bar”) – why isn’t this as popular? Because once you changed your root, you can’t go back! -> “chrooted jail”. Thus, you can only run “chroot” if you are root.
File System Robustness Goals
Motivation: So far we have worked under the assumption that kernel is always right and users make mistakes. However, that is not always the case, so we need our file system to be robust.
Performance – high throughput, low latency
Durability – survive limited failures in underlying system (often hardware)
Atomicity – actions should either be done or not done
When we survive, if we were in the middle of an operation, we want that data to be consistent with what was happening before/after the operation was done. If I issue a write system call write(fd, “abc”, 3), I want either the write to fail, or succeed with all 3 bytes there, not something halfway.
In practice, we can’t achieve all of these goals. List of possible failures -> we must state our assumptions
With that in mind, let’s try to do a very simple operation. Simple text editor, press the save button. It saves a copy of what’s in RAM to disk. In general, we’re going to have to do several writes. The system could crash in the middle. Assume the power can fail at any time. We’re going to have limited assumptions of failures. The workaround here is that you don’t overwrite the original data. Golden rule of atomicity = never overwrite your only copy of the data, because you can crash. So the solution here is you write to a copy. Create a new file, save to “f,” create a new file “t,” write to “t,” copy t to f. If we crash while writing to t, it’s okay. If we crash while writing to f, we’re still okay. The problem with this approach is: How do you know which file? Put timestamp inside the file. “I’m done.” We need a little record of whether we have committed the new version or not. It will tell us to use old or new one. We need a commit record. Suppose the commit record is a gigabyte long – but the system can crash right in the middle of writing it. We need to assume it’s either written out, or it’s not written out, that the file is small enough to do that. We assume atomicity of a 1-record write.
Suppose we are paranoid and don’t trust these writes. Let’s change our assumptions: instead, no atomicity in writes, except: write y to a block that has old contents x.
[X | ???? | Y]
![[X | ???? | Y]](notes12_html_9bcf206.jpg)
can we implement an atomic write on top of this weak assumption? Sure we can, we just make multiple copies.
Two copies: Write Y to 1, write Y to 2
X?YY
XX?Y
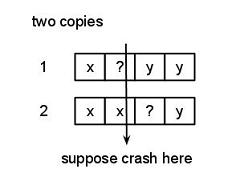
So you’ve followed the golden rule, but there’s still something wrong with that. Suppose you crashed in the middle of the second block, you don’t know which of the two blocks are right! This is the commit record, we can’t appeal to some other commit record to save us here -> We haven’t solved the problem. You can solve the problem with a third block: Write Y to 1, Write Y to 2, Write Y to 3:
X?YYY
XX?YY
XXX?Y
After reboot, which do we compare? It can crash anywhere, how can we tell who’s right?
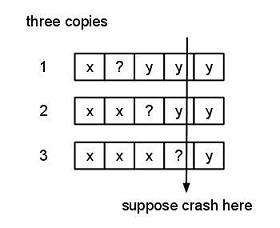
if (c(1) == c(2)) write it to 3, use that
else assume 3 is right, write c(3) to 1 & 2, use that
Lampson- Sturgis assumptions
Writes can fail,
Blocks can spontaneously decay
Reads can detect bad blocks
By putting error codes on the disk
Errors are rare
You have similar problems with commit record, but makes life easier. Now you’ll know that it’s a question mark. You can simplify the commit record to use only 2 copies instead of three.
In a sense, we are worse off than before, because blocks can spontaneously decay! What does this mean for file sys implementation? Every piece of data might go bad, so you’re going to have to have 2 copies of everything, not just of commit records. That’s bad, but there it is.
RENAMING FILES
rename( “a”, “b”)
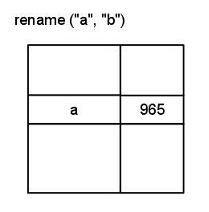
rename occurs in the following procedure:
Take a current working directory, in which a’s inode # can be found.
Read the directory block, assuming that the entire directory fits in one block.
In main memory, modify A to B .
Write to directory block.
Power fail assumption: We have atomic writes of block.
If power fails while writing a 8kb, it’s going to be fine: Write can finish because of capacitance of power. Thus rename either works or doesn’t work. It’s as if rename is atomic.
On the other hand, consider rename(“a” , “BBBBBBBBBBBB”). Since directory entry varies in length, it can be longer. As long as the entry fits into block, rename remains atomic. Now, suppose we need 2 blocks to write a long series of BBBBB. That will require a write to directory block 1 and a write to directory block 2.
rename(“d1/a”, “d2/b”) occurs in the following procedure:
Read d1’s block into ram
Read d2’s block into ram
Modify the main memory copy
We have to write d1’s data, (sys crash here -> file’s gone. No pointer to ??)
Write d2’s data.
How to improve algorithm for dealing with a rename :
Switch the order: Write d2’s data – crash – write d1’s data. You see two hard links to the same file and it’s link count is 1. When you remove one of those hard links, you’ll get a dangling directory. So how can we fix this problem? Complicate our algorithm by reading A’s inode into RAM. Before we write d2’s data, we write A’s inode entry out to disk with the link count 1 greater than it was before, then we write d2’s, then d1’s data, rewrite A’s data with link count back to the way it was before. If we crash here, the link count will be 2, so it’s alright. This approach has a drawback: files with wrong link counts, but at least it will be too high, you’ll have garbage data -> leaking data, but not crashing.
Correctness invariants for UNIX-style F.S. (e.g. speed limit )
every block should be used for one purpose: data, indirect, bitmap, inode, superblock, bool block
if a block is reachable, it should contain initialized data
all reachable data blocks are marked as used in a bitmap
all unreachable data blocks are marked as free
What’s the consequence of violating property 1? -> using a block for 2 purposes at the same time -> you lose data
Violate property 2? -> allocating data twice -> you lose data
Property 3 -> disaster strikes again!
4 -> data leak, disk space leak -> It’s not so bad!