 Security (cont.)
Security (cont.)
Recall from last lecture, access right control requires P*R*M bits to store access control, which is difficult to administer and audit. Several improvements can be made to simplify access control.
- Traditional Unix: Reduce the
Principle axis to 3 items:
user, group and
others; and reduce the number of
access modes to read,
write and execute,
effectively making amount of information to manage
scales linearly with amount of resources only.

Note that in the original Unix model, each user can be in only 1 group. In BSD, each user can be in multiple groups.
- Access Control List (ACL):
Found in Windows NT, Solaris and Apache. The owner
of a resource can specify the list of
principles and their accesses. For example:
$ getfacl . # file: . # owner: truongd # group: csugrad baron::rwx khoale88::r-x user::rwx group::--x #effective:--x mask:rwx other:--x
Benefits: we can control the groups, but we don't have to include every principle in a resource.
ACL has one problem, though. Suppose I am root, inspecting the system. I cd inside a bad guy's directory, then do ls. If PATH contains ".", and that directory contains the bad guy's version of ls, we will be running bad code as root. Simply inspecting the system can be fatal.
- Role-based Access Control (RBAC):
The idea: Created as a solution to the problem with
ACL. It replace the Principle axis with Roles.
With RBAC, there's a table to assign roles for each
user, thus there are limited roles.
The downside of RBAC is that its implementation is complicated.
Mechanisms for enforcing access control:
- With ACL: each resource has an ACL (controlled by
the OS) attached to it. All accesses are mediated
by the OS, generally via syscalls.
- Capability-based: each principle has a "RCL"
(set of capability)
Difference from ACL-based: the access rights are attached to the principle instead of the resource. This can be accelerated by hardware.
From an OS point of view, it generally does not trust any appication, because it doesn't trust users, and applications run on behalf of users. Recall the whole purpose of interrupts and virtual memory.
However, some programs has to be trusted, for example, "login".
Implementation of login using a setuid() system call: change user ID of the current process. Only root can call setuid. This created a problem: normal user cannot call "login" to run a program as another user from the command line.
To solve this, we invented a 'setuid' bit, that the executable will run as the owner of the file instead of the current user. The software that is setuid'ed should be well-written! A rule of thumb is that we do not trust large software.
There is a problem: can we trust login?In the article Reflections on Trusting Trust by Ken Thompson, he proved that we cannot trust no one.
How do I trust login? Answer: suppose I am using RedHat linux and I trust RedHat. I get a checksum of "login" from RedHat. I compute the checksum of the vesion of "login" I have and make sure they match.
How does RedHat trust its "login"? Answer: It is a simple code. They read it through and make sure it is perfect.
Is that enough? What if login.c is ok, but gcc is corrupted and is producing buggy code? Answer: We read gcc.c code then recompile it.
What if gcc.c is ok, but your version of gcc binary is corrupted? Then you cannot even recompile gcc.
The moral is: you always have to trust someone.
Cloud Computing
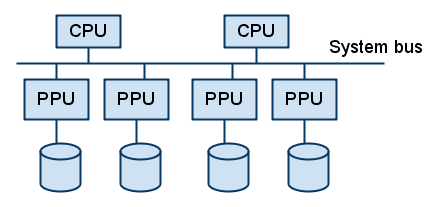
Mainframes are huge but tightly integrated computing systems.
Problem with mainframes of the time was to get data in and out of the disks. Most computation is data-intensive, like acounting/payroll processing, and thus data reliability is a big issue

Clusters, or grids, are systems of independent computers loosely typically connected over IP network. Computes in a grid replicates miniaturized mainframe computers, has its own OS, and can run different OS or different version of the same OS.
Advantage of a grid over a mainframe was the ease of administration and upgrading.
Disadvantage of a grid was that applications has to be aware of the network, and where resources are located, and has to manually open connection to other boxes to share computing task.
People have tried seamles clustering, using an OS to
abstract the hardware from the applications, so that apps
will see one unified memory space and file system
However, this complicates administration: you have to bring
down the whole cluster to update the OS, defeating the
purpose of a cluster.
A cloud is a network of clusters, connected over the internet. A cloud can be run by multiple organizations, possibly across borders, making huge computing resources available and manageable. A cloud user can assume unlimited shared resource.
From that assumption, a cloud has those advantages over a cluster:
- Short-term commitment: no huge capital investment up front
- One can start small and grow as needed. Also, scaling is simple and rapid
- Pay-as-you-go: better resource utilization when demand is unpredictable, or is flunctuating
- Reliability from a cloud's distributed nature
Disadvantages of cloud
- Cost: Cloud costs more money for the same computing power. For tasks that has known and stable load, cluster is a cheaper solution.
- Privacy/Data confidentiality: One need to trust the computing part of a cloud to use it. Due to its distributed nature, this can be difficult.
- Network latency
- Data transfer bottleneck within a cloud: can be disk or network. --> multi-level archiving and "sneaker net". Generally, this is an unsolved problem
- Bugs in application is costly. This creates a conservatism, making people reluctant to any change in the software. Also an unsolved problem
- Security: DoS is more likely and harder to defend against, although physical attacks are less severe
- Overloading risk: Infinite computing resource and
grow-as-needed is only an illusion. CPU or data
access can be overloaded when multiple user hitting
their peak at the same time

- Vendor lock-in: companies can make switching vendors costly once users used service from one vendor
- Software licensing:
Proprietary software with pay-per-machine license (like Windows) will nulify the benefit of rapid scaling up.
Also, GPL'ed software can be modified and ran by vendors within its own cloud without having to release source code, defeating purpose of the GPL.