COM SCI 111 Scribe Notes
Lecture 12: File System Implementation
By Yijie Wang and Justin WongContents
2 Hard Links
2.2 Example Problem: Freeing Disk Space
2.3 Example Problem: Linking to Directories
3.2 Example Problem: Exploiting Race Conditions
3.3 Hard Linking to Symbolic Links
3.4 File Name Resolution
1 Foreword
This lecture was presented as a series of example problems and solutions that may arise when implementing file systems.2 Hard Links
We begin with an example that demonstrates the basic functionality of hard links in a file system.Suppose we are given a file "a" that corresponds to file inode number 97612. Then, we execute the code shown in Listing 1.
link("a", "b");
Listing 1. A new file "b" is created that hard links to the same file inode of "a".
As a result, both "a" and "b" are directory entries that correspond to the same file inode as shown in Listing 2 and Figure 1.
$ ls -li a b
97612 ... 2 ... a
97612 ... 2 ... b
Listing 2. The first column indicates the file inode number while the second column (the two's) indicate the number of hard links to the file.
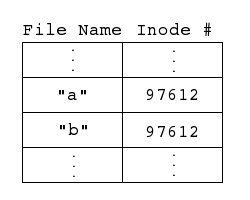
Figure 1. Directory entires "a" and "b" with their corresponding file inode numbers.
Notice from both Listing 2 and Figure 1 that there is no way to differentiate between files "a" and "b" other than by name because both point to the same file inode. In other words, the operating system has no idea which file was the original file! This is an important property of hard links.Now, if we wanted to remove the original file "a", we would normally unlink it by executing the code shown in Listing 3.
unlink("a");
Listing 3. Remove a file by unlinking it.
This code decrements the target file inode's hard link count, and sets the inode number of directory entry "a" to zero, effectively freeing it. However, because we created another hard link "b" to file inode 97612, the file will still exist as shown in Listing 4.
$ ls -li a b
ls: cannot access a: No such file or directory
97612 ... 1 ... b
Listing 4. File inode 97612 still exists, but only shows one hard link now.
The following are some example problems (and their corresponding solutions) that should be taken into consideration when implementing hard links for a file system:2.1 Example Problem: Linking to Garbage
Reexamine Listing 1 and notice that we specified a file name to hard link rather than a file inode number. What if we could hard link to specific inode numbers (e.g. int link(uint32_t inodeno, const char *newpath))?Problem: We could hard link to garbage!
If we could execute the code in Listing 5, then we could hard link to any arbitrary inode that may or may not point to useful data.
link(12345, "b");
Listing 5. Hard linking to a specified inode number.
This could result in undefined behavior as shown in Figure 2.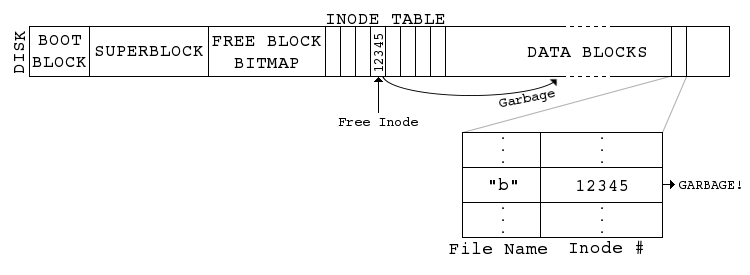
Figure 2. Hard linking to a free inode that still points to its original data blocks; hard link "b" points to garbage!
Solution: The system call implementations for hard linking do not allow you to specify garbage (inode numbers)! You must hard link by filename (e.g. int link(const char *oldpath, const char *newpath)).2.2 Example Problem: Freeing Disk Space
We want to free up disk space by removing a file that has multiple hard links.Proposed Solution: Use a system call that destroys all directory entries associated with a specified inode number (e.g. int destroy(uint32_t inodeno)).
Problem with this Solution: There is no efficient way to implement such a system call. The operating system would have to step through the disk looking for all entries that point to the specified inode number. This is overly complicated and slow. As a result, the UNIX file system designers decided to leave it up to the user to remove all the hard links when deleleting a file.
What if we want to free disk space by deleting a large file, but the file has too many hard links to find?
Solution: We cannot use a destroy system call, as explained above, but we can use a different one instead: int ftruncate(int fd, off_t length). While this system call does not allow you to remove any file (since you must still remove all of the corresponding hard links), it allows you to reduce a file's disk space to zero bytes effectively freeing up disk space!
2.3 Example Problem: Linking to Directories
As mentioned earlier, the operating system cannot differentiate between different hard links to the same file inode. This problem is clearly demonstrated if we execute the following shell script in Listing 6:1 #!/bin/bash 2 3 mkdir a # Create directory 'a' 4 touch a/b # Create file 'b' in 'a' 5 ln a c # Hard link 'c' to 'a' 6 ln . a/d # Hard link 'a/d' to '.'
Listing 6. Create a cyclical graph directory hierarchy.
This will setup the directory hierarchy shown in Figure 3.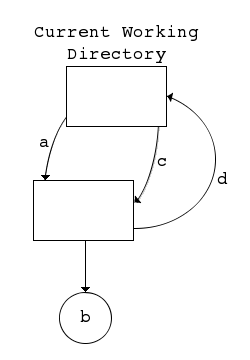
Figure 3. Cyclically hard linked directories.
We can correctly traverse this directory hierarchy as shown in Listing 7.
$ cat a/d/a/d/a/d/a/b
[[This works!]]
Listing 7. Traversing a cyclical graph directory hierarchy.
Problem: Backing up the hard drive will never finish because of the cycles!This cycle problem is easily demonstrated by running the find shell command as shown in Listing 8.
$ find . -name b
a/b
a/d/a/b
a/d/a/d/a/b
...
[[Which one is the operating system supposed to display?]]
Listing 8. Infinitely traversing a cyclical graph directory hierarchy.
Solution: Cache the directory hierarchy in RAM to prevent cyclical directory searching.Problem with this Solution: Caching the directory hierarchy in RAM defeats the purpose of placing things on disk in the first place!
UNIX Solution: Do not allow hard links to directories. Require a tree structure directory hierarchy, or a DAG (Directed Acyclic Graph). Thus, lines 5 and 6 of Listing 6 would not be allowed in a UNIX file system.
Berkeley Solution: Same as the UNIX solution, but allow symbolic links to link to directories.
3 Symbolic Links
The modern UNIX file system contains regular files, directories, and symbolic links:- Regular files and directories are represented by inodes that point to data blocks. These data blocks store file data for files and directory entries for directories.
-
Symbolic links, however, only need to record the
name of the file or directory that they are
linking to. Thus, a symbolic link can be represented by an inode that
points to a data block containing the name of the target file or directory.
Note: Lab 3 used a special symbolic link inode to represent symbolic links. These links are called fast symbolic links because their inodes store the target name directly in the inode instead of having data block pointers.
One of the key differences between symbolic links and hard links is the way that they are followed. Since symbolic links only contain the name of the target file, they are followed via textual substitution (this is elaborated on in Section 3.4). Hard links are essentially additional directory entries that possess the same inode number as the original file.
Thus, we can now solve the example problem in Section 2.3 by reprogramming the find program not to follow symbolic links.
3.1 Example Problem: Setting Up a Cyclical Hierarchy
Symbolic links can link to other symbolic links.Since they are followed via textual substitution, it is possible to set up a cyclical hierarchy as demonstrated by the shell script in Listing 9.
1 #!/bin/bash 2 3 ln -s a b # Symbolically link "b" to name "a" 4 ln -s b a # Symbolically link "a" to name "b" 5 cat a # Print the contents of "a" to stdout
Listing 9. Creating a cyclical graph hierarchy with symbolic links.
Problem: A cyclical hierarchy set up by symbolic links will infinitely loop!Solution: Set an arbitrary limit for the number of symbolic links that the operating system will follow, and have the system return an error if this limit is reached.
3.2 Example Problem: Exploiting Race Conditions
First, we execute the shell command shown in Listing 10.
$ find / -print
Listing 10. Using find to print the contents of the entire disk.
While find is running, we execute the shell commands in Listing 11.$ mv /usr /usr.back $ ln -s /victim /usr
Listing 11. Exploiting race conditions to trick find into printing the contents of another directory.
Problem: find will follow the symbolic link into the targeted directory!Solution: Add new system calls.
-
int open(const char *pathname, int flags,
mode_t mode)
We can rewrite find to use this extended version of the original open system call, and then set mode to O_NOFOLLOW | O_DIRECTORY. These two flags will configure open to fail on symbolic links and non-directories. -
int openat(int dirfd, const char *pathname, int flags,
mode_t mode)
We can use this system call to open files relative to the current working directory, or the directory specified by the file descriptor dirfd. -
int unlinkat(int dirfd, const char *pathname, int
flags);
Similarly, we can use this system call to unlink files relative to the current working directory, or the directory specified by the file descriptor dirfd.
3.3 Hard Linking to Symbolic Links
You are allowed to symbolically link to hard links, and vice versa as proven in Listing 12 and Figure 4.$ ln -s a b $ ln b c
Listing 12. Creating a hard link to a symbolic link.
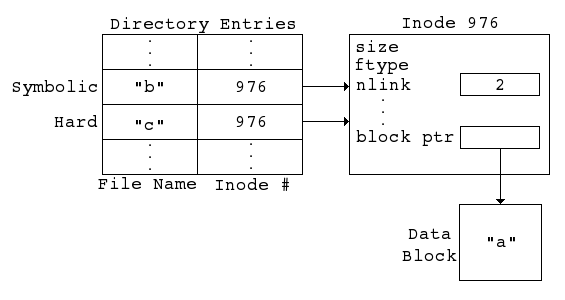
Figure 4. Graphical representation of a hard link to a symbolic link.
In Figure 4, the symbolic link's inode now has a hard link count of two. The result of Listing 4 is that both "b" and "c" are symbolic links to "a", and the operating system cannot determine which of the two was the original symbolic link to "a".3.4 File Name Resolution
To follow a symbolic link, the operating system performs the following algorithm on the target name stored in a symbolic link:- Examine the first byte: if it is a '/' character, then start from the root directory; otherwise, start from the current working directory.
- Walk through the name string from left-to-right. Look for filename components, and resolve each component by consulting its corresponding directory. When a symbolic link is encountered, resolve its target name instead.
open("a/b/c", ..., ...);
Listing 13. A sample open system call to define filename components.
In this string argument, the filename components are "a", "b", and "c". After determining the starting directory (either root or the current working directory) from Step 1, we can resolve each filename component by finding its corresponding directory entry, and then following that entry's inode number as described in Step 2.4 File System Robustness
Goals of a file system:- Performance: High throughput and low latency.
- Durability: The ability to survive failures that occur in the underlying system (hardware failure is common, so we want software to ensure data survival).
- Atomicity: Actions in a file system should either be done completely or not done at all. (e.g. write(fd, "abc", 3) should result in three bytes written, or none written).
4.1 Durability
File system durability is only achievable for a limited range of failures since it is impossible to defend against all failures. Thus, it is important to outline a list of possible failures, and state a set of assumptions based on this list.For example, we may want file system durability when saving from a text editor. Saving from a text editor involves writing RAM to disk, and several writes will most likely be needed. A possible failure assumption could be that the power can fail at any time. Thus, we would design our durability implementation based on this failure assumption.
Durability assumptions are further discussed in the atomicity section.
4.2 Atomicity
4.2.1 THE GOLDEN RULE OF ATOMICITY
Never overwrite part of your only copy.Solution: Always write to a copy!
4.2.2 COMMIT RECORDS
As described in Section 4.1, the process of writing RAM to disk can be interrupted by a power failure at any time. Thus, in order to have atomic writes in a file system, we need to use commit records.Assumption: Writing of the commit record is atomic.
Problem with this Assumption: Hard drive manufacturers cannot guarantee atomic writes of entire commit records.
Revised Assumption: Writing a very small piece of memory (less than the size of a commit record) is atomic.
We can use this revised assumption of tiny atomic writes to implement atomicity of full commit records. After achieving atomic commit records, we can build up to even larger scale atomic writes. This latter part is covered by a later lecture.
4.2.3 LAMPSON-STURGIS ASSUMPTIONS
The Lampson-Sturgis assumptions form a fault model that allows us to solve some of the commit record problems encountered in Section 4.2.2. The assumptions are as follows:- Writes can fail.
- Blocks can spontaneously decay.
- Reads can detect bad blocks.
- Errors are rare.
The downside is that this fault model assumes that blocks can spontaneously decay. Consequently, achieving complete file system durability would requires our file system to maintain two copies of everything (not just commit records).
4.2.4 CORRECTNESS INVARIANTS FOR THE UNIX FILE SYSTEM
-
Every block is used for exactly one purpose.
Consequence of Violation: DISASTER -
All reachable blocks are initialized (zeroed out).
Consequence of Violation: DISASTER -
All reachable data blocks are marked used in
the free block bitmap.
Consequence of Violation: DISASTER -
All unreachable data blocks are marked free
in the free block bitmap.
Consequence of Violation: Not so bad
Solution: Run fsck every N boots to free orphaned storage.