CS111: Lecture 10 Scribe Notes
Synchronization Primitives, Deadlock and File System Performance
By Haokun Luo, Xin Zhang, Xinheng Huang
1 Synchronization (Continued)
1.1 Semaphore
A blocking mutex, which allows up to N simultaneous locks. (We can find it in Java standard library!)
1.1.1 Why Do We Need Semaphore?
Let's consider the case of a 1G network interface. Suppose there are 5 zillion threads in total and each thread tries to access to the server. It's impossible for the server to satisfy every request from each thread right now. As a result, we need semaphore to manage the network traffic, and at most N lucky threads get the permission.
1.1.2 Simple Pseudocode
Suppose we have N initial slots. Here is the simple implement of Semaphore:
While (# of slots == 0)
Continue;
Run the thread;
# of slots --;
If we have N =1, then we have a standard blocking mutex (also called binary semaphore).
1.1.3 One Possible Implementation
The Data Structure:
Struct sema {
int slots;
process_t * waiting;
lock_t l ;
}
Two Operation Invented by Dijkstra (The "ijk" guy)
- Operation P: down acquire prolaag ( try and decrease # of slots)
- Operation V: up release verhoog ( try and increase # of slots)
Example on implment P and V:
function V(semaphore S):
Atomically increment S
S = S + 1;
function P(semaphore S):
repeat:
Between repetitions of the loop other processes may operate on the semaphore
if S > 0:
Atomically decrement S - note that S cannot become negative
S = S - 1;
break;
1.1.4 One Prototype of Semaphore
1 struct pipe{
2 bmutext_t m;
3 char buff[N];
4 size_t r, w;
5 }
6
7 void writeC ( struct pipe *p , char c){
8 for (;;){
9 acquire ( &p -> m);
10 if(&p->w - &p->r != m)
11 break;
12 release(&p->m);
13 }
14 &p->buff[&p->w ++ % N ] = c;
15 release (&p ->m );
16 }
- Problem:
This prototype may not work under the scenario that when tons of writers waits for a one lackadaisical reader, who always do nothing and not change &p->r. As a result, those writers never get chances to write and chew up all CPU time (CPU vampires).
- Solution:
We will not wake up on the queue until the object changes by changing line 9 – 11 as:
wait_for( &p->m, &p->w - &p->r != N );
- New Problem:
Because of the limitation of C language, functions are called by value. So ( &p->w – &p->r != N) will only return 0 or 1, then we will wait for 0 or 1 forever. What we really want is a lamda function (as in Scheme) which holds such condition.
- New Solution:
Condition Variable in Pipe structure:
Struct Pipe
{
...
condvar_t nonfull, nonempty;
}
What should we know about Conditional Variable:
- Conditional variable is conceptually a queue of thread upon which a thread may wait for some conditions to become true.
- We need a Boolean condition to define the variable.
- We use blocking mutex to protect the condition, which can't change from its critical section.
1.2 API for Condition Variable
Three important User functions:
-
wait ( condvar_t *c, bmutex_t *b );
-
notify( condvar_t *c );
-
broadcast( condvar_t *c );
Using the API of condition variable, we can rewrite our writeC():
1 void writeC ( struct pipe *p, char c ) {
2 acquire(&p->m);
3 while (&p->w - &p-> r == N )
4 wait(&p->nonfull, &p->m);
5 &p->buff [&p->w++% N] = c;
6 notify(&p->nonempty);
7 release(&p->m);
8 }
1.3 What can Go Wrong?
- Preconditions not respected: such as one process tries to unlock a non-spin lock, then other process cannot create spin locks any more. In this way, we want a debugging version of kernel library, which has large and more complicated locks.
- Deadlock: Two or more processes are waiting for each other to release their resources. Deadlock is a kind of race condition, and it is very hard to debug.
For example: we want to sort an array. In one process, it wants to pipe in the original array into the pipe. On the other one, it wants to pipe out the sorted array. If in both directions, pipe is full, and we never get the array in both processes.
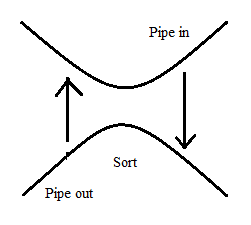
2 Deadlock
2.1 Condition for Deadlock
- Circular wait: Two or more processes form a circular chain where each process waits for a resource that the next process in the chain holds.
- Mutual exclusion: A resource that cannot be used by more than one process at a time.
- No preemption of locks: No resource can be forcibly removed from a process holding it. Resources can be released only by the explicit action of the process.
- Hold + wait: Processes already holding resources may request new resources.
2.2 Disciplines for Avoiding Deadlocks
- Acquire () checks at runtime for cycles, fails if it would create a cycle
Prons and Cons:
+ No deadlock
- Complicates API (acquire() and writeC() need to deal with system fail) + application error == EWOULDDEADLOCK
- Runtime cost 0 ( length of dependencies ) short in practice
-
Lock ordering
Suppose you need to acquire locks &l < &m < &n, grab (l) then grab (m) then grab (n), if any grab() fails, then release the lock.
Prons and Cons:
+ No deadlock
+ Better runtime cost
- strict about the order rules (Unfortunately, Linux kernel do not support this)
3 Priority Inversion
Priority inversion is a problematic scenario in scheduling when a high priority task is indirectly preempted by a medium priority task effectively "inverting" the relative priorities of the two tasks. This violates the priority model that high priority tasks can only be prevented from running by higher priority tasks and briefly by low priority tasks which will quickly complete their use of a resource shared by the high and low priority tasks. You can think it as locks + scheduling priorities, and it feels sort of like a deadlock.
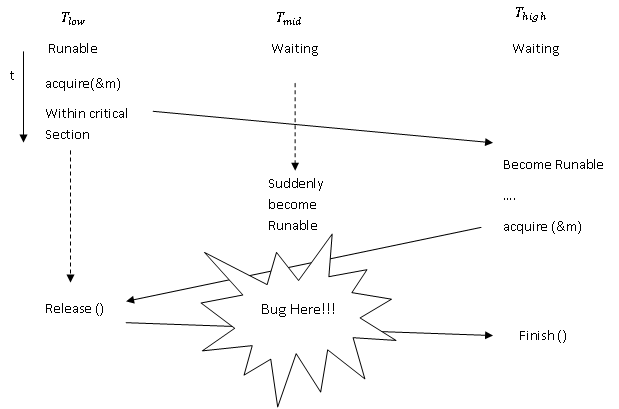
- Problem: When the high priority thread throws control back to low priority thread (maybe yield()), because the suddenly runable middle priority thread has higher priority than low priority thread, the middle one get the CPU control. Therefore, the high priority thread never gets finished.
- Solution: High priority waiters temporarily lend priority to lock owner.
4 Livelock
A livelock is similar to a deadlock, except that the states of the processes involved in the livelock constantly change with regard to one another, none progressing. In other words, nobody waits but no work gets done. A good example is when requests are sending at 100 Gb/s to a bounded buffer of unhandled requests, the CPU can only process the requests at 10 Gb/s. Thus, it will drop 90% of the request through interrupt handler. The problem comes when the buffer is full, and there are still lots of incoming requests to send interrupts to CPU, then the interrupt handler will chew up the CPU, and nothing will be done.
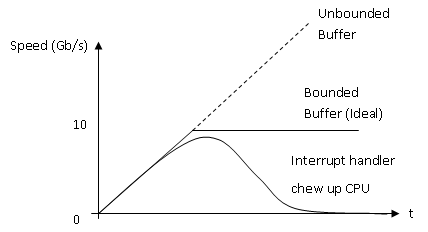 Solution:
Solution:
- Disable the interrupt when CPU is busy.
- Polling, namely no interrupt at all.
5 Event-driven Programming
Simple Pesudocode:
1 For(;;){
2 Wait for any event e;
3 Act on (e);
4
5
6 }
Prons and Cons:
+ no lock, no threads, no scheduling =gt; no deadlock, no race condition
- Difficult to extend to excessively complex application code.
6 File System Performance Issues
There are two types file system: disk and flash.
- Disk is large but slow
- Flash is fast small but expensive
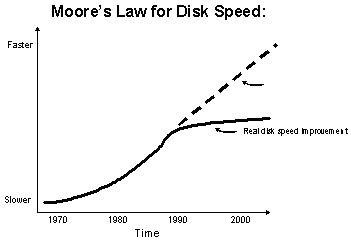
7 Components of Disk Latency
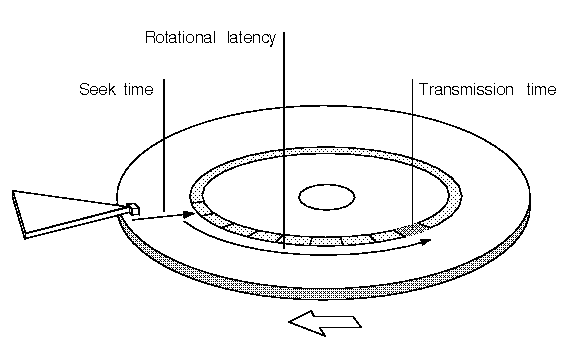
Two costs when reading random sector on a disk:
- Seek Time: wait for read head to get to the right track
Average seek time:
8.5 ms read
9.5 ms write
- Average rotational latency = 8.33 ms
Our Goal is to get all those numbers down!
