CS 111 Lecture 10: Synchronization Primitives and Deadlock
Scribe Notes for 10/28/2010
by Jason Tsao
1. Synchronization continued
A semaphore is a blocking mutex allowing up to N simultaneous locks
1. limited, but multiple resources
2. A resource is locked when slots == 0
available when slots > 0
where initially slots = N;
- If N = 1, we have a standard blocking mutex. Therefore, a blocking mutex is simply a binary semaphore.
Lets try implementing a semaphore in c:
struct sema
{
int slots;
process_t *waiting; // pointer to list of processes waiting for
// this semaphore
lock_t l; // spinlock
};
Dijkstra came up with these semantics:
P(sema) down: try to acquire a lock, reduce integer.
- P is short for prolaag
V(sema) up: release, done with lock, increment the integer
- V is short for verhoog
// Prolaag and verhoog mean try-and-decrease
struct pipe
{
bmutex_t m;
char buf[N];
size_t r,w;
condvar_t nonfull, nonempty; // just a condition variable
};
void writec(struct pipe *p, char c)
{
for(;;)
{
acquire(&p->n); // Note that “->” binds more closely than &
// Thus its the same as &(p->n)
if(p->w - p->r != N)
break;
release(&p->m);
}
p->buf[p->w ++ % N] = c;
release(&p->m);
}
// There is a problem with the earlier code having to do with
// multi-core. It will work, but it will chew up a lot of cpu time.
Here is the scenario in which it will fail:
1. Tons of writers <-- These will turn into CPU vampires!
2. One lackadaisical reader
We want:
void writec(struct pipe *p, char c)
{
for(;;)
{
wait_for(&p->m, p->w - p->r != N) // Problem is we can't do this
break; // in c because we can't wait
// for the argument to be false
// Problem 1: C processes call by value,
// Problem 2: We don't even have the lock
// It's false now and we want to wait for it to be true
release(&p->m);
}
p->buf[p->w ++ % N] = c;
release(&p->m);
}
Aside: GNU tar + Signals
There was a bug in GNU tar: signal handling was timing dependent.
read(fd, buf, sizeof buf);
For GNU, many utilities/commands broke because of someone adding a
signal_handler into the GNU tar code.
Question: If a signal goes off while a read is executing, should that be an error?
Answer: It depends on what the signal_handler does.
-1 with errno == EINTR
signal_handler fires
do stuff -> Will this stuff call syscalls that will affect my read?
return;
2. Condition variables:
We need:
1. a boolean condition defining the var
2. a blocking mutex protecting the condition
3. cond var itself
API:
wait(condvar_t *c, bmutex_t *b)
- releases b, blocks until some other thread notifies on c,
then reacquires b, then returns;
PRECONDITION:
- We hold b
notify(condvar *c) // Notify a thread
broadcast(condvar *c) // Notify all threads
Using condition variables the above code turns into:
void writec(struct pipe *p, char c)
{
acquire(&p->m)
while(p->w - p->r == N)
wait(&p->nonfull, &p->m); // We won't awake until the object changes
p->buf[p->w ++ % N] = c;
notify*&p->nonempty);
release(&p->m);
}
3. Synchronization gotchas
- If preconditions not respected:
- we need debugging versions of libraries with bigger locks
- parent process that sorts <-- suppose this parent is so big it can't fit into ram
- Therefore, it forks children and pipes:
parent process
| ^
V |
brzlfuz
- If we use brzlfuz, it can deadlock if both pipes are full
- If we use sort, we won't b/c sort doesn't generate any output until it has got all of its input
4. Deadlock
- This is a race condition
- 4 conditions for deadlock
1. circular wait
2. mutual exclusion
3. No preemption of locks
4. Hold + wait
- That is: need to be able to hold one resource while waiting
for another
- It's up to the coder to avoid deadlocks no matter how slow/fast the
system they are running on
Disciplines for avoiding deadlocks
1. acquire() checks @ runtime for cycles, fails if it would create a
cycle
(+) No deadlock
(-) Complicates API + apps errno == EWOULDDEADLOCK (new error_num)
- Acquire changed, it now returns a boolean saying if it failed/not
(-) Run-time cost: O(length of dependencies) <-- in practice, this is short
2. Lock ordering
Suppose you need to acquire locks l, m ,n where &l < &m < &n
acquire(&l) then grab(&m) then grab(&n) (without waiting)
acquire(&l) grab(&m) grab(&n)
^ ^ ^
| | - if fail, then loop to acquire |
|--------------------------------------------------------------<-V
- grab will fail if it can't acquire.
if fail
release
5. Priority Inversion
- For this to open, one needs locks + scheduling priorities
- Only requires one lock
- Suppose, we have 3 threads:
T_lo T_mid T_hi <== Threads
t |
i | runnable waiting waiting
m | lock(&l); (runnable)
e | runnable acquire(&m);
| | ^-------------------------------------------^
V | | (blocked)
| release() V
| I HAVE THE CPU
V
Problem: T_lo has the lock, and T_hi wants it. When T_lo has the lock, and T_hi tries to
acquire, it will be put to sleep. A problem occurs if T_mid becomes runnable right as T_lo
releases its lock since T_mid will receive the lock before T_hi, even though T_hi wanted to
acquire the lock first.
Solution: High priority waiters should lend their priorities
to the lock owners
- This is not deadlock, just feels like it
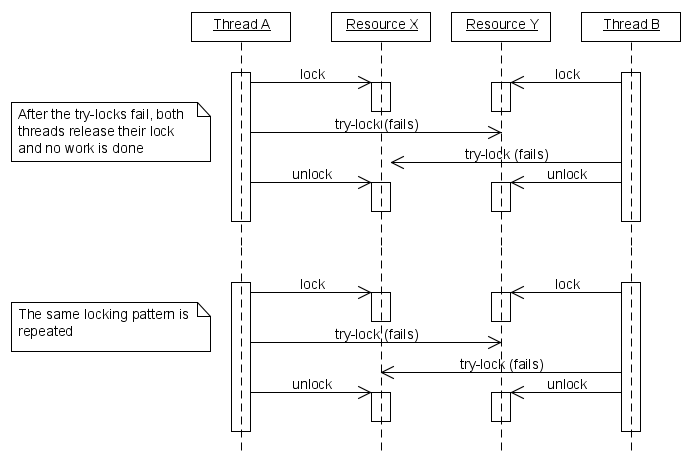
6. Livelock (nobody waits, but no work gets done!)
- Livelock is when several threads continue to run, but the entire system does not
make progress because it keeps on repeating patterns of resource try-locks and
failures.
Here is a diagram illustrating livelock from
http://www.paulbridger.com/files2/livelock.png:
bounded buffer
------- -----------------------
requests 100 Gb/s link-> | unhandled requests |
------- -----------------------
- interrupt handler
- CPU can process reads @ 10 Gb/s
When we receive livelock:
Handled 10 Gb/s requests/s
|
| ------------------------------ polling
CPU | /---
| / \ <-- interrupt handler has all the CPU!
| / \
| / \_ _ _ __ __ _ _
----------------------------------------
Requests/s
This graph shows how although polling takes up more cpu, but it gets more work done (in
the case that livelocking occurs).
Therefore, here are the solutions
1. disable interrupts when busy
2. polling
To take a more in-depth look, see http://www.stanford.edu/class/cs240/readings/mogul.pdf
7. Event-driven Programming (smaller apps)
- Has these key attributes:
1. No locks
2. No threads
3. No scheduling
4. No deadlocks
5. No races
The main program would basically run as follows:
for(;;)
{
wait for any event e;
act on (e) <-- must be fast, must not wait
// If you have a complex action, split it up.
// Each subaction sets up event handler for next
}
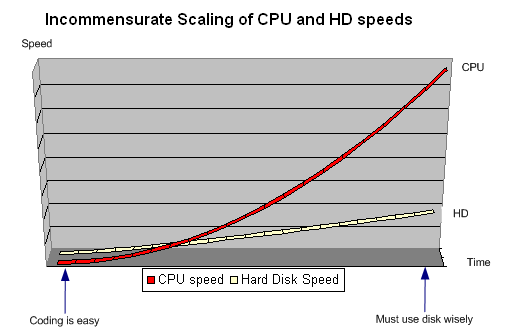
8. File Systems Performance issues
2 main storage devices:
1. disk - larger, cheaper/byte
2. flash - faster
CPU speed grew exponentially, while Hard disk speed increased linearly.
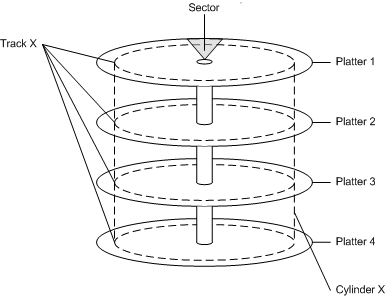
Hard Disk Layout:
Example: Seagate Barracuda ES2 1 Tb drive:
sector 512 bytes/4096 bytes
7200 rpm = 120 Hz
Components of disk latency:
To read a random sector:
1. wait for read head to get to right track seek time
// average 8.5 ms read
// Many OS’s require performance to be < 100 ms
// Write is normally 9.5 ms
2. Average rotational latency = 8.333 ms to do a full rotation
- this is slow